史上最全阿里 Java 面试题学习笔记一
目录
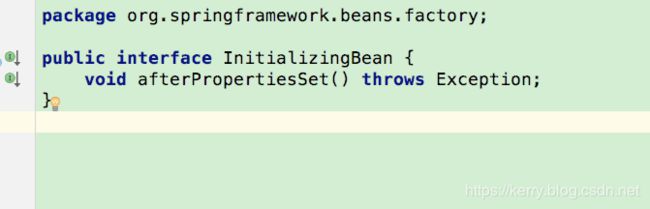
1.@postconstruct @init-method @afterPropertiesSet 顺序
2. JVM常用命令
3.Xss攻击
4.CSRF
5.CORS
6. Mysql索引
7. Mysql事务隔离级别
8. Mysql调优注意事项
8.1 慢查询
9 Mysql 锁研究
9.1 行锁:记录锁(Record Locks)
9.2 间隙锁 [ Gap lock ]: (可重复读隔离级别来解决幻读的问题)
9.3 MVCC
9.4 行锁升级为表锁的情况
10 HashMap
10.1 扩容过程:
10.2 Hashmap为什么长度是2的幂
11 Mysq两种引擎
11.1MyISAM
12 redis原理
13 casandra特点
14. 密码交易安全
15 redis key过大
16. AOP动态代理加反射,静态代理,cglib
17 Volatile
18 CAS算法
19 concurrentHashmap改进
20 有序的map
21 NIO
21.1 Select机制
21.2 Epoll机制
21.3 总结:
22 反射创建对象方式
23 Class.forName和ClassLoader的区别
24 深入ClassLoader
1.为什么要自定义class loader
2.如何打破1双亲委托模式
3.现实应用中打破双亲委托的情况
25 代理实现的三种方式
1.静态代理
2.动态代理
3.CGlib代理
26 Spring AOP 原理
27 JDK1.8新特性
28 Java并行流的实现
29.JVM原理及GC算法
1.CMS收集器(针对老年代,两次stop the world)
2.G1收集器
3.比较一下:
4.JVM回收算法
29 GC类型
30 JVM结构
31 JVM内存分配流程
32 JVM内存溢出
33 JVM重要概念
34 Happens-before规则
35 内存屏障
36 Spring加载流程
37 Spring事务的传播属性
38 线程池
39.Netty线程模型
40.Spring boot启动流程
41.CPU 负载过高排查
42.Voliatile和synchronized
43.线程生命周期
44.Spring单例
45.三个线程输出ABC循环10次
46.原子类原理
47.JUC用过那些并发工具类
48.CAS
49.CountDownLatch
原理
50.ThreadLocal注意点
51 无锁数据结构
52 Countdownlatch和CyclicBarrier
53 AQS
1.AQS的基础CLH队列
2.Volatile和CAS
54 公平锁、非公平锁
55 TCP三次握手
为什么挥手是四次?
Close wait和Time wait
56 页面打开流程
57 长连接
58 HTTPS
59 Session和Cookie
60 分布式唯一ID生成策略
Snowflake算法
UUID
Redis
61 延迟关闭交易
1.@postconstruct @init-method @afterPropertiesSet 顺序
Constructor > @PostConstruct > InitializingBean > init-method
2. JVM常用命令
jmap(JVM Memory Map)命令用于生成heap dump文件
jstack用于生成java虚拟机当前时刻的线程快照。线程快照是当前java虚拟机内每一条线程正在执行的方法堆栈的集合,生成线程快照的主要目的是定位线程出现长时间停顿的原因
3.Xss攻击
xxs攻击 xss表示Cross Site Scripting(跨站脚本攻击),通过插入恶意脚本,实现对用户游览器的控制
假如用户提交的数据含有js代码,不做任何处理就保存到了数据库,读出来的时候这段js代码就变成了可执行的代码,将会产生意向不到的效果。一般用户提交的数据永远被认为是不安全的,在保存之前要做对应的处理。这次我就遇到了这个问题,
我提交的内容,或者百度,读出来的时候,将直接弹出1111,或者百度是有效的超链接,这个显然是不行的。
4.CSRF
CSRF - Cross-Site Request Forgery - 跨站请求伪造
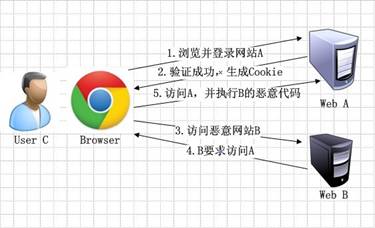
CSRF攻击之所以能够成功,是因为攻击者可以伪造用户的请求,该请求中所有的用户验证信息都存在于Cookie中,因此攻击者可以在不知道这些验证信息的情况下直接利用用户自己的Cookie来通过安全验证。由此可知,抵御CSRF攻击的关键在于:在请求中放入攻击者所不能伪造的信息,并且该信息不存在于Cookie之中。鉴于此,系统开发者可以在HTTP请求中以参数的形式加入一个随机产生的token,并在服务器端建立一个拦截器来验证这个token,如果请求中没有token或者token内容不正确,则认为可能是CSRF攻击而拒绝该请求
5.CORS
SOP就是Same Origin Policy同源策略,指一个域的文档或脚本,不能获取或修改另一个域的文档的属性。也就是Ajax不能跨域访问,我们之前的Web资源访问的根本策略都是建立在SOP上的。它导致很多web开发者很痛苦,后来搞出很多跨域方案,比如JSONP和flash socket
后来出现了CORS-CrossOrigin Resources Sharing,也即跨源资源共享,它定义了一种浏览器和服务器交互的方式来确定是否允许跨域请求。它是一个妥协,有更大的灵活性,但比起简单地允许所有这些的要求来说更加安全。
6. Mysql索引
提升查找速度的关键就在于尽可能少的磁盘I/O,那么可以知道,每个节点中的key个数越多,那么树的高度越小,需要I/O的次数越少,因此一般来说B+Tree比BTree更快,因为B+Tree的非叶节点中不存储data,就可以存储更多的key。
7. Mysql事务隔离级别
事务的隔离级别分为:未提交读(read uncommitted)、已提交读(read committed)、可重复读(repeatable read)、串行化(serializable)
- 脏读:指一个线程中的事务读取到了另外一个线程中未提交的数据。
- 不可重复读(虚读):指一个线程中的事务读取到了另外一个线程中提交的update的数据。
- 幻读:指一个线程中的事务读取到了另外一个线程中提交的insert的数据
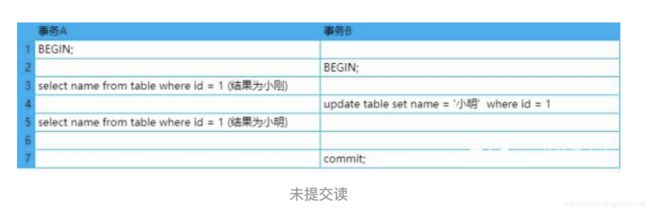
可能出现脏读,幻读,不可重复读
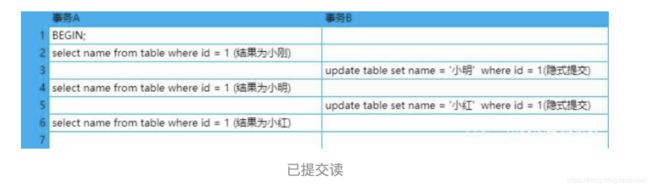
可能出现不可重复读和幻读

可能出现 幻读,和读已提交读区别是,重复读取的值不变!!!
