机器学习——单层前馈神经网络与BP算法
以下内容均为个人理解,如有错误,欢迎指出
文章目录
- 什么是人工神经网络
- M-P神经元模型
- 单层前馈神经网络
- 常用的激活函数以及优缺点
- sigmoid函数
- Tanh函数
- ReLU函数
- 为什么要使用激活函数
- 神经网络的学习过程
- 如何更新神经元之间的连接权与阈值
- 什么是BP算法
- 什么是梯度下降算法
- 方向导数
- 梯度
- 在单层前馈神经网络中使用BP算法
- 针对sigmoid激活函数的推导过程
- SGD
- mini-batch GD
- 为什么mini-batch GD、SGD是收敛的
- 全局最小与局部最小
- 正则化
- 参考文献
什么是人工神经网络
摘自维基百科1
人工神经网络(英语:Artificial Neural Network,ANN),简称神经网络(Neural Network,NN)或类神经网络,在机器学习和认知科学领域,是一种模仿生物神经网络(动物的中枢神经系统,特别是大脑)的结构和功能的数学模型或计算模型,用于对函数进行估计或近似。神经网络由大量的人工神经元联结进行计算。大多数情况下人工神经网络能在外界信息的基础上改变内部结构,是一种自适应系统,通俗的讲就是具备学习功能。现代神经网络是一种非线性统计性数据建模工具。
由此可知,人工神经网络是一个非线性模型,依网络架构,神经网络的分类主要有:
- 前馈神经网络(Feed Forward Network)
- 递归神经网络(Recurrent Network)
- 强化式架构(Reinforcement Network)
本文介绍BP算法在前馈神经网络的应用
M-P神经元模型
以下关于生物神经元工作方式的描述糅合了周志华老师的《机器学习》[3]以及一些生物学知识
在生物神经网络中,每个神经元与其他神经元相连,当它“兴奋”时,就会向连着连接的神经元发送化学物质,从而改变这些神经元内的电位,如果某个神经元的电位超过一个阈值时,便会转变为“兴奋”状态,向其他神经元发送化学物质,两个神经元信号的传递方向是单向的
从人工神经网络的概念可知其模仿了生物神经网络,而经典的M-P神经元模型便模仿了上述生物神经元的工作方式:
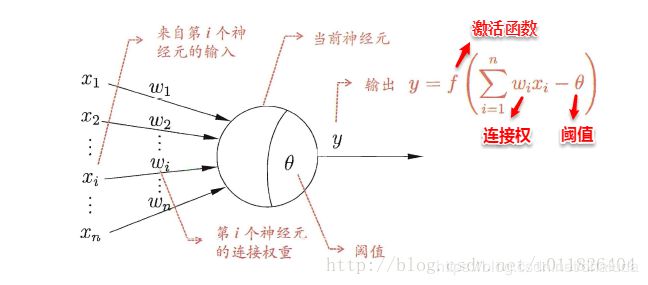
其中, x i x_i xi可理解为第i个相邻神经元向本神经元发送的化学物质量, w i w_i wi可理解为单位化学物质对于当前神经元电位的影响,则 w i x i w_ix_i wixi表示第i个神经元对本神经元电位的影响(增加or减少多少),假设当前神经元的电位原本为0,则 ∑ 1 n w i x i \sum_1^nw_ix_i ∑1nwixi表示当前神经元的电位,将其与阈值相减,若大于0,则神经元处于兴奋状态,用激活函数表示本神经元向下一个神经元发送的化学物质数量
单层前馈神经网络
将上述的多个M-P神经元模型按层连接,就能得到单层前馈神经网络,如下:
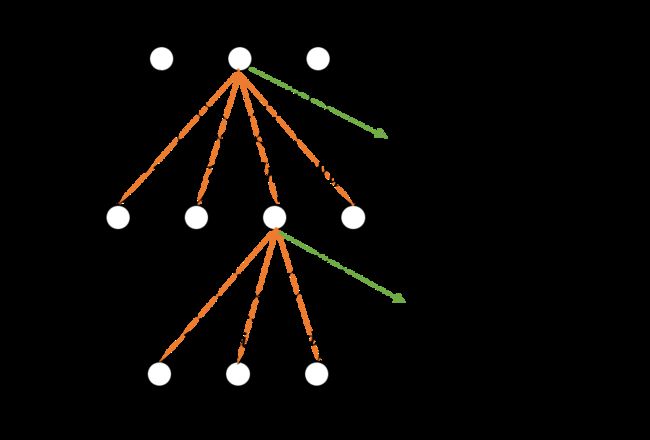
单隐层前馈神经网络由输入层、隐含层、输出层组成,其可简单模拟生物神经网络,每层神经元与下一层神经元连接,神经元之间不存在跨层连接、同层连接,输入层用于数据的输入,隐含层与输出层神经元对数据进行加工
常用的激活函数以及优缺点
我们用激活函数表示本神经元向下一个神经元发送的化学物质数量,科学家经过多年的实验,具有较好结果的激活函数如下
