《机器学习(西瓜书)》读书笔记:第三章_线性模型
线性模型虽说是机器学习中最简单的模型,但是还是有很多细小的知识点值得注意的。从去年这时候就开始接触机器学习,看过Ng在Coursera上的视频和斯坦福的cs229。这次看过西瓜书之后又加深了理解,于是赶紧趁热把思路整理出来。
一 线性回归
线性回归没什么好说的,它的思想是采用对输入样例各个特征进行线性加权的方式得到预测的输出,并将预测的输出和真实值的均方误差最小化。说白了如果输入样例只有一个特征,那这个过程就是用一条直线去拟合平面直角坐标系上的点;如果有两个特征,表现在平面直角坐标系上就是用一条直线将用不同标记(如XX和OO)区分的输入样例分割开来;如果有两个以上特征,那就会映射到高维空间,用超平面来分割。
书中提到了一个属性量化的问题,对于离散属性,如果属性是有序的话,如“大 中 小”,可按序量化为(1,0.5,0);若属性无序,如瓜的种类有西瓜、黄瓜、冬瓜,就可以用三维向量表示(1,0,0),(0,1,0),(0,0,1)。如果对于无序的属性按有序属性的方式量化,则会不恰当的引入序关系,后面如果有涉及距离的计算,有可能会造成误导。这里实际上对应的是编程实现时的数据预处理部分。
还有一点,就是关于凸函数的定义和判定,值得巩固一下。线性回归的目标函数是一个凸函数。一个闭区间上凸函数,必须在这个区间上满足“两点中点处函数值≤两点各自函数值和的一半”,而不要想当然的理解为形状朝一个方向“凸出”就是凸函数。比如,y=x²是凸函数,y=-x²就不是。从数学角度,可以通过二阶导数判断:若在区间上二阶导数非负,则称为凸函数;若二阶导数在区间上恒大于0,则称为严格凸函数。
线性回归的形式很简单,可以衍生出其他的一些模式,这时可能从线性映射变为非线性映射。如原来用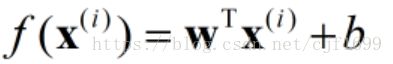 来近似真实值
来近似真实值 ,现在若用来近似
,现在若用来近似 ,就成了一个非线性模型,这叫做对数线性回归。更一般地,可以引出广义线性模型的定义,令
,就成了一个非线性模型,这叫做对数线性回归。更一般地,可以引出广义线性模型的定义,令

其中g为单调可微函数,称为“联系函数”。
二 对数几率回归
这里的“对数几率回归”就是常说的“逻辑回归”,只不过周老师认为汉语中的“逻辑”一词与英文原文“logistic”意义相差甚远,因此采用了另一种比较合理的意译方式。
引入对数几率回归的初衷是要解决分类问题,也就是数据的真实标记是有限的离散值的情况。对于二分类问题,输出空间是{0,1}集合,因此我们要把原来线性回归的输出值给映射到{0,1}集合上来,这是一个函数值域的变换过程,因此也就是一个函数映射过程。而提到线性回归的衍生变化,我们就想到了“广义线性模型”。最理想的情况是令g^-1为单位阶跃函数,即 值为正时,输出为+1,正类;值为负时,输出为0,负类;若正好为0,则正负类均可。
值为正时,输出为+1,正类;值为负时,输出为0,负类;若正好为0,则正负类均可。
可惜的是,单位阶跃函数并不可微。为了使用广义线性模型,我们就找到了sigmoid函数来替代了。sigmoid函数大家都很熟悉了,具有良好的数学性质。而叫做对数几率回归的原因,就是该模型经过变形整理后可以写成 的形式。若把y看作是预测为正例的概率,那么1-y就是预测为负类的概率,y/1-y就是一种“相对正类率”(将y,1-y理解成概率是很自然的,因为sigmoid函数的值域是(0,1))。所以,该模型使用线性回归的方式去逼近一种“对数几率”,因此叫做“对数几率回归”。模型中的w和b可以使用对数极大似然的方法求解。
的形式。若把y看作是预测为正例的概率,那么1-y就是预测为负类的概率,y/1-y就是一种“相对正类率”(将y,1-y理解成概率是很自然的,因为sigmoid函数的值域是(0,1))。所以,该模型使用线性回归的方式去逼近一种“对数几率”,因此叫做“对数几率回归”。模型中的w和b可以使用对数极大似然的方法求解。
三 线性判别分析(LDA)
这里只对其基本思想作一回顾。
寻找一条直线,将正例和反例的样本点分别投影到这条直线上,使得(1)同类样本的投影距离尽可能近;(2)不同类样本的投影距离尽可能远。
对于(1),可使同类样本的协方差尽可能小;对于(2),可使不同类样本的类中心距离尽可能大。从而构造出优化目标函数“广义瑞利商”。
四 多分类问题
很多二分类模型可以直接推广到多分类的情况,但是更多情形下,我们是利用二分类器解决多分类问题,这一过程涉及到对多分类任务进行拆分,以及对多分类器进行集成。本节主要介绍了拆分策略:OvO、OvR、MvM.