上面三个隔离级别对同一条记录的读和写都可以并发进行,但是串行化格式下就只能进行读-读并发。只要有一个事务操作一条记录的写,那么其他要访问这条记录的事务都得等着
8. Mysql调优注意事项
总体说,三方面: 第一sql语句,第二索引,第三mysql参数
8.1 慢查询
1、查看slowlog,分析slowlog,分析出查询慢的语句。
2、按照一定优先级,进行一个一个的排查所有慢语句。
3、分析top sql,进行explain调试,查看语句执行时间。
4、调整索引或语句本身。
使用explain查看执行情况
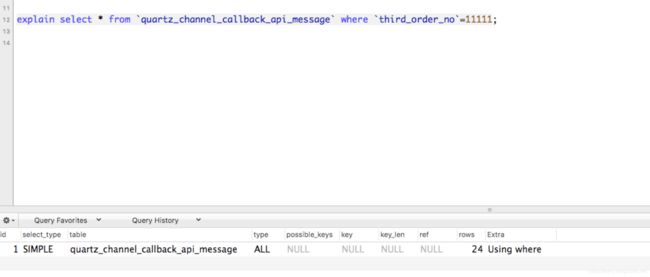
使用索引,根据rows看看查询了多少行,判断是不是有问题,是不是缺少索引。
9 Mysql 锁研究
Mysql默认采用的是可重复读(即repeatable read)隔离级别,并且会以Next-Key Lock的方式(即record lock和gap lock的结合)对数据行进行加锁,这样可以有效防止幻读的发生,但是在平时开发过程中,一些不正确的行为可能会导致间隙锁锁定范围变得很大,线程间互相等待从而导致死锁,下面将提供一些解决思路供大家参考:
9.1 行锁:记录锁(Record Locks)
(1)记录锁, 仅仅锁住索引记录的一行,在单条索引记录上加锁。
(2)record lock锁住的永远是索引,而非记录本身,即使该表上没有任何索引,那么innodb会在后台创建一个隐藏的聚集主键索引,那么锁住的就是这个隐藏的聚集主键索引。
所以说当一条sql没有走任何索引时,那么将会在每一条聚合索引后面加X锁,这个类似于表锁,但原理上和表锁应该是完全不同的
9.2 间隙锁 [ Gap lock ]: (可重复读隔离级别来解决幻读的问题)
在索引记录之间的间隙中加锁,或者是在某一条索引记录之前或者之后加锁,并不包括该索引记录本身。
间隙锁生效:
1. 条件查询,会比如a>1 and a<6那么这个范围都会加间隙所。如果a>3,那么大于3的所有记录都会加间隙锁,甚至包括不存在的记录,为了防止幻读。
2. 如果使用相等条件查询一个不存在的记录,锁住全表,导致其他事务插入阻塞。
比如 select * from where xxx for update. 其中where的条件记录不存在。
再比如 update a set a='11' where b='222' 其中b存在就会全表锁住。为了防止这种情况,b列如果是唯一索引就没有问题,不会升级为全表锁。
间隙锁在InnoDB的唯一作用就是防止其它事务的插入操作,以此来达到防止幻读的发生,所以间隙锁不分什么共享锁与排它锁。如果InnoDB扫描的是一个主键、或是一个唯一索引的话,那InnoDB只会采用行锁方式来加锁,而不会使用Next-Key Lock的方式,也就是说不会对索引之间的间隙加锁。
当我们用范围条件而不是相等条件检索数据,并请求共享或排他锁时,InnoDB会给符合条件的已有数据记录的索引项加锁;对于键值在条件范围内但并不存在的记录,叫做“间隙(GAP)”,InnoDB也会对这个“间隙”加锁,这种锁机制就是所谓的间隙锁(GAP LOCK),间隙锁和行锁合称Next-Key Lock
举例来说,假如user表中只有101条记录,其empid的值分别是 1,2,...,100,101,下面的SQL:
select * from user where user_id > 100 for update;
是一个范围条件的检索,InnoDB不仅会对符合条件的user_id值为101的记录加锁,也会对user_id大于101(这些记录并不存在)的“间隙”加锁。
InnoDB使用间隙锁的目的,一方面是为了防止幻读,以满足相关隔离级别的要求,对于上面的例子,要是不使用间隙锁,如果其他事务插入了user_id大于100的任何记录,那么本事务如果再次执行上述语句,就会发生幻读;另外一方面,是为了满足其恢复和复制的需要
对于select from where for update操作,一定要保证where条件字段的值一定存在,不然可能会导致间隙锁锁定的范围变得很大,阻塞别的事务,也有可能会导致死锁
利用MVCC实现一致性非锁定读,保证在同一个事务中多次读取相同的数据返回的结果是一样的,解决了不可重复读问题.
利用Gap Locks和Next-key可以阻止其他事务在锁定区间内插入数据,解决了幻读问题.
9.3 MVCC
MVCC是通过在每行记录后面保存两个隐藏的列来实现的。这两个列,一个保存了行的创建时间,一个保存行的过期时间(或删除时间)。当然存储的并不是实际的时间值,而是系统版本号(system version number)。每开始一个新的事务,系统版本号都会自动递增。事务开始时刻的系统版本号会作为事务的版本号,用来和查询到的每行记录的版本号进行比较
- 乐观锁机制,解决可重复读
- 每行记录都会保存两个隐藏列,一个是创建时间,一个是过期时间,实际系统版本号,每开启事务都会递增
- 读取时,读取创建时间小于自己的事务id,所以不会读取到事务读取过程中,并发插入的数据
- 读取时,如果别的事务并发修改了同一条记录,则在过期时间记录值是修改的事务id,读取的时候还是读取创建时间小于自己事务id的,不会受到影响,实现了可重复读
- 读取时,如果别的事务删除了同一条记录,则在过期时间记录值是删除的事务id,读取时候也不影响,跟更新一样
https://www.jianshu.com/p/f692d4f8a53e
9.4 行锁升级为表锁的情况
众所周知,MySQL 的 InnoDB 存储引擎支持事务,支持行级锁(innodb的行锁是通过给索引项加锁实现的)。得益于这些特性,数据库支持高并发。如果 InnoDB 更新数据使用的不是行锁,而是表锁呢?是的,InnoDB 其实很容易就升级为表锁,届时并发性将大打折扣了
经过我操作验证,得出行锁升级为表锁的原因之一是: SQL 语句中未使用到索引,或者说使用的索引未被数据库认可(相当于没有使用索引)。未被认可,通常来讲,就是mysql优化器认为直接扫表比索引还快,所以忽略。比如如果一列重复率很高,那么在此列建立索引,会被mysql忽略
10 HashMap
10.1 扩容过程:
- 若threshold(阈值)不为空,table的首次初始化大小为阈值,否则初始化为缺省值大小16
- 默认的负载因子大小为0.75,当一个map填满了75%的bucket时候,就会扩容,扩容后的table大小变为原来的两倍
- 假设扩容前的table大小为2的N次方,有上述put方法解析可知,元素的table索引为其hash值的后N位确定
- 扩容后的table大小即为2的N+1次方,则其中元素的table索引为其hash值的后N+1位确定,比原来多了一位
- 重新调整map的大小,并将原来的对象放入新的bucket数组中。这个过程叫作rehashing
因此,table中的元素只有两种情况:
元素hash值第N+1位为0:不需要进行位置调整
元素hash值第N+1位为1:调整至原索引+old Capacity 位置
扩容或初始化完成后,resize方法返回新的table
10.2 Hashmap为什么长度是2的幂
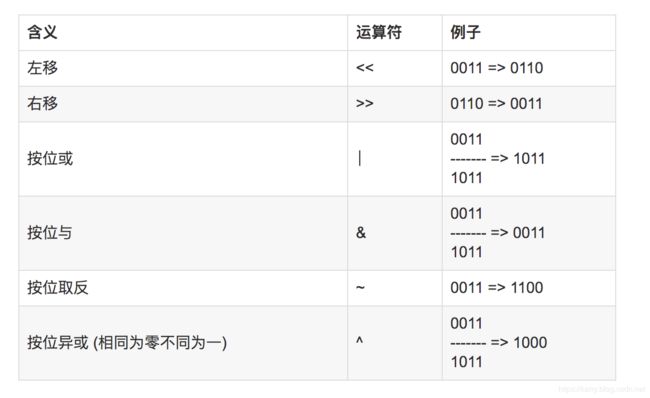
- index=hash&(table.length-1)如果table的长度是2的n次幂,那么table.length-1永远都是1,按照位运算规则,hash值是1,则结果是1,hash值是0,结果是0。如果table.length-1不全部都是1,出现0,那么hash值里面0或者1结果都是0,索引会冲突。
- 2的n次幂,比如长度16,table.length-1结果是15。全部是1,高位自动补充为0.按照位运算的规则,其实结果还是hash值的最后n位。因为高位和0与运算后,都是0。能够快速计算索引位置。length(2的整数次幂)的特殊性导致了length-1的特殊性(二进制全为1)。位运算快于十进制运算,hashmap扩容也是按位扩容
- 既然hash后的索引由最后n位确定,那么hash值的最后n位是否均匀呢?如果只有高位变化了岂不是要冲突。我们看看hashmap计算hash值的方法
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
计算出hash值后,进行异或操作,异或操作的对象是hash值无符号右移动16位,高位全部是0.因为hash值是32位的,这样做的目的异或的对象是hash值的高位,也就是hash值的低16和高16进行异或操作,hash值的高16和“全部为0”进行异或,此部分不变化。很巧妙的把高16的变化反应到hash值结果计算中