sigmoid函数
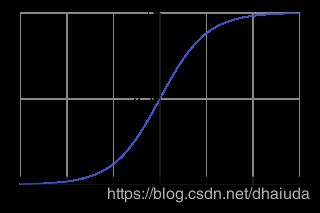
- 数学形式
y = 1 1 + e − x y=\frac{1}{1+e^{-x}} y=1+e−x1
定义域 ( − ∞ , + ∞ ) (-\infin,+\infin) (−∞,+∞),值域 ( 0 , 1 ) (0,1) (0,1)
-
图像
-
缺点
1、指数运算会耗费大量计算资源
2、容易出现梯度消失现象(使用batch GD或是mini-batch GD或是SGD),这是由sigmoid的导数图像决定的:
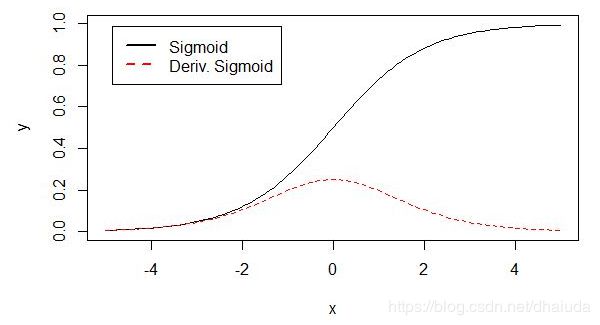
虚线表示sigmoid的导数,可以看到其很快便趋近于0,这意味着某些权重的更新速度缓慢(使用batch GD或是mini-batch GD或是SGD),神经网络的收敛速度很慢。
3、其不是零均值,这导致神经网络的收敛速度缓慢,关于这点,网络上大部分解释是这样的:

这个观点我并不认同(也可能是我理解错了),下面的Tanh函数是零均值的,但是它仍然会出现上图所说的情况,假设我们使用Tanh函数作为激活函数,依据链式法则, σ ( ∑ i w i x i + b ) \sigma(\sum_i w_i x_i + b) σ(∑iwixi+b)对 w i w_i wi求导得: σ , ( ∑ i w i x i + b ) x i \sigma^,(\sum_i w_i x_i + b)x_i σ,(∑iwixi+b)xi, σ , ( ∑ i w i x i + b ) \sigma^,(\sum_i w_i x_i + b) σ,(∑iwixi+b)恒大于0,当 x i x_i xi一直为正时,对 w i w_i wi的更新也总是正值,个人比较认同的观点是零均值的函数在用SGD进行更新时,效果更接近自然梯度,而sigmoid函数不是零均值,神经网络的收敛速度缓慢
Tanh函数
- 数学形式:
t a n h ( x ) = e x − e − x e x + e − x tanh(x)=\frac{e^x-e^{-x}}{e^x+e^{-x}} tanh(x)=ex+e−xex−e−x
定义域 ( − ∞ , + ∞ ) (-\infin,+\infin) (−∞,+∞),值域 ( 0 , 1 ) (0,1) (0,1)
- 图像

Tanh函数为sigmoid函数变换得到,它是0均值的
- 相比于sigmoid函数,其具有以下优点(摘自深度学习中的激活函数与梯度消失、梯度爆炸)
与 sigmoid 的区别是,tanh 是 0 均值的,因此实际应用中 tanh 会比 sigmoid 更好。文献 [LeCun, Y., et al., Backpropagation applied to handwritten zip code recognition. Neural computation, 1989. 1(4): p. 541-551.] 中提到tanh 网络的收敛速度要比sigmoid快,因为tanh 的输出均值比 sigmoid 更接近 0,SGD会更接近 natural gradient[4](一种二次优化技术),从而降低所需的迭代次数
关于自然梯度,请查看自然梯度
- 缺点
1、由导数图像可知,其仍然存在梯度消失现象
2、设计到指数运算,比较耗时
