像Apache Storm一样简单的分布式图计算
原文:distributed-graph-computation-as-simple-as-it-gets-with-apache-storm
作者:Kobi Hikri
翻译:无阻我飞扬
摘要:本文从计算机领域的“祖师爷”艾伦·图灵提出的图灵机概念开始,介绍了图形计算的概念,并以示例介绍了apache storm,基于apache storm如何进行分布式图形计算。apache storm是一个免费开源的分布式实时计算系统,具有简单易用、快速、可扩展、容错等优点。以下是译文。
介绍
计算可能很复杂。对我们来说,这种复杂主要就是软件世界的人类驱动力。甚至有一个学科整个都围绕着问题解决和计算——计算机科学。
当一个人开始学习计算机科学时,会被介绍一些术语和概念,这些术语和概念都是围绕着试图以可证明,恰当的方式对问题的解决方案进行建模和表达而形成的。

艾伦·图灵
艾伦·图灵天才地提出了图灵机的概念。这些“机器”使我们能够以数学证明的方式恰如其分地描述解决方案,同样也适用于解决计算机科学领域遇到的问题。

图片由维基本科提供。
从那时起,围绕抽象计算机(包括图灵机)的整个研究发展起来,名为自动机理论的研究。
自动机理论的领域是广泛的,也是在不断增长和最流行的 — 因为它可以生成能够解决现实生活中问题的模型。
图片由维基本科提供。
在一定程度上,自动机理论与图论是密切相关的。
结合这两种理论的优点,我们能够设计出可证明的、分布式的、有效的解决问题的方案,否则这些问题将会太过于复杂,难以表达和解决。
在本文中,将介绍Apache Storm(从现在开始使用术语“Storm” – 通常是指Apache的Storm版本。storm中的spout译为“喷嘴”,bolt译为“螺栓”),作为分布式图形计算基础架构的实现。
接下来就开始吧!
图形计算作为降低系统复杂度的一种方式
在介绍了图灵机、自动机理论和图论之后,图形计算可以作为一种降低系统复杂度的方式吗?
答案是肯定的。
依靠一个经过测试和证明的模型,并不一定意味着使用这个模型和证明它一样复杂。
例如下面的表达式:
1 + 1 = 2
大家都“知道”它是正确的,并且能够使用它,因为已经有人证明它是正确的。
在本文的例子中,试图将一个已知的问题转化为一个图形计算,其中每个顶点都是一个计算单元。根据连接它们的边,在顶点之间“移动”。
接下来看下面的例子:
想要实现一个应用程序执行以下任务:
- 它接收一个订单请求作为输入。
- 如果订单有效,就会向仓库发送包装和运输请求,并通知客户订单成功。
- 如果订单无效,则通知客户。
把手头的任务看作是一个图形计算,可以将其描述如下:

以图形的方式思考问题有一些好处。
首先,有了图形以后,人类的思维更容易理解,不至于那么抽象了。
其次,鼓励我们遵循良好务实的软件设计原则,如关注点分离原则。每个顶点只做一件事。
再次,它使我们看到每个顶点所做的事,并将其外包给基础架构。
例如,每个顶点接收并可能发送消息。以容错的方式负责外包处理传入和传出消息是非常可取的。
部署也可以通过这种方式变得更加灵活 — 例如,可以部署一台单独计算机的每个计算单元,并让基础架构去负责固有的消息传递和分发。
负载均衡和可扩展性如何?可以依靠“外部”消息传递系统来管理同一计算单元的多个实例吗?答案是肯定的!
如果在订单验证过程中遇到瓶颈,是否可以实例化一个额外的验证计算单元并让它处理一些工作呢?可以的。
现在请记住,我们已经在图中描述了应该如何处理每个输入消息。还没有描述过如何部署它。
所以我们也分开考虑了软件的正确性和软件的部署问题。
可能的情况是,除了将实例化两个计算单元的验证顶点之外,还为每个“逻辑”图形顶点实例化一个物理计算单元,如下图所示:
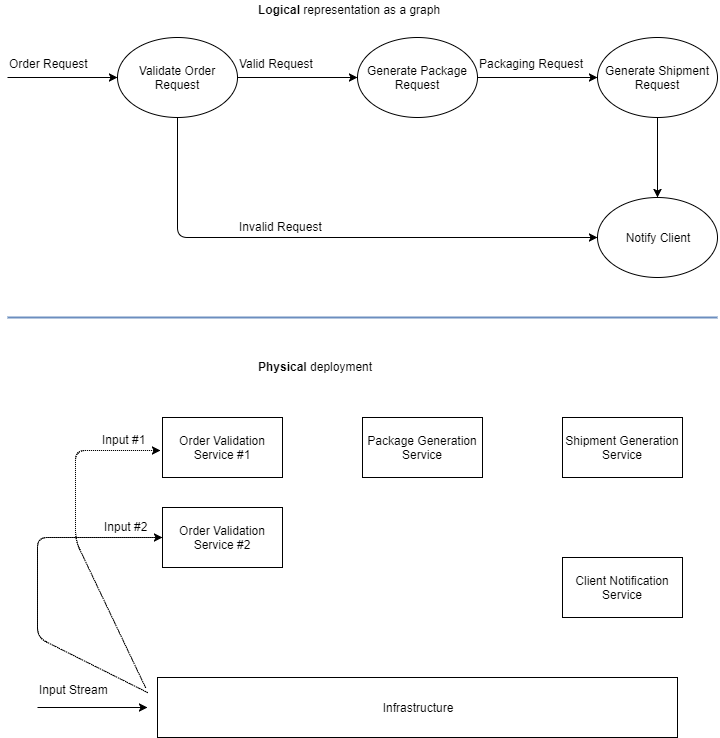
前面提到的关于关注点分离的提示,利用适当的基础架构,可以处理进程间的通信,给出不同的部署需求(每个组织/个人),以容错和可扩展的方式,旨在找准问题。
图形计算确实是有用的,帮助我们考虑软件解决方案,同时把软件部署排除在外 —只要有适当的基础架构,就可以做到这一点。
Apache Storm提供了以图形方式编写计算的能力,同时提供了一个固有的基础架构,使我们能够可靠高效地完成这些计算。
Apache Storm的方式
Apache Storm中,主要应用程序被称为拓扑(topology),也就是Storm拓扑。

每个拓扑代表一个永远在线的应用程序,它可以接收来自被称为喷嘴(spout)的数据源的输入。

喷嘴是输入消息的来源,称为元组。元组是动态类型的,它的成员可以是任何类型 —只要Storm“知道”如何序列化和反序列化这些类型。

元组正在按照拓扑的定义在螺栓( bolt)之间传递。每个螺栓都可以传递元组到其它螺栓,只要它们连接到它。一个螺栓可以修改一个元组或者创建一个新的元组。它也可以按原样传递传入的元组,或者根本不传递任何东西。
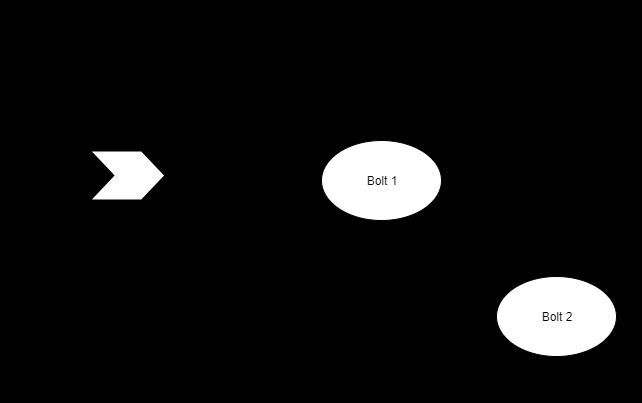
元组通过喷嘴的元组流向被称为流。多个流可以共存于一个拓扑中。每个数据流都与其它数据流并行处理。稍后将会再讲到这一点。

Storm极具融合性,并与其它技术很好地集成。它能够使用Elasticsearch,Mongodb,Kafka,Redis,Kinesis等基础架构。如果需要自定义的东西,这也是可能的,Storm有一个很大的并在不断发展的库生态系统。
所以,如果想用一句话总结一下“Storm方式”的话,我会说:
Apache Storm是一种分布式技术,旨在允许开发人员利用图形计算模型为问题同时提供“底层”(例如消息负载均衡)和“顶层“(例如准备使用Kafka Spout - 只需配置和使用来自Kafka的数据)的逻辑解决方案。
Apache Storm概述
为了更好地了解Storm如何工作,需要暂时缩小范围。
本文不会对技术本身进行深入地研究。但是,如果想更好地了解该技术,包括部署的演示,与其它技术的集成和监控,请参阅我的课程,在这里。
从宏观上看看Storm集群是如何建立的。这将有助于了解它是如何提供上述基础架构的,比如计算图形部分之间的可靠消息传递,以及某种程度的并行性,文章将在后面作进一步解释。
首先,storm集群是由(不足为奇)…节点构建而成的。这些节点可以采用任何一个主节点的形式运行Nimbus守护进程或者采用工作进程(worker)节点的形式—运行Supervisor守护进程。它采用主从架构方式,主节点是Nimbus,从节点是Supervisor,有关调度相关的信息存储在Zookeeper集群中。