- rehash呢?扩容后的table大小即为2的N+1次方,则其中元素的table索引为其hash值的后N+1位确定,比原来多了一位。第n+1位如果是0,索引不变。第n+1位如果是1,调整后索引为=原索引+old capacity

在多线程使用场景中,应该尽量避免使用线程不安全的HashMap,而使用线程安全的ConcurrentHashMap。那么为什么说HashMap是线程不安全的,下面举例子说明在并发的多线程使用场景中使用HashMap可能造成死循环。代码例子如下(便于理解,仍然使用JDK1.7的环境):
public class HashMapInfiniteLoop {
private static HashMap map = new HashMap(2,0.75f);
public static void main(String[] args) {
map.put(5, "C");
new Thread("Thread1") {
public void run() {
map.put(7, "B");
System.out.println(map);
};
}.start();
new Thread("Thread2") {
public void run() {
map.put(3, "A);
System.out.println(map);
};
}.start();
}
}
11 Mysq两种引擎
11.1MyISAM
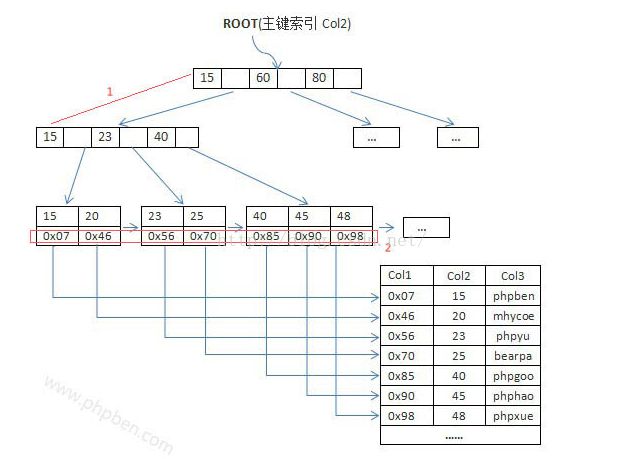
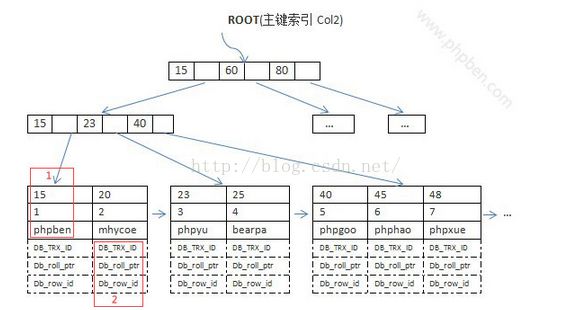
- Myisam的索引是B+tree,但是叶子节点存储的是地址,不是记录,索引和数据文件是分开的,这种叫非聚集索引
- nnoDB引擎索引结构的叶子节点的数据域,存放的就是实际的数据记录(对于主索引,此处会存放表中所有的数据记录;对于辅助索引此处会引用主键,检索的时候通过主键到主键索引中找到对应数据行),或者说,InnoDB的数据文件本身就是主键索引文件,这样的索引被称为“聚簇索引”,一个表只能有一个聚簇索引。
https://www.jianshu.com/p/d0ee1ca57f14
12 redis原理
单线程 IO多路复用
13 casandra特点
14. 密码交易安全
输入
md5(thirdid+inputpwd+idno)
md5[md5(thirdid+inputpwd+idno)+randomkey]
数据库密码其实是md5(thirdid+inputpwd+idno)加上随机数后的结果
15 redis key过大
Redis使用过程中经常会有各种大key的情况, 比如:
- 1: 单个简单的key存储的value很大
- 2: hash, set,zset,list 中存储过多的元素(以万为单位)
由于redis是单线程运行的,如果一次操作的value很大会对整个redis的响应时间造成负面影响,所以,业务上能拆则拆,下面举几个典型的分拆方案。
第一个场景:
单个简单的key存储的value很大-------------分拆为多个key-value存储,减轻IO压力,多个redis intance处理
第二个场景:
hash, set,zset,list 中存储过多的元素
类似于场景一种的第一个做法,可以将这些元素分拆。
以hash为例,原先的正常存取流程是 hget(hashKey, field) ; hset(hashKey, field, value)
现在,固定一个桶的数量,比如 10000, 每次存取的时候,先在本地计算field的hash值,模除 10000, 确定了该field落在哪个key上。
newHashKey = hashKey + (*hash*(field) % 10000);
hset (newHashKey, field, value) ;
hget(newHashKey, field)
16. AOP动态代理加反射,静态代理,cglib
关键点:
Proxy.newProxyInstance(this.target.getClass().getClassLoader(), this.target.getClass().getInterfaces(), this)
- 生成代理对象:注意入参,classloader,代理类的接口,invocation handler实现类。第三个参数就是用来分发方法调用的。
- 定义invocation handler:每个代理对象关联一个 invocation handler
package com.puhui.web.advice;
import com.google.common.base.Strings;
import java.lang.reflect.InvocationHandler;
import java.lang.reflect.Method;
import java.lang.reflect.Proxy;
public class DynaProxyHello1 implements InvocationHandler {
//调用对象
private Object proxy;
//目标对象
private Object target;
public Object bind(Object target, Object proxy) {
this.target = target;
this.proxy = proxy;
return Proxy.newProxyInstance(this.target.getClass().getClassLoader(), this.target.getClass().getInterfaces(), this);
}
@Override
public Object invoke(Object proxy, Method method, Object[] args)
throws Throwable {
Object result = null;
//反射得到操作者的实例
Class clazz = this.proxy.getClass();
//反射得到操作者的Start方法
Method start = clazz.getDeclaredMethod("start", new Class[]{Method.class});
//反射执行start方法
start.invoke(this.proxy, new Object[]{this.proxy.getClass()});
//执行要处理对象的原本方法
method.invoke(this.target, args);
//反射得到操作者的end方法
Method end = clazz.getDeclaredMethod("end", new Class[]{Method.class});
//反射执行end方法
end.invoke(this.proxy, new Object[]{method});
return result;
}
public static void main(String[] args){
IHello proxy=new DynaProxyHello1().bind(new Hello());
}
}
17 Volatile
被volatile修饰的变量有如下特性:
①使得变量更新变得具有可见性,只要被volatile修饰的变量的赋值一旦变化就会通知到其他线程,如果其他线程的工作内存中存在这个同一个变量拷贝副本,那么其他线程会放弃这个副本中变量的值,重新去主内存中获取
②产生了内存屏障,防止指令进行了重排序,关于这点的解释,请看下面一段代码:
package com.brickworkers;
public class VolatileTest {
int a = 0; //1
int b = 1; //2
volatile int c = 2; //3
int d = 3; //4
int e = 4; //5
}
在如上的代码中,因为c变量是用volatile进行修饰,那么就会对该段代码产生一个内存屏障,用以保证在执行语句3的时候语句1和语句2是绝对执行完毕的,而且在执行语句3的时候,语句4和语句5肯定没有执行。同时说明一下,在上述代码中虽然保证了语句3的执行顺序不可变换,但是语句1和语句2,语句4和语句5可能发生指令重排序哦。
总结:volatile修饰的变量具有可见性与有序性。
18 CAS算法