ReLU函数
- 数学形式
ReLU = max ( 0 , x ) \text{ReLU} = \max(0, x) ReLU=max(0,x)
定义域 ( − ∞ , + ∞ ) (-\infin,+\infin) (−∞,+∞),值域 [ 0 , + ∞ ) [0,+\infin) [0,+∞)
- 图像
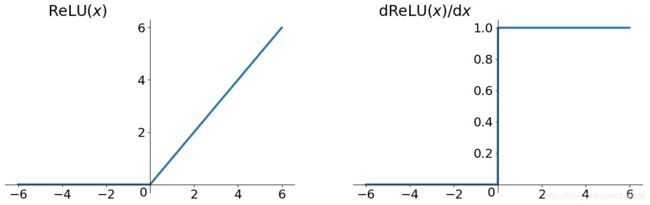
- 优点
1、在正区间解决了梯度消失问题
2、计算速度快,一次判断,就会有输出,不需要指数运算等
3、收敛速度比sigmoid、tanh快
实战中建议使用该函数 - 缺点
1、不是零均值
2、当某次梯度更新比较剧烈时,可能会导致ReLU函数的自变量持续小于0,此时ReLU的输出持续为0,神经元无法激活(死亡),对应的参数不会被更新,由于这个特性,ReLU函数训练后的神经网络具有稀疏性,部分神经元不会被激活。
ReLU的表现如此优异,我觉得一部分原因是因为它较好的模拟了人体神经元工作的场景,2001年,Dayan、Abott从生物学角度模拟出了脑神经元接受信号更精确的激活模型,如下图:

其中横轴是时间(ms),纵轴是神经元的放电速率(Firing Rate)。同年,Attwell等神经科学家通过研究大脑的能量消耗过程,推测神经元的工作方式具有稀疏性和分布性;2003年Lennie等神经科学家估测大脑同时被激活的神经元只有1~4%,这进一步表明了神经元的工作稀疏性,而经过ReLU训练的神经网络也具有一定的稀疏性
为什么要使用激活函数
如果不使用激活函数,神经网络将会是一个线性模型,线性模型在多数情况下会有局限性,激活函数相当于在神经网络中加入了非线性因素,使神经网络变为非线性模型,更多请查看神经网络激励函数的作用是什么?有没有形象的解释?
神经网络的学习过程
以下摘自周志华老师的《机器学习》
神经网络的学习过程,就是根据训练数据来调整神经元之间的连接权(即单隐层神经网络那张图中的 w 1 j 、 w 2 j w_{1j}、w_{2j} w1j、w2j等)以及每个功能神经元的阈值
如何更新神经元之间的连接权与阈值
使用BP算法更新神经元之间的连接权
什么是BP算法
摘自4维基百科
反向传播(英语:Backpropagation,缩写为BP)是“误差反向传播”的简称,是一种与最优化方法(如梯度下降法)结合使用的,用来训练人工神经网络的常见方法。该方法对网络中所有权重计算损失函数的梯度。这个梯度会反馈给最优化方法,用来更新权值以最小化损失函数。
反向传播要求有对每个输入值想得到的已知输出,来计算损失函数梯度。因此,它通常被认为是一种监督式学习方法,虽然它也用在一些无监督网络(如自动编码器)中。它是多层前馈网络的Delta规则的推广,可以用链式法则对每层迭代计算梯度。反向传播要求人工神经元(或“节点”)的激励函数可微。
BP算法具有两个关键点:
1、根据输入值获得输出值,计算损失函数的梯度
2、将梯度反馈给最优化算法(例如梯度下降法),由最优化算法对连接权和阈值进行更新,使得损失函数变小
什么是梯度下降算法
首先了解下什么是方向导数
方向导数
- 概念:表示函数沿任意一个方向的变化率,变化率越大,函数沿这个方向增加的越快,它是一个标量
- 个人理解:
1、变化率即函数自变量沿某一方向变化时,因变量变化的快慢,方向导数的式子如下:
这个式子为什么可以反映函数自变量沿某一方向变化时,因变量变化的快慢?