OvO,就是“一对一”。模型在训练时挑选一个类别作为正类,一个类别作为负类,共N个类别时,需要训练N(N-1)/2个分类器。测试阶段,将测试用例喂给每个分类器,在预测结果中选择出现频次最多的作为最终的结果,相当于“投票法”,谁的票数多谁就当选。这种方法的优点是训练时不必用到所有的输入样例,而只需两个类别的样例即可,这在训练集十分庞大时有一定优势。但是它需要训练N²量级个分类器,这导致存储和测试时间的开销比较大。
OvR,就是“一对其余”。模型在训练时挑选一个类别作为正类,其余类别全部作为负类,共N个类别时,需要训练N个分类器。测试阶段,将测试用例喂给每个分类器,这时输出情况有两种:(1)只有唯一一个分类器输出为正类,那么此类就是最终的预测结果;(2)有多个分类器输出为正类,则考虑预测置信度,选择预测置信度大的分类作为最终输出。这种方法由于每次要用到全部训练数据,因此训练时间开销较大。
MvM,就是“多对多”。模型在训练时挑选若干个类别作为正类,若干个类别作为负类。一种常用的MvM技术叫做ECOC(Error Correcting Output Code)纠错输出码。具体做法是,(编码过程)将N个类别划分M次,在训练集上训练出来M个分类器。也就是说这M次过程之后,每个类别都有一个长度为M的编码,要么0(被划为负类),要么1(被划为正类);(解码过程)将测试样例分别喂给这M个分类器,得到M个预测标记,组成长度为M的编码,依次计算此编码与每个类别编码的距离,距离最短的作为其类别。之所以叫做“纠错输出码”,是因为这种方法具有一定的容错性能。即使在解码过程中某个分类器出现了错误,依然能产生正确的分类结果。
五 类别不平衡问题
这一点记得在Ng的视频中没有重点讲解。所谓类别不平衡问题是指训练集内正类数目和负类数目相差悬殊,如正例有998个,而负例只有2个。这样一来一个将所有输入全部预测为正例的无脑分类器也会达到很高的分类准确率,但是却毫无意义。
针对这一问题,有3种解决办法。以下假设正例个数远远大于负例个数。
1. 欠采样。随机抛弃一些正例,使二者数目相当。
2. 过采样。增加一些负例,使二者数目相当。如通过对训练集中的负例进行插值法以产生额外的负例。
3. 阈值转移法。以对数几率回归为例,y/1-y可以看作一种预测几率,即正例可能性和负例可能性的比值。当此几率大于1时(y>0.5)就预测为正例,反之为负例。现在将m+/m-定义为观测几率,m+为训练集中正例数目,m-为负例数目。当训练集是真实样本的无偏估计时(很遗憾,这种情况并不容易达到),观测几率就代表了真实几率。
从而当y/1-y大于m+/m-时,我们再让分类判定为正例,这就是类别不平衡问题的一个基本策略:再缩放。
小结
线性模型看似简单,其实值得注意的内容还是挺多的。比如鸡尾酒会问题就是一个多分类问题,目前有很多基于机器学习的研究该问题的论文。读西瓜书有时会觉得不容易啃,这是因为很多地方涉及到了数学的推导。然而借助数学的高度,往往会带来更深刻的理解。