CAS算法
CAS的全称叫“Compare And Swap”,也就是比较与交换,他的主要操作思想是:
首先它具有三个操作数,a、内存位置V,预期值A和新值B。如果在执行过程中,发现内存中的值V与预期值A相匹配,那么他会将V更新为新值A。如果预期值A和内存中的值V不相匹配,那么处理器就不会执行任何操作。CAS算法就是我再技术点中说的“无锁定算法”,因为线程不必再等待锁定,只要执行CAS操作就可以,会在预期中完成。
19 ConcurrentHashmap改进
hashmap在多线程下重哈希(resize)会导致get的时候死循环。JDK 8之前concurrent hashmap采用分段锁的机制。
先简单看下ConcurrentHashMap类在jdk1.7中的设计,其基本结构如图所示:
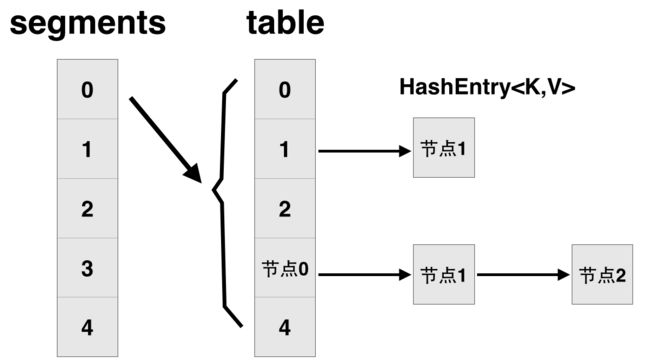
每一个segment都是一个HashEntry
public class ConcurrentHashMap extends AbstractMap
implements ConcurrentMap, Serializable {
// 将整个hashmap分成几个小的map,每个segment都是一个锁;与hashtable相比,这么设计的目的是对于put, remove等操作,可以减少并发冲突,对
// 不属于同一个片段的节点可以并发操作,大大提高了性能
final Segment[] segments;
// 本质上Segment类就是一个小的hashmap,里面table数组存储了各个节点的数据,继承了ReentrantLock, 可以作为互拆锁使用
static final class Segment extends ReentrantLock implements Serializable {
transient volatile HashEntry[] table;
transient int count;
}
// 基本节点,存储Key, Value值
static final class HashEntry {
final int hash;
final K key;
volatile V value;
volatile HashEntry next;
}
}
改进一:取消segments字段,直接采用transient volatile HashEntry
改进二:将原先table数组+单向链表的数据结构,变更为table数组+单向链表+红黑树的结构。对于hash表来说,最核心的能力在于将key hash之后能均匀的分布在数组中。如果hash之后散列的很均匀,那么table数组中的每个队列长度主要为0或者1。但实际情况并非总是如此理想,虽然ConcurrentHashMap类默认的加载因子为0.75,但是在数据量过大或者运气不佳的情况下,还是会存在一些队列长度过长的情况,如果还是采用单向列表方式,那么查询某个节点的时间复杂度为O(n);因此,对于个数超过8(默认值)的列表,jdk1.8中采用了红黑树的结构,那么查询的时间复杂度可以降低到O(logN),可以改进性能。
put方法做了以下几点事情:
1)如果没有初始化就先调用initTable()方法来进行初始化过程
2)如果没有hash冲突就尝试CAS方式插入
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null,
new Node(hash, key, value, null)))
break; // no lock when adding to empty bin
}
3)如果还在进行扩容操作就先帮助其它线程进一起行扩容
4)如果存在hash冲突,就加锁来保证put操作的线程安全。
回顾一下hashmap的put过程:
HashMap在put方法中,它使用hashCode()和equals()方法。当我们通过传递key-value对调用put方法的时候,
1)如果没有初始化,调用resize方法初始化,和ConcurrentHashMap不同的是,initTable是线程安全的
2)HashMap使用Key hashCode()和哈希算法来找出存储key-value对的索引。如果索引处为空,则直接插入到对应的数组中,否则,判断是否是红黑树,若是,则红黑树插入,否则遍历链表,若长度超过8,则将链表转为红黑树,转成功之后 再插入。
20 有序的map
Hashmap和Hashtable 都不是有序的。
TreeMap和LinkedHashmap都是有序的。(TreeMap默认是key升序,LinkedHashmap默认是数据插入顺序)
TreeMap是基于比较器Comparator来实现有序的。
LinkedHashmap是基于链表来实现数据插入有序的
21 NIO
- 比如netty等大量连接产生,连接数量多,但是数据量不大。常见的场景比如聊天软件
- NIO三大组件:buffer,channel和selector。 selector是一个选择复用器。可以监听那些通道可用,并且是读?是写?阻塞期间可以执行其他任务。
- selector的select方法一直调用,判断哪个通道可用。底层原理是利用epoll和kqueue(macos)。Selector不单单是JDK内部批量管理了Channel的状态,更是借用了底层的异步IO实现来支持高并发的客户端连接场景。
- channel是双向通信的,stream是单向的
21.1 Select机制
select的几大缺点:
(1)每次调用select,都需要把fd集合从用户态拷贝到内核态,这个开销在fd很多时会很大
(2)同时每次调用select都需要在内核遍历传递进来的所有fd,这个开销在fd很多时也很大
(3)select支持的文件描述符数量太小了,默认是1024
21.2 Epoll机制
对于第一个缺点,epoll的解决方案在epoll_ctl函数中。每次注册新的事件到epoll句柄中时(在epoll_ctl中指定EPOLL_CTL_ADD),会把所有的fd拷贝进内核,而不是在epoll_wait的时候重复拷贝。epoll保证了每个fd在整个过程中只会拷贝一次。
对于第二个缺点,epoll的解决方案不像select或poll一样每次都把current轮流加入fd对应的设备等待队列中,而只在epoll_ctl时把current挂一遍(这一遍必不可少)并为每个fd指定一个回调函数,当设备就绪,唤醒等待队列上的等待者时,就会调用这个回调函数,而这个回调函数会把就绪的fd加入一个就绪链表)。epoll_wait的工作实际上就是在这个就绪链表中查看有没有就绪的fd(利用schedule_timeout()实现睡一会,判断一会的效果,和select实现中的第7步是类似的)。
对于第三个缺点,epoll没有这个限制,它所支持的FD上限是最大可以打开文件的数目,这个数字一般远大于2048,举个例子,在1GB内存的机器上大约是10万左右,具体数目可以cat /proc/sys/fs/file-max察看,一般来说这个数目和系统内存关系很大
21.3 总结:
(1)select,poll实现需要自己不断轮询所有fd集合,直到设备就绪,期间可能要睡眠和唤醒多次交替。而epoll其实也需要调用epoll_wait不断轮询就绪链表,期间也可能多次睡眠和唤醒交替,但是它是设备就绪时,调用回调函数,把就绪fd放入就绪链表中,并唤醒在epoll_wait中进入睡眠的进程。虽然都要睡眠和交替,但是select和poll在“醒着”的时候要遍历整个fd集合,而epoll在“醒着”的时候只要判断一下就绪链表是否为空就行了,这节省了大量的CPU时间。这就是回调机制带来的性能提升。
(2)select,poll每次调用都要把fd集合从用户态往内核态拷贝一次,并且要把current往设备等待队列中挂一次,而epoll只要一次拷贝,而且把current往等待队列上挂也只挂一次(在epoll_wait的开始,注意这里的等待队列并不是设备等待队列,只是一个epoll内部定义的等待队列)。这也能节省不少的开销。
22 反射创建对象方式
package cn.hncu.reflect.test;
import org.junit.Test;
/**
* 1、演示获取Class c对象的三种方法
*@author lxd
*@version 1.0 2017-4-15 下午2:57:05
*@fileName ReflectGetClass.java
*/
public class ReflectGetClass {
/**
