开发第一个Spark程序
WorldCount程序
一、需求:
对文本文件中的单词个数进行统计
二、步骤:
1.创建一个Spark Context
2. 加载数据
3.把没一行分割成单词
4.转换成键值对并且计数。
三、开发环境
IDEA+Maven, scala 2.11.8, CDH Spark2 2.1.1
四、代码开发
(1)pom.xml,配置如下:
xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0modelVersion>
<groupId>wordCOUNTgroupId>
<artifactId>wordCOUNTartifactId>
<version>1.0-SNAPSHOTversion>
<dependencies>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-core_2.11artifactId>
<version>2.1.1version>
dependency>
dependencies>
project>
(2)scala程序开发,mytest.scala
import org.apache.spark.{SparkConf, SparkContext} /** * Created by ICC17k761 on 2018/5/22. */ object mytest { def main(args:Array[String]) { val conf=new SparkConf().setAppName("wordCount") val sc=new SparkContext(conf) val input=sc.textFile("/data/shellScript/wordcount.txt") //hdfs中的路径 val lines=input.flatMap(line=>line.split(" ")) val count=lines.map(word=>(word,1)).reduceByKey{case(x,y)=>x+y} val output=count.saveAsTextFile("/data/shellScript/output") } }
五、程序打包
1.如何之前有打包过,请先删除如下文件后,重新打包,否则会报错
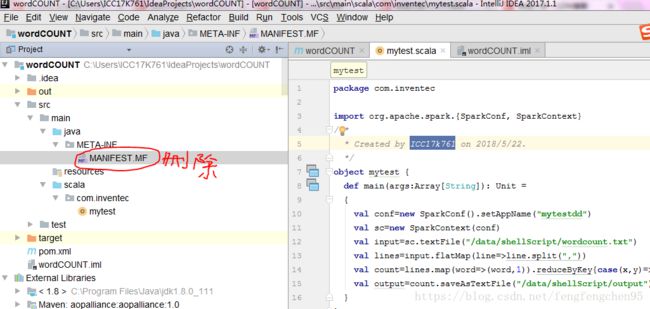
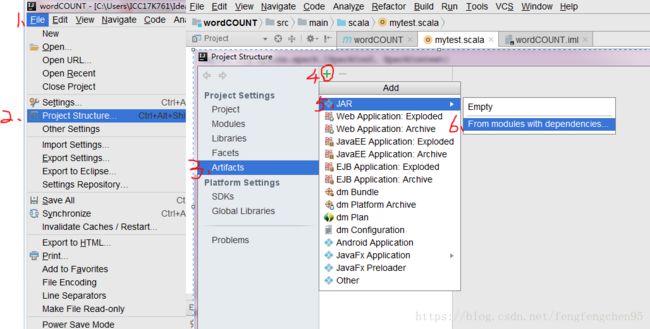
2.打包文件:File--Project Structure--Artifacts---"+"---JAR--From modules with dependencies
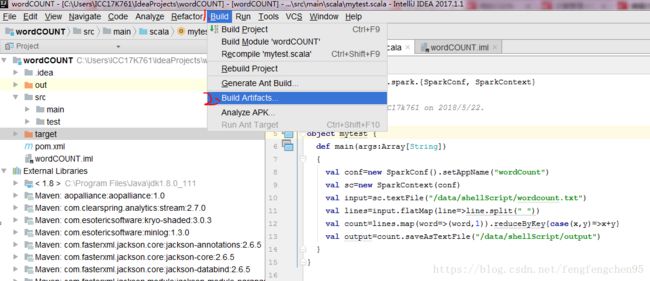
Bulid: Bulid--Bulid Artifacts,在之前选定的目录文件生产.jar文件
七.文件上传:
1.将jar包和wordcount.txt文件上传到linux服务器上述,我使用的Winscp.exe
2.将wordcount.txt上传到hdfs目录:/data/shellScript
Hadoop dfs -put wordcount.txt /data/shellScript/wordcount.txt
八、启动集群:
启动master ./sbin/start-master.sh
启动workder ./bin/spark-class
提交作业 ./bin/spark-submit
因我的环境是CDH spark2(yarn)任务提交如下:
spark2-submit --class com.inventec.mytest /data/shellScript/wordCOUNT.jar --master yarn --deploy-mode cluster --executor-memory 2G --total-executor-cores 4
注意:
scala的版本要和spark中scala提供的版本一致,最开始程序用scala 2.12, spark版本2.1.1对应的scala是2.11.8, 运行程序一直无数据,WARN如下,原因是因为scala版本和spark不一致,将程序改成2.1.1后,运行成功,成功跑出计算结果
WARN scheduler.TaskSetManager: Lost task 0.0 in stage 0.0 (TID 0, ICC-FIS-HADOOP-S3, executor 1): java.lang.NoSuchMethodError: scala.Predef$.refArrayOps([Ljava/lang/Object;)[Ljava/lang/Object;
2. 异常问题2:java.net.BindException: 地址已在使用,因集群上有其它spark任务已占用此端口,Spark会自行分配其它端口执行任务,所有此问题可以忽略。