以三维空间为例子(高纬空间也是一样的,只是不好想象),函数Z=f(x,y),A(x0,y0,z0)、B(x0+ Δ \Delta Δx0,y0+ Δ \Delta Δy0,z0+ Δ \Delta Δz0)为Z上的两个点,以( Δ \Delta Δx0, Δ \Delta Δy0)方向做垂直于xOy平面的平面,记为H,H平面切割函数Z,会在平面H上留下一个轨迹,这个过程就是将函数Z投影到H平面,在H平面上建立坐标轴,A点记为 ( x a , y a x_a,y_a xa,ya) ,B点为( x b , y b x_b,y_b xb,yb),则H平面上过 A’、B’ 点的直线的斜率为:
当A’ 与 B’ 之间的距离趋近于0(即 ρ \rho ρ趋近于0),方向导数即为 A’ 点的斜率,斜率可以反映一个函数的”陡峭“程度,即变化率,所以方向导数可以表示函数自变量沿某一方向(在本例中,为( Δ \Delta Δx0, Δ \Delta Δy0)方向)变化时,因变量变化的快慢

梯度
- 概念:方向导数取最大值的方向。在当前点,函数沿这个方向的增大速度最快
- 注意事项:梯度是一个向量,方向导数是一个实值
梯度的计算公式:
这个公式的推导不在此处讲解
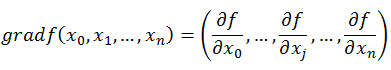
我们认为梯度的反方向是当前点函数下降速度最快的方向,原因如下2:
对于函数 f ( x ) f(x) f(x)来说,对 f ( x + v ) f(x+v) f(x+v)在x处进行泰勒一阶展开得: f ( x + v ) ≈ f ( x ) + ∇ f ( x ) T v f(x+v)\approx f(x)+\nabla f(x)^T v f(x+v)≈f(x)+∇f(x)Tv, ∇ \nabla ∇表示梯度,梯度和 v v v均为一个向量, ∇ f ( x ) T v \nabla f(x)^T v ∇f(x)Tv表示这两个向量的点积,我们想令函数下降的幅度最大,即令 ∇ f ( x ) T v \nabla f(x)^T v ∇f(x)Tv具有最小值,当两个向量方向相反时,向量点积具有最小值,此时 ∇ f ( x ) T \nabla f(x)^T ∇f(x)T与 v v v方向相反,所以梯度的反方向,是函数在当前点下降速度最快的方向,由此可导出梯度下降的公式,假设待优化参数 x x x为 ( x 1 , x 2 , . . . . , x n ) (x_1,x_2,....,x_n) (x1,x2,....,xn),则参数的更新公式如下:
x 1 = x 1 − η ∂ f ( x ) ∂ x 1 x_1=x_1-\eta\frac{\partial f(x)}{\partial x_1} x1=x1−η∂x1∂f(x)
x 2 = x 2 − η ∂ f ( x ) ∂ x 2 x_2=x_2-\eta\frac{\partial f(x)}{\partial x_2} x2=x2−η∂x2∂f(x)
…
x n = x n − η ∂ f ( x ) ∂ x n x_n=x_n-\eta\frac{\partial f(x)}{\partial x_n} xn=xn−η∂xn∂f(x)
其中 η \eta η表示往梯度反方向前进的“步数”,“步数”过小会导致函数收敛速度过慢,过大会导致函数震荡不收敛
在单层前馈神经网络中使用BP算法
本节将基于下列条件推导参数的更新表达式
- f ( x ) f(x) f(x)表示sigmoid激活函数
- 对于训练样例( x k , y k x_k,y_k xk,yk),单层前馈神经网络的输出为 y k ^ = ( y 1 k ^ , y 2 k ^ , . . . . , y l k ^ ) \hat{y_k}=(\hat{y_1^k},\hat{y_2^k},....,\hat{y_l^k}) yk^=(y1k^,y2k^,....,ylk^),即 y j k ^ = f ( β j − θ j ) \hat{y_j^k}=f(\beta_j-\theta_j) yjk^=f(βj−θj), θ j \theta_j θj表示输出层第 j j j个神经元的阈值, β j \beta_j βj为输出层第 j j j个神经元的输入, β j = ∑ h = 1 q w h j b h \beta_j=\sum_{h=1}^qw_{hj}b_h βj=∑h=1qwhjbh, b h b_h bh表示第h个隐含层神经元的输出, w h j w_{hj} whj表示隐含层第 h h h个神经元与输出层第 j j j个神经元的连接权