* 法1:通过对象---对象.getClass()来获取c(一个Class对象)
*/
@Test
public void get1(){
Person p=new Person("Jack", 23);
Class c=p.getClass();//来自Object方法
}
/**
* 法2:通过类(类型)---任何数据类型包括(基本数据类型)都有一个静态的属性class ,他就是c 一个Class对象
*/
@Test
public void get2(){
Class c=Person.class;
Class c2=int.class;
}
/**
* 法3:通过字符串(类全名 )---能够实现解耦:Class.forName(str)
*/
@Test
public void get3(){
try {
Class c=Class.forName("cn.hncu.reflect.test.Person");
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
}
23 Class.forName和ClassLoader的区别
@CallerSensitive
public static Class forName(String className)
throws ClassNotFoundException {
Class caller = Reflection.getCallerClass();
return forName0(className, true, ClassLoader.getClassLoader(caller), caller);
}
两种方式的区别:
Class.forName除了将类的.class文件加载到jvm中之外,还会对类进行解释,执行类中的static块。
而classloader只干一件事情,就是将.class文件加载到jvm中,不会执行static中的内容,只有在newInstance才会去执行static块。 forName("")得到的class是已经初始化完成的
loadClass("")得到的class是还没有连接的 一般情况下,这两个方法效果一样,都能装载Class。但如果程序依赖于Class是否被初始化,就必须用Class.forName(name)了。最重要的区别是 forName 会初始化Class,而 loadClass 不会。因此如果要求加载时类的静态变量被初始化或静态块里的代码被执行就只能用 forName,而用 loadClass 只有等创建类实例时才会进行这些初始化。
- Class.forName重载了多个方法,可以指定classloader。默认的方法,从调用者的classloader进行类加载
24 深入ClassLoader
先看一下线上项目用arthas查看classloader的情况,结果如下:
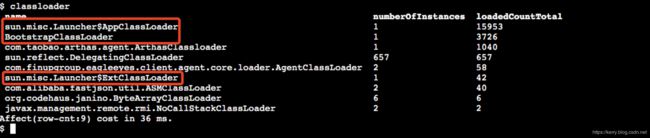
- 当启动一个JVM时,bootstrap 类加载器就会加载java的核心类,例如:rt.jar中的类。bootstrap 类加载器是其他类加载器的parent,它使唯一一个没有parent的类加载器。JAVA_HOME/lib/rt.jar
- Extension class loader加载ext下面的lib,JAVA_HOME/lib/ext/*.jar
- Applicaiton class loader加载用户自定义的lib,在class path环境变量中指定的。
- ExtensionClassLoader 和 AppClassLoader 都是 URLClassLoader 的子类,它们都是从本地文件系统里加载类库,后者是从网络加载类
- AppClassLoader 只负责加载 Classpath 下面的类库,如果遇到没有加载的系统类库怎么办,AppClassLoader 必须将系统类库的加载工作交给 BootstrapClassLoader 和 ExtensionClassLoader 来做,这就是我们常说的「双亲委派」
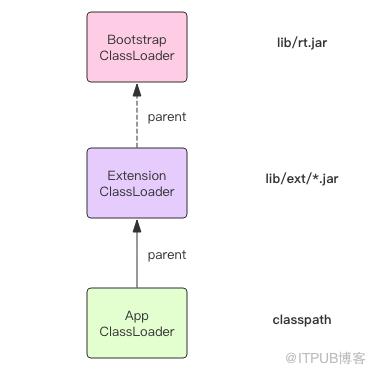
这三个 ClassLoader 之间形成了级联的父子关系,每个 ClassLoader 都很懒,尽量把工作交给父亲做,父亲干不了了自己才会干。每个 ClassLoader 对象内部都会有一个 parent 属性指向它的父加载器
双亲委派规则可能会变成三亲委派,四亲委派,取决于你使用的父加载器是谁,它会一直递归委派到根加载器
双亲委托的好处是:
- 避免重复加载
A和B都需要加载X,各自加载就会导致X加载了两次,JVM中出现两份X的字节码; - 防止恶意加载
编写恶意类java.lang.Object,自定义加载替换系统原生类
1.为什么要自定义class loader
比如发现阿里的fastjson自定义了class loader,我们一起看一下。
ASMClassLoader
- 自定义class loader,如果不想打破双亲委派模型,那么只需要重写findClass方法即可。如果想打破双亲委派模型,那么就重写整个loadClass方法
- 自定义可以实现隔离
- 自定义可以进行额外逻辑处理,比如加解密操作
- spring boot使用了两个类加载器(classloader),对于不会变化的类,比如引入的第三方jar包中的类,加载到一个base classloader中,而开发者实际编写的类,被加载到另一个restart classloader中。当应用重启的时候,整个restart classloader被销毁后重建,而base classloader则保留下来不必再次加载。通过这种方式实现restart效率的提升,模拟了这种方式下的"热部
- 同样的包路径,同样的类名,不在一个classloader里面,也不是一个类
2.如何打破1双亲委托模式
- 自定义类加载器,重写loadClass方法;
- 使用线程上下文类加载器
3.现实应用中打破双亲委托的情况
- JNDI:
双亲委派很好地解决了各个类加载器的基础类的同一问题(越基础的类由越上层的加载器进行加载),基础类之所以称为“基础”,是因为它们总是作为被用户代码调用的API,但世事往往没有绝对的完美。如果基础类又要调用回用户的代码,那该么办?JNDI就是这样,为了解决这个问题,引入了线程上下文类加载器
-
热部署、加解密等功能,自定义classloader
25 代理实现的三种方式
1.静态代理
其实就是组合,被代理对象需要定义接口,代理类也要实现同样的接口,所以会产生很多的代理类
2.动态代理
JDK封装了一层动态代理。
代理对象不需要实现接口,但是目标对象一定要实现接口,否则不能用动态代理。但是有时候目标对象只是一个单独的对象,并没有实现任何的接口,这个时候就可以使用以目标对象子类的方式类实现代理。
public class DynamicProxy {
public static void main(String[] args) {
Singer singer = new Singer();
Object newProxyInstance = java.lang.reflect.Proxy.newProxyInstance(
singer.getClass().getClassLoader(),
singer.getClass().getInterfaces(),
(proxy, method, ar) -> {
System.out.println("22222");
method.invoke(singer, args);
System.out.println("3333");
return null;
});
ISinger i = (ISinger) newProxyInstance;
i.sing();
}
}
class Singer implements ISinger {
public void sing() {
System.out.println("sing");
}
}
interface ISinger {
public void sing();
}
- 代理对象不要求实现接口,但是被代理对象一定要定义接口,具体看Proxy类的newInstance方法,注意指定classloader,不然无法产生代理对象
- 如果被代理对象没有接口,则不能用jdk动态代理,需要利用CGlib,利用子类进行代理。
3.CGlib代理
Cglib代理,也叫作子类代理,它是在内存中构建一个子类对象从而实现对目标对象功能的扩展.