主节点负责在工作节点之间分配工作。分配什么工作呢?实现图形计算的实际代码作为拓扑传递给Storm集群。
主节点和工作节点如何相互认知?通过Zookeeper。Zookeeper是一个分布式服务,作为一个可靠的配置和同步提供者。要了解更多关于Zookeeper的信息,包括安装和集成演示,请看看这里。

所以说主节点负责将代码分发给工作节点。但是,这里还有一个额外的抽象层:工作进程。
一个工作进程负责执行拓扑的一个子集。每个工作进程将实例化执行任务实例的执行器线程。这些任务可以是喷嘴或螺栓。

虽然理解起来可能相当困难,但是这种结构确实具有在各种物理机器,进程和线程之间分配逻辑计算图形的能力,从而使storm集群在硬件故障的情况下保持逻辑计算完整性。
一个工作进程挂了?没问题 —主节点会将其工作分配给另一个工作节点。

请注意,看起来主节点似乎是一个单点故障点。事实并不是这样。即使主节点发生故障或崩溃,拓扑仍将继续执行。显然,我们将无法向集群提交新拓扑,因为主节点有责任在工作节点之间进行代码共享,但是在线计算将继续下去。
这种不希望发生的情况可以通过在Storm集群(又名Nimbus H / A)中定义多个主节点来弥补。这样的话,一个失败的主节点将会被一个健康的主节点替换。
现在应该能够更好地理解Storm是如何将计算图形和物理硬件层(主节点和工作节点,zookeeper,执行进程中的工作进程和任务)的逻辑概念完全分离开来的(拓扑结构是由喷嘴和螺栓与元组之间的流动建立起来的)。
这种架构是团队之间关注点分离的推动者。可以将处理逻辑层的任务分配给开发人员,也可以将处理物理层的任务分配给DevOps工程师。
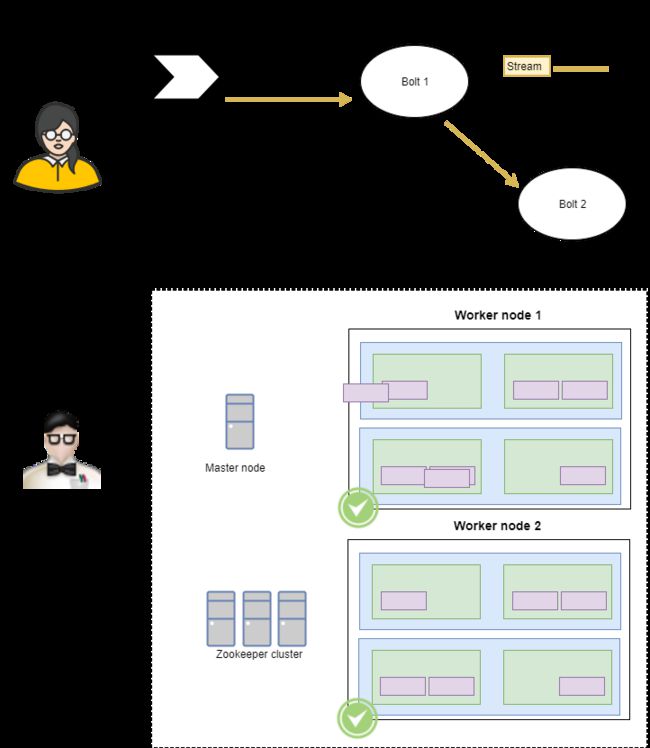
开发Storm的工程师考虑了上述关注点分离的概念,并向开发人员提供了在开发人员的机器上本地运行拓扑的思路。
谈论开发人员—不如看一些代码?
示例拓扑—让我们看一些代码
好吧,有些人可能以为在进行订单验证,包装和装运时,这个例子并不太适合演示图形计算。
我不这么认为。图形计算,就像任何其它模型一样都是一个工具。作为开发人员,软件架构师和/或研发副总裁,都需要决定这个工具是否适合手头上的任务。我认为对于高吞吐量的电子商务网站,Storm实际上非常适合作为一个稳定的后台。
接下来看看如何将上述用例作为一个Storm的拓扑实现。
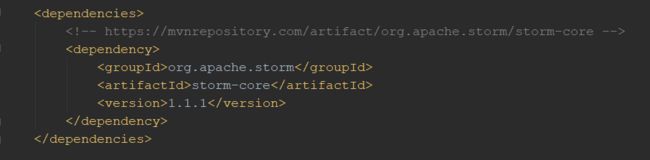
首先,需要建立一个新的项目,就用一个Maven项目来展示。已经将以下依赖项添加到pom.xml文件中:
首先创建一个使用由Storm提供的TopologyBuilder的拓扑:

为了设置拓扑喷嘴,调用TopologyBuilder实例上的setSpout方法,传递一个喷嘴ID和一个喷嘴实例。

这是进入图形计算的切入点。这也可能是一个KafkaSpout。
现在有信息进入系统,就想消化它。有时间在拓扑中添加一些螺栓。
把每一个螺栓连接到拓扑,将提供如下信息:
- 在拓扑中唯一标识它的螺栓ID。
- 它在拓扑中的前身,以及首选的分组方法。
- 一个可选的流ID。
2和3很快就会提到。
那么接下来看看带有所有螺栓的拓扑:
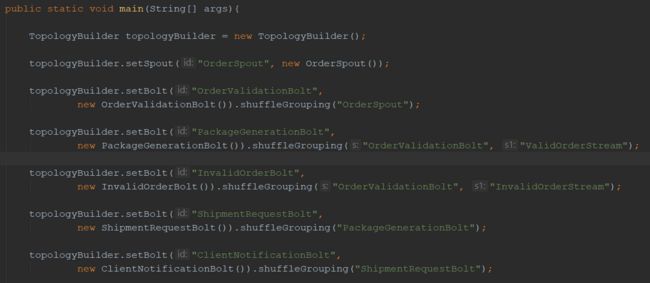
每一次添加一个螺栓到拓扑,都调用setBolt。

然后,给螺栓命名,并为该螺栓提供一个实例。该实例是根据每个螺栓所需逻辑实现的类。接下来看一下这样的螺栓。

每个螺栓,已经连接到另一个螺栓或喷嘴,并提供输入。

在验证螺栓的情况下,有两种可能的结果(有效的或无效的),根据每个可能的结果,已经创建了一个只在特定流(验证螺栓正在向其发送消息)上侦听消息的螺栓。
![]()

现在来观察一个螺栓的实现。为了符合Storm的架构,需要执行什么?

这里可以看到已经扩展了BaseRichBolt类。为了符合其定义,必须实现三种方法。
正如它名字暗示的那样,这个prepare方法是一个占位符,一旦元组到达它,就可以执行螺栓所需的任何必要的初始化,以实现恰当的功能。在大多数情况下,至少会将输出收集器引用保存到局部变量中。输出收集器允许发出新的元组到下面的螺栓。
它也允许确认一个元组。Storm会将任何未确认的元组视为一个未处理的数据结构,以便重新处理。
execute方法在每个元组传递时(由Storm基础结构)调用一次。在execute方法中将使用元组,在需要的情况下发出任何新的元组,最后,确认传入的元组。
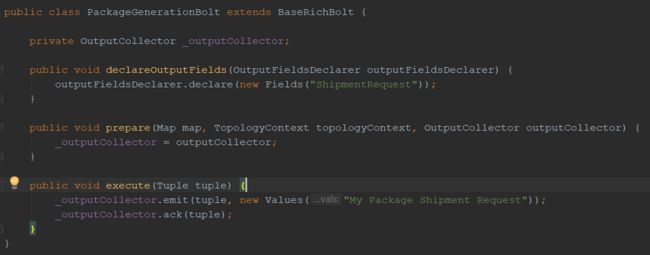
当想要传递一个特定的字段到下一个螺栓时,declareOutputFields方法是必需的。例如,PackageGenerationBolt 传递以一个字段名为“ShipmentRequest”的装运请求到下一个螺栓(ShipmentRequestBolt)时,要知道如何引用:


最后,将拓扑提交到集群并运行它。在这个例子中,提交给一个专门为调试而开发的本地集群:

一旦拓扑经过测试和调试,就可以安全地将其部署到 “真实”的Storm集群。
这可以通过几种方式来完成。
一般来说,需要将拓扑连同所有相关的依赖项打包到jar文件中,并将其传递给Storm集群。通过使用命令行来完成更简单。
如果想看到一个“真实的”的demo,请查看这里。
如何进行分布式计算?
太神奇了!现在明白了,把许多计算分解成图形的逻辑和物理形式并不是很难,因为顶点以“标准”形式(序列化元组)进行通信。
现在也知道代码是如何在Storm集群上执行的。
在将拓扑提交给集群后,打包成一个jar文件,拓扑组件(即spouts和bolt)被部署到各个storm工作节点(由主节点决定),并在工作节点中实例化——封装在任务线程中,存在执行过程中。

Storm基础架构知道拓扑内流动的数据流。这个基础架构还通过螺栓跟踪元组确认,为我们提供了可靠的消息传递系统。
内在的并行性:作为并行度的流
图形计算的好处之一是,可以在应用程序中清晰地显示单独的计算路径。
看看这里:
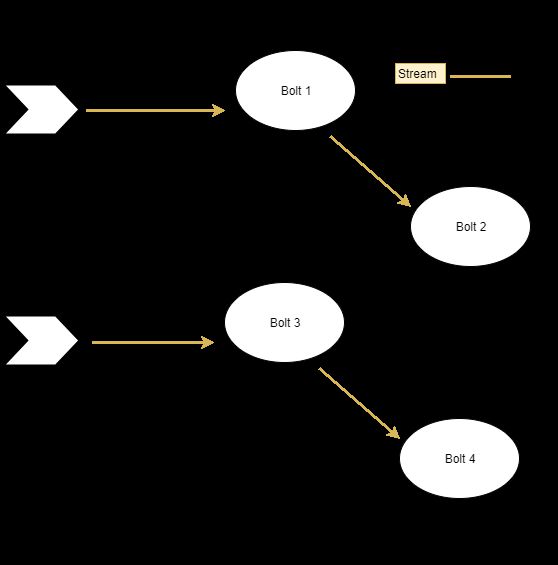
有什么东西阻止并行处理两种不同的数据流吗?当然没有,这是Storm的完美任务!
流是 Storm中的一种并行的程度。所有的流元组都将流经相关的螺栓(如拓扑所描述的那样),而不知道拓扑中的其它流。
螺栓(bolt)的实例
这是一个好的开始,是不是?不同的流可以分别单独处理。然而,还有另外一种并行度—在任务层面的并行度。作为一个优秀的学生,应该记住任务可以是喷嘴或螺栓的形式。
定义拓扑时,可以声明每个喷嘴或螺栓所需的并行度。

请注意,不希望任务没有控制的按需产生!太多的任务(即线程)会引入过度并行,并可能导致集群“慢下来”,最终让应用程序变得无法响应。
在使用Storm的并行度功能之前,请考虑想达到的并行度,并提供可用的资源。
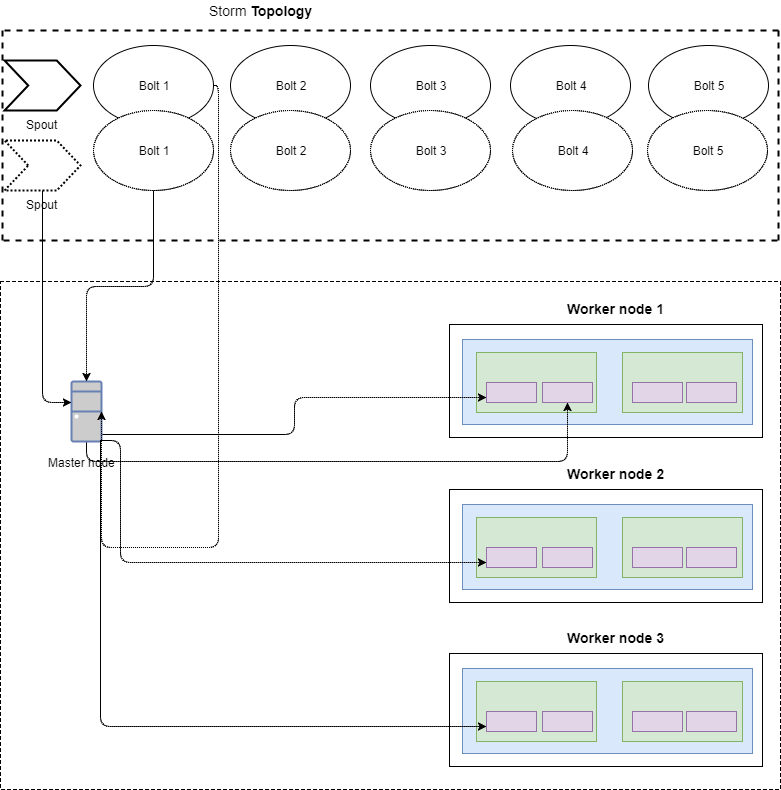
假设有3个Storm工作进程节点,并且部署了一个具有一个并行度设置为2的单个喷嘴的拓扑,以及5个并行度设置为2的螺栓 — storm将为喷嘴生成2个任务,每个螺栓生成5 * 2 = 10 个任务。
这意味着将有12个任务,storm集群将试图均匀地分布在3个工作节点上(下图没有画出所有的线以避免混乱)。
作为内部“秩序者”的分组
还是回到分组的概念。
之前已经看到,当创建一个螺栓时,已经指定了它的“输入”螺栓:

但是这样做的方式还不清楚,正如我们所说的那样,需要一个“随机分组”

奇怪,不是吗?分组与之前建立的图形拓扑有什么关系?难道不是所有的流元组都只是从一个螺栓流到另一个螺栓吗?
那么请记住,喷嘴和螺栓可以有多个实例,以便进行分布式并行计算。
虽然喷嘴或螺栓在逻辑上是一个原子计算单元,但它的物理实现并不一定。
分组是定义两个不同拓扑元素之间的元组流的方式。它将定义输入实体和目标实体的实例(任务)之间的元组是如何流动的。
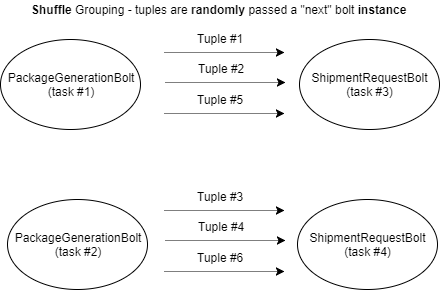
例如,“shuffleGrouping”将随机发送元组到螺栓实例。
提醒一下,在讨论分组时,讨论的是两个实体之间的数据流,并且只有两个实体。
在这里,可以看到每个元组是如何随机地转移到一个螺栓实例(任务),从PackageGenerationBolt到ShipmentRequestBolt。
一个最有趣的分组选项是“字段”分组,在这个分组中指定要将元组分组的特定字段。例如,分组ShipmentRequestBolt到基于字段“WarehouseId”的PackageGenerationRequest。由于这种“字段”的分组策略,所有带有相同WarehouseId值的元组,在输入元组时始终被定向到相同的ShipmentRequestBolt任务实例。
还有其它有趣的分组方法可以在这里查看。
结论
感谢大家与我一起度过这段短暂的旅程,总体地回顾了图形计算的概念和Apache Storm更具体的细节。在写这篇文章的时候,我一直牢记“保持简单”,假设一旦“理解了”这个想法并理解了这个工具,将能够决定你是否需要对Storm进行更深入的研究。这也是我提到额外的阅读和我的Pluralsight课程的原因。
我们从理解图形计算是什么以及它起源于何处开始了这一旅程。特别是理解了它在计算机科学领域是多么深奥的概念。
一旦确信(希望),我们已经开始讨论支持基础架构的好处,以便可靠地将应用程序作为图形计算实现。
我们介绍了Apache Storm这样一种技术。
storm在逻辑层、拓扑层和物理层——物理集群本身进行了回顾。
理解了拓扑如何在整个集群中传播,并在物理层的最终抽象层(任务)中执行。
然后讨论了Storm如何提供并行度— 无论是在流级别和还是在特定任务级别(喷嘴或螺栓)。
看一些代码,我试图传递使用storm的简单和美丽。
希望已经成功地吸引了你。
SDCC 2017之数据库线上峰会即将强势来袭,秉承干货实料(案例)的内容原则,邀请了来自阿里巴巴、腾讯、微博、网易等多家企业的数据库专家及高校研究学者,围绕Oracle、MySQL、PostgreSQL、Redis等热点数据库技术展开,从核心技术的深挖到高可用实践的剖析,打造精华压缩式分享,举一反三,思辨互搏,报名及更多详情可点击此处查看。