- b h = f ( α h − γ h ) b_h=f(\alpha_h-\gamma_h) bh=f(αh−γh), α h \alpha_h αh表示第 h h h个隐含层神经元的输入, α h = ∑ i = 1 d v i h x i \alpha_h=\sum_{i=1}^dv_{ih}x_i αh=∑i=1dvihxi, v i h v_{ih} vih表示输入层第 i i i个神经元与隐含层第 h h h个神经元的连接权, γ h \gamma_h γh表示隐含层第 h h h个神经元的阈值
- 我们使用均方误差度量神经网络的输出 y j k ^ \hat{y_j^k} yjk^与训练样例的实例 y k y_k yk的差距: E k = 1 2 ∑ j = 1 l ( y j k ^ − y j ) 2 E_k=\frac{1}{2}\sum_{j=1}^l(\hat{y_j^k}-y_j)^2 Ek=21∑j=1l(yjk^−yj)2,这就是损失函数。使用梯度下降法更新连接权,使均方误差(损失函数)不断下降,我们先推导针对单个样例,单层前馈神经网络如何利用BP算法更新神经元的连接权
我们需要优化的参数(忽略了下标)有: w 、 θ 、 γ 、 v w、\theta、\gamma、v w、θ、γ、v,我们首先将训练数据( x k , y k x_k,y_k xk,yk)输入到单层前馈神经网络中,获得输出值后使用BP算法更新参数
针对sigmoid激活函数的推导过程
首先明确一点,sigmoid函数具有一个很好的性质,其一阶导数为 f ( x ) ( 1 − f ( x ) ) f(x)(1-f(x)) f(x)(1−f(x))。我们随机初始化(也可以按条件初始化)所有待优化参数的值,先将训练样例输入到单层前馈神经网络,获得待优化参数(忽略下标) w 、 θ 、 γ 、 v w、\theta、\gamma、v w、θ、γ、v的值
1、对 w h j w_{hj} whj进行更新
运用求导的链式法则可得: ∂ E k ∂ w h j = ∂ E k ∂ y j k ^ ∗ ∂ y j k ^ ∂ β j ∗ ∂ β j ∂ w h j \frac{\partial E_k}{\partial w_{hj}}=\frac{\partial E_k}{\partial \hat{y_j^k}}*\frac{\partial{\hat{y_j^k}}}{\partial \beta_j}*\frac{\partial \beta_j}{\partial w_{hj}} ∂whj∂Ek=∂yjk^∂Ek∗∂βj∂yjk^∗∂whj∂βj,则有 g j k = ∂ E k ∂ y j k ^ ∗ ∂ y k k ^ ∂ β j = y ^ j k ( 1 − y ^ j k ) ( y ^ j k − y j k ) g_j^k=\frac{\partial E_k}{\partial \hat{y_j^k}}*\frac{\partial{\hat{y_k^k}}}{\partial \beta_j}=\hat y_j^k(1-\hat y_j^k)(\hat y_j^k-y_j^k) gjk=∂yjk^∂Ek∗∂βj∂ykk^=y^jk(1−y^jk)(y^jk−yjk),设 w h j w_{hj} whj更新后为 w h j ′ w'_{hj} whj′,则有 w h j ′ = w h j − η g j k b h w'_{hj}=w_{hj}-\eta g_j^k b_h whj′=whj−ηgjkbh
2、对 θ j \theta_j θj进行更新
运用求导的链式法则可得: ∂ E k ∂ θ j = ∂ E k ∂ y j k ^ ∗ ∂ y j k ^ ∂ θ j = y ^ j k ( 1 − y ^ j k ) ( y j k − y ^ j k ) \frac{\partial E_k}{\partial \theta_{j}}=\frac{\partial E_k}{\partial \hat{y_j^k}}*\frac{\partial{\hat{y_j^k}}}{\partial \theta_j}=\hat y_j^k(1-\hat y_j^k)(y_j^k-\hat y_j^k) ∂θj∂Ek=∂yjk^∂Ek∗∂θj∂yjk^=y^jk(1−y^jk)(yjk−y^jk),设 θ j \theta_j θj更新后为 θ j ′ \theta'_j θj′,则有 θ j ′ = θ j − η ( − g j k ) \theta'_j=\theta_j-\eta (-g_j^k) θj′=θj−η(−gjk)
3、对 γ h \gamma_h γh进行更新