被代理对象不用定义接口。
26 Spring AOP 原理
Spring提供了两种方式来生成代理对象: JDKProxy和Cglib,具体使用哪种方式生成由AopProxyFactory根据AdvisedSupport对象的配置来决定。默认的策略是如果目标类是接口,则使用JDK动态代理技术,否则使用Cglib来生成代理。
AOP 代理则可分为静态代理和动态代理两大类,其中静态代理是指使用 AOP 框架提供的命令进行编译,从而在编译阶段就可生成 AOP 代理类,因此也称为编译时增强;而动态代理则在运行时借助于 JDK 动态代理、CGLIB 等在内存中“临时”生成 AOP 动态代理类,因此也被称为运行时增强。
27 JDK1.8新特性
- default 关键词。java是单根继承,如果已经继承一个类,无法定义抽象类,那么可以利用接口定义default方法实现抽象类的效果。
- Lambda表达式是jdk1.8里面的一个重要的更新,这意味着java也开始承认了函数式编程。
- 日期类,SimpleDateFormat线程不安全,如果设置为静态有问题,如果每次创建销毁性能差。所以1.8引入DataTimeFormatter
- 函数式接口
- HashMap以及Concurrent HashMap优化
- 流:声明式处理集合数据和并行处理,其中并行处理利用fork/join框架
https://www.cnblogs.com/jacksontao/p/8608291.html
28 Java并行流的实现
Fork/Join框架属于并行框架,关于Fork/Join框架的一些内容,可以参考这篇文章:Java Fork/Join并行框架。简单来说,Fork/Join框架可以将大的任务切分为足够小的任务,然后将小任务分配给不同的线程来执行,而线程之间通过工作窃取算法来协调资源,提前昨晚任务的线程可以去“窃取”其他还没有做完任务的线程的任务,而每一个线程都会持有一个双端队列,里面存储着分配给自己的任务,Fork/Join框架在实现上,为了防止线程之间的竞争,线程在消费分配给自己的任务时,是从队列头取任务的,而“窃取”线程则从队列尾部取任务。
Stream API 借助于同样新出现的 Lambda 表达式,极大的提高编程效率和程序可读性。同时它提供串行和并行两种模式进行汇聚操作,并发模式能够充分利用多核处理器的优势,使用 fork/join 并行方式来拆分任务和加速处理过程。通常编写并行代码很难而且容易出错, 但使用 Stream API 无需编写一行多线程的代码,就可以很方便地写出高性能的并发程序。所以说,Java 8 中首次出现的 java.util.stream 是一个函数式语言+多核时代综合影响的产物。
Java 8 的排序、取值实现
List<``Integer``> transactionsIds = transactions.parallelStream().
filter(t -> t.getType() == Transaction.GROCERY).
sorted(comparing(Transaction::getValue).reversed()).
map(Transaction::getId).
collect(toList());
29.JVM原理及GC算法
1.CMS收集器(针对老年代,两次stop the world)
CMS收集器:
1 是一种以获取最短回收停顿时间为目标的收集器。
2 基于“标记-清除”算法实现
3 运作过程如下
1)初始标记
2)并发标记
3)重新标记
4)并发清除
初始标记、重新标记这两个步骤仍然需要“stop the world”。初始标记很快。
4 CMS优缺点
主要优点:并发收集、低停顿。
主要缺点:
1)CMS收集器对CPU资源非常敏感。在并发阶段,它虽然不会导致用户线程停顿,但是会因为占用了一部分线程而导致应用程序变慢,总吞吐量会降低。
2)CMS收集器无法处理浮动垃圾,可能会出现“Concurrent Mode Failure(并发模式故障)”失败而导致Full GC产生。
浮动垃圾:由于CMS并发清理阶段用户线程还在运行着,伴随着程序运行自然就会有新的垃圾不断产生,这部分垃圾出现的标记过程之后,CMS无法在当次收集中处理掉它们,只好留待下一次GC中再清理。这些垃圾就是“浮动垃圾”
3)CMS是一款“标记--清除”算法实现的收集器,容易出现大量空间碎片。当空间碎片过多,将会给大对象分配带来很大的麻烦,往往会出现老年代还有很大空间剩余,但是无法找到足够大的连续空间来分配当前对象,不得不提前触发一次Full GC。
- CMS初始化标记阶段(需要stop the world),这个阶段标记的是由根(root)可直达的对象(也就是root之下第一层对象),标记期间整个应用线程会停止
- 开始并发标记阶段,之前被停止的应用线程会重新启动;从初始化阶段标记的所有可达的对象(root之下第一层队形)出发标记处第一层对象所引用的对象(root之下第二层、三层等等)。
- 预清理也属于并发处理阶段。这个阶段主要并发查找在做并发标记阶段时从年轻代晋升到老年代的对象或老年代新分配的对象(大对象直接进入老年代)或发生变化的线程(mutators)更新的对象,来减少重新标记阶段的工作量。
- 重新标记阶段,会发生stop the world。最后标记老年代所有存活对象(包括在并发阶段创建或修改的对象),因为之前的并发标记和并发预清理阶段都是和应用线程并发进行的,所以可能有遗漏对象,这个阶段会保证标记到所有对象。
- 开始并发清理所有未标记或已终结的对象
CMS收集器在Minor GC时会暂停所有的应用线程,并以多线程的方式进行垃圾回收。在Full GC时不再暂停应用线程,而是使用若干个后台线程定期的对老年代空间进行扫描,及时回收其中不再使用的对象。
PS:开启CMS收集器的方式
-XX:+UseParNewGC -XX:+UseConcMarkSweepGC
2.G1收集器
老式垃圾回收器(Serial,Parallel,CMS)统一将java堆分成大小固定的三部分:新生代、老年代和永久代。所有内存对象最终都保存在这三个区域内。G1收集器将java堆均分成大小相同的区域(region,1M-32M,最多2000个,最大支持堆内存64G)。一个或多个不连续的区域共同组成eden、survivor或old区,但大小不再固定,这为内存应用提供了极大地弹性。G1垃圾收集过程与CMS类似。G1在堆内存中并发地对所有对象进行标记,决定对象的可达性。经过全局标记,G1了解哪些区域几乎是空的,然后优先收集这些区域,这就是GarbageFirst的命名由来。G1将垃圾收集和内存整理活动专注于那些几乎全是垃圾的区域,并建立停顿预测模型来决定每次GC时回收哪些区域,以满足用户设定的停顿时间。
对于区域的回收通过复制算法实现。在完成标记清理后,G1将这几个区域的存活对象复制到一个单独区域中,实现内存整理和空间释放。这一过程通过多线程并行进行来降低停顿时间,提高吞吐量。通过这样的方式,G1在每次GC过程中持续清理碎片,控制停顿时间满足用户要求。这时过去虚拟机无法做到的。CMS不清理内存碎片(除非通过虚拟机参数设置,在每次或多次FullGC后进行整理),ParallelOld进行全堆整理,会导致较长的停顿时间。
G1不是实时垃圾收集器,它会尽量让停顿时间低于用户设置的停顿时间目标但不能保证一定如此。G1根据历史垃圾收集监测数据来 预测每个区域的回收时间,然后根据用户设定的目标停顿时间决定每次GC时可以回收哪些区域。G1通过这种方式建立比较精确的区域回收时间预测模型
3.比较一下:
- CMS是基于标记-清楚算法的,会产生内存碎片。CMS采用并发收集,低停顿
- 为了改进,下一代垃圾收集器采用G1算法。G1算法不区分新生代,老年代,整体看是采用标记-整理算法。局部看采用复制算法,不会产生内存碎片。
- 在标记清除造成内存碎片,最终可能引发full gc是非常不可控的
- G1的停顿时间可控,吞吐量高
- G1,全称为Grabage First,建立回收预测模型,在指定的停顿时间内,计算可以回收哪些区域。所以G1不是实时回收。他的优势一个是建立了停顿预测模型。另外一个,不区分新生代、老年代、永久代,统一分为region,每次回收若干个region,优先回收垃圾对象比较多的区域,所以这个区域可以采用复制算法(复制算法:把存活的对象复制到新的区域,旧的区域进行回收,所以适用于存活对象较少的情况下;标记-清除和标记-整理基本一样,区别就是是否产生内存碎片,都适用于存活对象较多的情况)。最后若干个区域再进行标记-整理算法处理。
G1的设计初衷是为用户提供大内存、低GC停顿时间的应用解决方案。这意味着堆内存6G或更大,停顿时间稳定且少于0.5秒。
如果应用正在使用CMS或ParallelOld且面临以下问题,推荐将应用迁移至G1
- FullGC发生频繁或总时间过长
