Deepcamp 题目
1.下图显示的机器学习使用的激活函数(Activation function)的图形,是下列哪一个函数的图形?【此题仅一个正确选项】
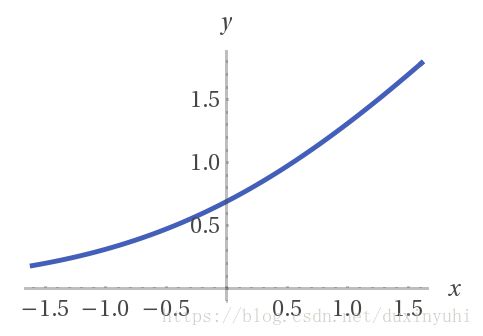
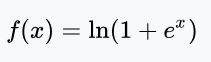
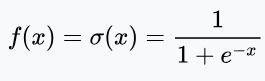
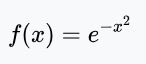
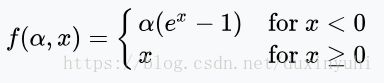
2、 有关深度学习加速芯片,以下的说法中不正确的是:【此题仅一个正确选项】 (5分) A、GPU既可以做游戏图形加速,也可以做深度学习加速。
B、Google TPU已经发展了三代,它们只能用于推断(Inference)计算,不能用于训练(Training)计算。
C、GPU(显卡)和ASIC芯片都可以用来加速区块链中的“挖矿”算法。
D、FPGA最早是作为CPLD的竞争技术而出现的。
3、 有关机器学习算法,以下说法中不正确的是:【此题仅一个正确选项】 (5分) A、 随机梯度下降(Stochastic Gradient Descent)算法是用小规模的样本近似估计梯度的方法,适合在大规模数据上训练深度神经网络,但在逻辑回归、SVM等算法中的作用很有限。
B、一个聚类算法将样本分成k个不同的聚类(cluster),从另一个角度说,这个聚类算法其实是为样本中的每一个实例提供了一种k维的one-hot编码方式。
C、当深度学习网络的最后一层是一个softmax分类器时 , 我们可以把网络的前面部分看成是一种表示学习 ( Representation Learning)的计算单元。
D、之所以说监督学习和无监督学习之间并不存在一条严格的界限,是因为很难客观地区分监督者给定的一个值是特征(feature)还是目标(target)。
4、 有关深度神经网络的训练(Training)和推断(Inference),以下说法中不正确的是:【此题仅一个正确选项】 (5分) A、将数据分组部署在不同GPU上进行训练能提高深度神经网络的训练速度。
B、TensorFlow使用GPU训练好的模型,在执行推断任务时,也必须在GPU上运行。
C、GPU所配置的显存的大小,对于在该GPU上训练的深度神经网络的复杂度、训练数据的批次规模等,都是一个无法忽视的影响因素。
D、将模型中的浮点数精度降低,例如使用float16代替float32,可以压缩训练好的模型的大小。
5、 有关广度优先搜索(Breadth-first Search)和深度优先搜索(Depth-first Search),以下说法中正确的是:【此题仅一个正确选项】 (5分) A、在解决最短路径问题时,Dijkstra算法(Dijkstra’s algorithm)本质上是一种考虑了边(Edge)的权重的深度优先搜索。
B、在解决迷宫问题时,深度优先搜索总会比广度优先搜索更快地找到迷宫出口。
C、广度优先搜索需要在搜索的每一层保存该层的所有结点,这一操作只能用队列这种数据结构来完成。
D、广度优先搜索和深度优先搜索都可以用于遍历一棵树。
6、 下面的python3函数,如果输入的参数n非常大,函数的返回值会趋近于以下哪一个值(选项中的值用Python表达式来表示)?【此题仅一个正确选项】
import random
def foo(n):
random.seed()
c1 = 0
c2 = 0
for i in range(n):
x = random.random()
y = random.random()
r1 = x * x + y * y
r2 = (1 - x) * (1 - x) + (1 - y) * (1 - y)
if r1 <= 1 and r2 <= 1:
c1 += 1
else:
c2 += 1
return c1 / c2
A、4 / 3
B、math.tan(53 / 180 * math.pi)