注意到 γ h \gamma_h γh会影响到 ( y 1 , y 2 , . . . . , y n ) (y_1,y_2,....,y_n) (y1,y2,....,yn),我们将均方误差展开:
E k = 1 2 [ ( y ^ 1 − y 1 ) 2 + ( y ^ 2 − y 2 ) 2 + . . . . . + ( y ^ n − y n ) 2 ] E_k=\frac{1}{2}[(\hat y_1-y_1)^2+(\hat y_2-y_2)^2+.....+(\hat y_n-y_n)^2] Ek=21[(y^1−y1)2+(y^2−y2)2+.....+(y^n−yn)2]
假设我们对 γ 1 \gamma_1 γ1进行更新,注意到:
y ^ i = f ( β i − θ i ) = f ( ∑ h = 1 q ( w h i b h ) − θ i ) ( i = 1 , 2.... , n ) \hat y_i=f(\beta_i-\theta_i)=f(\sum_{h=1}^q(w_{hi}b_h)-\theta_i)(i=1,2....,n) y^i=f(βi−θi)=f(∑h=1q(whibh)−θi)(i=1,2....,n)
b 1 = f ( α 1 − γ 1 ) b_1=f(\alpha_1-\gamma_1) b1=f(α1−γ1)
所以对 γ h \gamma_h γh求导会是一个和式:
∂ E k ∂ γ h = − ∑ j = 1 l ( y ^ j k − y j k ) y ^ j k ( 1 − y ^ j k ) w h j b h ( 1 − b h ) \frac{\partial E_k}{\partial \gamma_h}=-\sum_{j=1}^l(\hat y_j^k-y_j^k)\hat y_j^k(1-\hat y_j^k)w_{hj}b_h(1-b_h) ∂γh∂Ek=−∑j=1l(y^jk−yjk)y^jk(1−y^jk)whjbh(1−bh)
设 e h k = − ∑ j = 1 l ( y ^ j k − y j k ) y ^ j k ( 1 − y ^ j k ) w h j b h ( 1 − b h ) e_h^k=-\sum_{j=1}^l(\hat y_j^k-y_j^k)\hat y_j^k(1-\hat y_j^k)w_{hj}b_h(1-b_h) ehk=−∑j=1l(y^jk−yjk)y^jk(1−y^jk)whjbh(1−bh)
设 γ h \gamma_h γh更新后为 γ h ′ \gamma'_h γh′,则有 γ h ′ = γ h − η e h k \gamma'_h=\gamma_h-\eta e_h^k γh′=γh−ηehk
4、对 v i h v_{ih} vih进行更新
注意到 v i h v_{ih} vih会影响到 ( y 1 , y 2 , . . . . , y n ) (y_1,y_2,....,y_n) (y1,y2,....,yn),我们将均方误差展开:
E k = 1 2 [ ( y ^ 1 − y 1 ) 2 + ( y ^ 2 − y 2 ) 2 + . . . . . + ( y ^ n − y n ) 2 ] E_k=\frac{1}{2}[(\hat y_1-y_1)^2+(\hat y_2-y_2)^2+.....+(\hat y_n-y_n)^2] Ek=21[(y^1−y1)2+(y^2−y2)2+.....+(y^n−yn)2]
假设我们对 v 11 v_{11} v11进行更新,注意到:
y ^ i = f ( β i − θ i ) = f ( ∑ h = 1 q ( w h i b h ) − θ i ) ( i = 1 , 2.... , n ) \hat y_i=f(\beta_i-\theta_i)=f(\sum_{h=1}^q(w_{hi}b_h)-\theta_i)(i=1,2....,n) y^i=f(βi−θi)=f(∑h=1q(whibh)−θi)(i=1,2....,n)
b 1 = f ( α 1 − γ 1 ) b_1=f(\alpha_1-\gamma_1) b1=f(α1−γ1)
α 1 = ∑ i = 1 d v i 1 x i \alpha_1=\sum_{i=1}^d v_{i1}x_i α1=∑i=1dvi1xi
所以对 v i h v_{ih} vih求导会是一个和式:
∂ E k ∂ v i h = ∑ j = 1 l ( y ^ j k − y j k ) y ^ j k ( 1 − y ^ j k ) w h j b h ( 1 − b h ) x i \frac{\partial E_k}{\partial v_{ih}}=\sum_{j=1}^l(\hat y_j^k-y_j^k)\hat y_j^k(1-\hat y_j^k)w_{hj}b_h(1-b_h)x_i ∂vih∂Ek=∑j=1l(y^jk−yjk)y^jk(1−y^jk)whjbh(1−bh)xi
设 v i h v_{ih} vih更新后为 v i h ′ v'_{ih} vih′,则有 v i h ′ = v i h − η ( − e h k ) x i v'_{ih}=v_{ih}-\eta (-e_h^k)x_i vih′=vih−η(−ehk)xi
上述过程是对于单个样例进行推导,假设有m个训练样例,我们需要最小化的是训练集上的累积误差: E = 1 m ∑ k = 1 m E k E=\frac{1}{m}\sum_{k=1}^mE_k E=m1∑k=1mEk,则参数更新公式变为:
w h j ′ = w h j − η 1 m ∑ k = 1 m g j k b h w'_{hj}=w_{hj}-\eta\frac{1}{m}\sum_{k=1}^mg_j^k b_h whj′=whj−ηm1∑k=1mgjkbh
θ j ′ = θ j − η 1 m ∑ k = 1 m ( − g j k ) \theta'_j=\theta_j-\eta\frac{1}{m}\sum_{k=1}^m(-g_j^k) θj′=θj−ηm1∑k=1m(−gjk)
γ h ′ = γ h − η 1 m ∑ k = 1 m e h k \gamma'_h=\gamma_h-\eta\frac{1}{m}\sum_{k=1}^me_h^k γh′=γh−ηm1∑k=1mehk
v i h ′ = v i h − η 1 m ∑ k = 1 m ( − e h k ) x i v'_{ih}=v_{ih}-\eta\frac{1}{m}\sum_{k=1}^m(-e_h^k)x_i vih′=vih−ηm1∑k=1m(−ehk)xi
在平常的训练中,训练数据通常非常庞大,我们需要完全读取完训练数据后才能更新参数,这会导致参数的更新速度非常缓慢,因此,我们通常使用SGD或是mini-batch GD进行参数的更新
SGD
概念:每次读取一个训练数据,对参数进行更新
缺点:不同训练样例的更新效果可能会出现抵消现象,但是随机梯度下降法被证明是收敛的
mini-batch GD
概念:读取部分训练数据,运用累计误差对参数进行更新
实践中通常采用mini-batch GD,mini-batch GD也是收敛的
为什么mini-batch GD、SGD是收敛的
本人比较认同以下观点,内容摘自知乎5
直观来看,batch GD, mini-batch GD, SGD都可以看成SGD的范畴。因为大家都是在一个真实的分布中得到的样本,对于分布的拟合都是近似的。那这个时候三种方式的梯度下降就都是可以看成用样本来近似分布的过程,都是可以收敛的!
全局最小与局部最小
上述更新过程在梯度为0时便不会在更新参数,但是梯度为0时可能是全局最小点,也可能是局部最小点,我们当然希望我们的模型收敛于累计误差的全局最小点,但有时我们的模型会收敛于局部最小点,为此,我们可以使用某些启发式的方法尝试跳出局部最小点,但不一定能获得全局最小
1、模拟退火算法
2、遗传算法
3、用多组不同参数初始化神经网络,获得误差最小的一组参数作为最终方案
4、使用SGD或mini-batch GD,由于其不是对全局累积误差进行更新,有些样例对参数的更新效果会使全局累计误差往局部最小的方向走,有些样例对参数的更新效果可能使全局累计误差跳出局部最小
正则化
由于神经网络的学习能力很强大,有可能过于好的拟合训练数据,从而失去泛化能力(即对于训练数据的误差不断下降,但是测试数据的误差不断上升),为了防止过拟合的出现,我们通常对累积误差进行正则化,让累积误差加上一个用于描述网络复杂度的部分,即 E = λ 1 m ∑ k = 1 m E k + ( 1 − λ ) ∑ i w i 2 E=\lambda\frac{1}{m}\sum_{k=1}^{m}E_k+(1-\lambda )\sum_i w_i^2 E=λm1∑k=1mEk+(1−λ)∑iwi2, λ ϵ ( 0 , 1 ) \lambda \epsilon (0,1) λϵ(0,1),可通过调参进行确定
参考文献
[1] 人工神经网络
[2] 为什么梯度的负方向是局部下降最快的方向?
[3] 《机器学习》 周志华
[4] BP算法
[5] 如何理解随机梯度下降(Stochastic gradient descent,SGD)?