- 对象分配率或对象升级至老年代的比例波动较大
- 较长的垃圾收集或内存整理停顿(大于0.5至1秒)
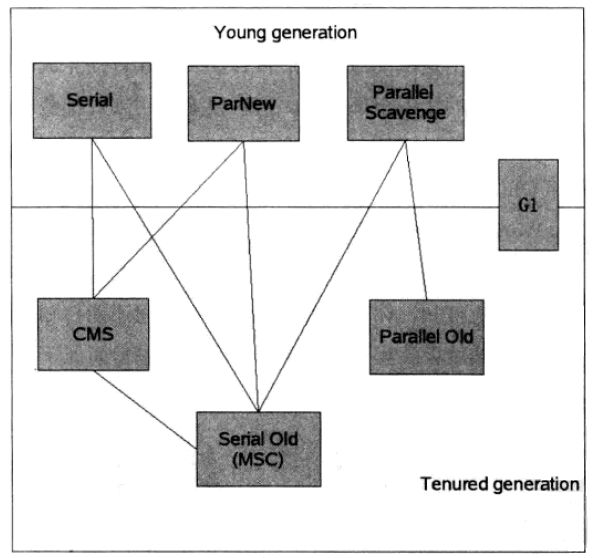
- G1 不区分年轻代、年老代等分区
- CMS只适用于年老代,一般搭配ParNew使用
4.JVM回收算法
对象存活判断:根据强引用,不是弱引用,软引用
- 引用计数法:无非解决循环引用问题
- 可达性分析:离散数学-图论知识
回收算法:
- 复制算法
- 标记-清除
- 标记-整理
分代收集----划分为young、old区,根据不同的区采取不同的算法,比如young区采用复制算法,old区采用标记整理或者标记-清除算法
CMS-并发收集
G1-----Garbage First 收集,分region,停顿时间基本可控
29 GC类型
大多数情况下,对象在新生代中 eden 区分配。当 eden 区没有足够空间进行分配时,虚拟机将发起一次Minor GC。
新生代GC(Minor GC):指发生新生代的的垃圾收集动作,Minor GC非常频繁,回收速度一般也比较快。
老年代GC(Major GC/Full GC):指发生在老年代的GC,出现了Major GC经常会伴随至少一次的Minor GC(并非绝对),Major GC的速度一般会比Minor GC的慢10倍以上
吞吐量=(用户代码的执行时间) / (用户代码的执行时间 + 垃圾收集时间)
吞吐量和响应优先的垃圾收集器选择,所在项目常用的垃圾回收器有两种:
1.Parallel Scavenge + Parallel Old;(又称吞吐量优先,新生代收集器,复制算法,并行收集,面向吞吐量要求,适合做后台的运算),Parallel old 是Parallel Scavenge的老年代版本,标记-整理算法注重吞吐量及cpu资源敏感环境
2.CMS+ParNew;(又称并发标记清除,能降低停顿的时间,适合做前台交互,以提供更快的相应)
CMS和Parallel Scavenge无非共用,CMS等收集器的关注点是尽可能地缩短垃圾收集时,用户线程的停顿时间,而Parallel Scavenge收集器的目的则是达到一个可控制的吞吐量
30 JVM结构
方法区:类信息,构造方法,静态变量等等信息,属于GC回收区域,存活在老年代,因为不经常变化,所有线程共享
堆:新建对象,属于GC回收区域,所有线程共享。
本地方法栈:natvie方法,线程私有
JVM栈:线程私有,方法的堆栈情况
31 JVM内存分配流程
- 先分配对象到Eden,如果Eden放不下,进行Minor GC,清除无用对象,复制对象到From区(S0、S1其中一个,相对到概念,始终有一个S区是空的)
- 如果Eden和From区都容不下新的对象,触发Minor GC。清理Eden区和From区,移动存活对象到To区
- 如果对象在移动过程中在To区放不下,直接放入老年代。假设新创建的对象很大,比如为5M(这个值可以通过PretenureSizeThreshold这个参数进行设置,默认3M),那么即使Eden区有足够的空间来存放,也不会存放在Eden区,而是直接存入老年代;此外,如果对象在Eden出生并且经过1次Minor GC后仍然存活,并且能被To区容纳,那么将被移动到To区,并且把对象的年龄设置为1,对象没"熬过"一次Minor GC(没有被回收,也没有因为To区没有空间而被移动到老年代中),年龄就增加一岁,当它的年龄增加到一定程度(默认15岁,配置参数-XX:MaxTenuringThreshold),就会被晋升到老年代中。还有一种情况,如果在From空间中,相同年龄所有对象的大小总和大于From和To空间总和的一半,那么年龄大于等于该年龄的对象就会被移动到老年代,而不用等到15岁(默认)
32 JVM内存溢出
内存溢出的几种情况:
- 内存中加载的数据量过于庞大,如一次从数据库取出过多数据;
- 集合类中有对对象的引用,使用完后未清空,使得JVM不能回收;
- 代码中存在死循环或循环产生过多重复的对象实体;
- 使用的第三方软件中的BUG;
- 启动参数内存值设定的过小;
查看JVM内存情况:jmap -heap `pgrep java`,后面其实是取出pid
sh-4.1# jmap -heap `pgrep java`
Attaching to process ID 1, please wait...
Debugger attached successfully.
Server compiler detected.
JVM version is 25.92-b14
using parallel threads in the new generation.
using thread-local object allocation.
Concurrent Mark-Sweep GC
Heap Configuration:
MinHeapFreeRatio = 40
MaxHeapFreeRatio = 70
MaxHeapSize = 2147483648 (2048.0MB)
NewSize = 268435456 (256.0MB)
MaxNewSize = 268435456 (256.0MB)
OldSize = 1879048192 (1792.0MB)
NewRatio = 2
SurvivorRatio = 8
MetaspaceSize = 268435456 (256.0MB)
CompressedClassSpaceSize = 1073741824 (1024.0MB)
MaxMetaspaceSize = 268435456 (256.0MB)
G1HeapRegionSize = 0 (0.0MB)
Heap Usage:
New Generation (Eden + 1 Survivor Space):
capacity = 241631232 (230.4375MB)
used = 210217296 (200.4788360595703MB)
free = 31413936 (29.958663940429688MB)
86.99922367651546% used
Eden Space:
capacity = 214827008 (204.875MB)
used = 201866032 (192.5144500732422MB)
free = 12960976 (12.360549926757812MB)
93.9667846605209% used
From Space:
capacity = 26804224 (25.5625MB)
used = 8351264 (7.964385986328125MB)
free = 18452960 (17.598114013671875MB)
31.156522195904646% used
To Space:
capacity = 26804224 (25.5625MB)
used = 0 (0.0MB)
free = 26804224 (25.5625MB)
0.0% used
concurrent mark-sweep generation:
capacity = 1879048192 (1792.0MB)
used = 128886120 (122.9153823852539MB)
free = 1750162072 (1669.084617614746MB)
6.859117320605686% used
46547 interned Strings occupying 5631608 bytes
利用jstat 进行监控:
sh-4.1# jstat -gccapacity `pgrep java`
NGCMN NGCMX NGC S0C S1C EC OGCMN OGCMX OGC OC MCMN MCMX MC CCSMN CCSMX CCSC YGC FGC
262144.0 262144.0 262144.0 26176.0 26176.0 209792.0 1835008.0 1835008.0 1835008.0 1835008.0 0.0 1142784.0 105600.0 0.0 1048576.0 13184.0 46 0
sh-4.1# jstat -gcold `pgrep java`
MC MU CCSC CCSU OC OU YGC FGC FGCT GCT
105600.0 103411.3 13184.0 12682.1 1835008.0 160268.2 46 0 0.000 2.182
jmap导出内存快照,然后用MAT或者JvisualVM进行分析。
sh-4.1# jmap -dump:format=b,file=20190703.dump `pgrep java`
Dumping heap to /data/20190703.dump ...