C、(math.pi - 2) / (4 - math.pi)
D、math.e ** (6 / 21)
7、 某二叉树共有4个结点,前序(先根序)遍历该二叉树的4个结点并记录各结点取值,得到的结果是“abcd”。那么,该二叉树有多少种可能的拓扑结构?【此题仅一个正确选项】 (10分) A、12
B、14
C、10
D、16
8、 一个4x3的矩阵如下图所示:
对这个矩阵做奇异值分解(Singular Value Decomposition)后,非0的奇异值(Singular Value)个数是:【此题仅一个正确选项】 (10分) A、4

B、3
C、2
D、1
9、 给定词典 [a, b, c, d, e],基于这个五单词词典的三个文档(document)内容如下: DocA: [a, b, b, d, d, e] DocB: [b, b, b, e, e, e, d, a] DocC: [d, b, b, e] 如果使用 bag-of-words model 将每个文档表示成五维的向量,例如,DocA 可以被表示为 {a:1, b:2, c:0, d:2, e:1}。基于这三个五维向量,计算两两之间的余弦相似性(Cosine similarity),最相似的两个向量是:【此题仅一个正确选项】 (10分) A、DocA 和 DocB 的向量
B、DocA 和 DocC 的向量
C、DocB 和 DocC 的向量
D、三个向量两两间的余弦相似性是一样的
10、 有一个画图用的函数库,提供三个API接口:
set_color(color) # 设置画笔颜色。初始画笔颜色为黑色。 move_to(x, y) # 移动画笔到给定的坐标。初始坐标为(0,0)。 line_to(x, y) # 在画笔的当前位置到给定的终点坐标之间画一条线段。
已知每调用set_color函数一次,要支付3元;每调用move_to函数一次,要支付2元;调用line_to函数免费。请问,要从初始状态开始,用这个函数库画出下图,最少支付多少钱就可以完成?(图中,左侧红绿蓝三条线段相互连接,右侧红绿蓝三条线段相互分离)【此题仅一个正确选项】

(10分) A、22元
B、21元
C、19元
D、18元
填空题
11、
一个粗心的发报员在发送莫尔斯电码(Morse Code)的时候,忘记在发送字母和单词之间停顿,结果收报系统收到的是下面这样的一个没有分隔符的点(.)划(-)的序列(请忽略换行符)。
.-.-….-.-…–.-…-….–…-.-…-.–.——..-…-..-.-.—…-..-..—..-..
….–..-.–.-…-.–……-………-..-.—-.-…..-….–.-.-.–.-..—..-….
..-…-..-.–.-.—-……-.–.—–..——-.-.-..—.-.-.–..-.-……………
–…–….–..-….-.—–…..-…——-.-……-………-..-..–.-….-…–
….-.–.-…..–..-…..–..-.—.–…-.-.-..-.-…..—.-.-.-.—-….-..-….
.–..—-……-…-.–.-…–…..–…..-…….-….—..-..–…——-.–…
.—..—…..-.-.-….-.-…–..-….—..–.–…-.-.-..-.-…..—.-.-.-.—-.
…-..-…..–..—-.
已知这份报文的原始内容是一部著名英文小说的片段,请问,这部小说的作者是?请从下方A至H的选项中,选择正确答案的字母序号填入:
(A) Edgar Rice Burroughs
(B) Isaac Asimov
(C) J. K. Rowling
(D) J. R. R. Tolkien
(E) Stephen King
(F) Jack London
(G) Lewis Carroll
(H) H. G. Wells
(25分) 简答题
12、 请写出第11题解题的主要思路,以及解题时使用的主要代码片段: 【不计分,提交的内容为主观答案,保留到面试时供面试官参考】