Heap dump file created
33 JVM重要概念
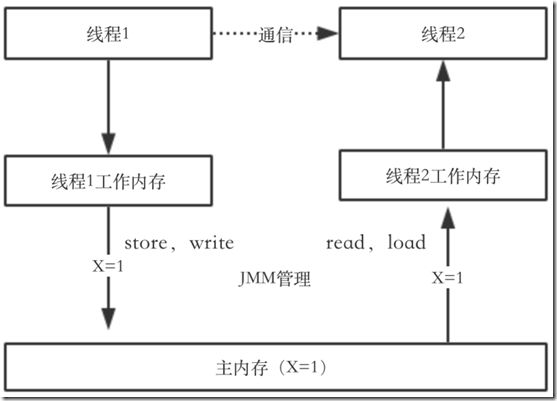
- 指令重排序:不影响执行结果的情况下,JVM对指令进行重排序。多线程情况下,不一定是按照代码对逻辑顺序执行
- volatile: 两件事件:线程一强制写到主内存,线程二线程内存变量强制失效,必须从主内存读取,保证可见性。另外volatile标示的变量可以阻止指令重排序。
- 在保证可见性方面,锁(包括显式锁、对象锁)以及对原子变量的读写都可以确保变量的可见性。但是实现方式略有不同,例如同步锁保证得到锁时从内存里重新读入数据刷新缓存,释放锁时将数据写回内存以保数据可见,而volatile变量干脆都是读写内存
- 第二条和第三条就是happens-before规则对其中两条
34 Happens-before规则
① 程序次序法则:线程中的每个动作A都happens-before于该线程中的每一个动作B,其中,在程序中,所有的动作B都能出现在A之后。
② 监视器锁法则:对一个监视器锁的解锁 happens-before于每一个后续对同一监视器锁的加锁。
③ volatile变量法则:对volatile域的写入操作happens-before于每一个后续对同一个域的读写操作。
④ 线程启动法则:在一个线程里,对Thread.start的调用会happens-before于每个启动线程的动作。
⑤ 线程终结法则:线程中的任何动作都happens-before于其他线程检测到这个线程已经终结、或者从Thread.join调用中成功返回,或Thread.isAlive返回false。
⑥ 中断法则:一个线程调用另一个线程的interrupt happens-before于被中断的线程发现中断。
⑦ 终结法则:一个对象的构造函数的结束happens-before于这个对象finalizer的开始。
⑧ 传递性:如果A happens-before于B,且B happens-before于C,则A happens-before于C
35 内存屏障
内存屏障有两个能力:
1. 阻止屏障两边的指令重排序
2. 强制把写缓冲区/高速缓存中的脏数据等写回主内存,让缓存中相应的数据失效
对Load Barrier来说,在读指令前插入读屏障,可以让高速缓存中的数据失效,重新从主内存加载数据
对Store Barrier来说,在写指令之后插入写屏障,能让写入缓存的最新数据写回到主内存
简单理解一下,以为JVM会进行指令重排序,但是为了不影响结果,保证重排序后结果一直,在影响逻辑的地方需要插入内存屏障,防止屏障两侧代码进行重排序。
另外,读屏障,保证缓冲区数据失效,强制从主内存加载数据。写屏障,保证写入缓存的数据写到主内存,保证可见性。
其实Volatile就是利用这个原理。
36 Spring加载流程
https://www.processon.com/view/link/59812124e4b0de2518b32b6e
37 Spring事务的传播属性
spring事务:
什么是事务:
事务逻辑上的一组操作,组成这组操作的各个逻辑单元,要么一起成功,要么一起失败.
事务特性(4种):
原子性 (atomicity):强调事务的不可分割.
一致性 (consistency):事务的执行的前后数据的完整性保持一致.
隔离性 (isolation):一个事务执行的过程中,不应该受到其他事务的干扰
持久性(durability) :事务一旦结束,数据就持久到数据库
如果不考虑隔离性引发安全性问题:
脏读 :一个事务读到了另一个事务的未提交的数据
不可重复读 :一个事务读到了另一个事务已经提交的 update 的数据导致多次查询结果不一致.
虚幻读 :一个事务读到了另一个事务已经提交的 insert 的数据导致多次查询结果不一致.
解决读问题: 设置事务隔离级别(5种)
DEFAULT 这是一个PlatfromTransactionManager默认的隔离级别,使用数据库默认的事务隔离级别.
未提交读(read uncommited) :脏读,不可重复读,虚读都有可能发生
已提交读 (read commited):避免脏读。但是不可重复读和虚读有可能发生
可重复读 (repeatable read) :避免脏读和不可重复读.但是虚读有可能发生.
串行化的 (serializable) :避免以上所有读问题.
Mysql 默认:可重复读
Oracle 默认:读已提交
read uncommited:是最低的事务隔离级别,它允许另外一个事务可以看到这个事务未提交的数据。
read commited:保证一个事物提交后才能被另外一个事务读取。另外一个事务不能读取该事物未提交的数据。
repeatable read:这种事务隔离级别可以防止脏读,不可重复读。但是可能会出现幻象读。它除了保证一个事务不能被另外一个事务读取未提交的数据之外还避免了以下情况产生(不可重复读)。
serializable:这是花费最高代价但最可靠的事务隔离级别。事务被处理为顺序执行。除了防止脏读,不可重复读之外,还避免了幻象读(避免三种)。
事务的传播行为
PROPAGION_XXX :事务的传播行为
* 保证同一个事务中
PROPAGATION_REQUIRED 支持当前事务,如果不存在 就新建一个(默认)
PROPAGATION_SUPPORTS 支持当前事务,如果不存在,就不使用事务
PROPAGATION_MANDATORY 支持当前事务,如果不存在,抛出异常
* 保证没有在同一个事务中
PROPAGATION_REQUIRES_NEW 如果有事务存在,挂起当前事务,创建一个新的事务
PROPAGATION_NOT_SUPPORTED 以非事务方式运行,如果有事务存在,挂起当前事务
PROPAGATION_NEVER 以非事务方式运行,如果有事务存在,抛出异常
PROPAGATION_NESTED 如果当前事务存在,则嵌套事务执行
38 线程池
/*
* Proceed in 3 steps:
*
* 1. If fewer than corePoolSize threads are running, try to
* start a new thread with the given command as its first
* task. The call to addWorker atomically checks runState and
* workerCount, and so prevents false alarms that would add
* threads when it shouldn't, by returning false.
*
* 2. If a task can be successfully queued, then we still need
* to double-check whether we should have added a thread
* (because existing ones died since last checking) or that
* the pool shut down since entry into this method. So we
* recheck state and if necessary roll back the enqueuing if
* stopped, or start a new thread if there are none.
*
* 3. If we cannot queue task, then we try to add a new
* thread. If it fails, we know we are shut down or saturated
* and so reject the task.
*/
int c = ctl.get();
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
else if (!addWorker(command, false))
reject(command);
- 如果线程数小于core pool size,启动新的线程
- 如果大于core pool size,加入工作队列,重新检测是否可以启动线程,因为刚才的线程可能死掉了,如果检测线程数为0,则启动新的线程,并且启动的边界是maxPoolSize。
- 如果加入队列失败,尝试启动新的线程,在max size pool范围内,如果失败,就拒绝
* @param corePoolSize the number of threads to keep in the pool, even
* if they are idle, unless {@code allowCoreThreadTimeOut} is set
* @param maximumPoolSize the maximum number of threads to allow in the
* pool
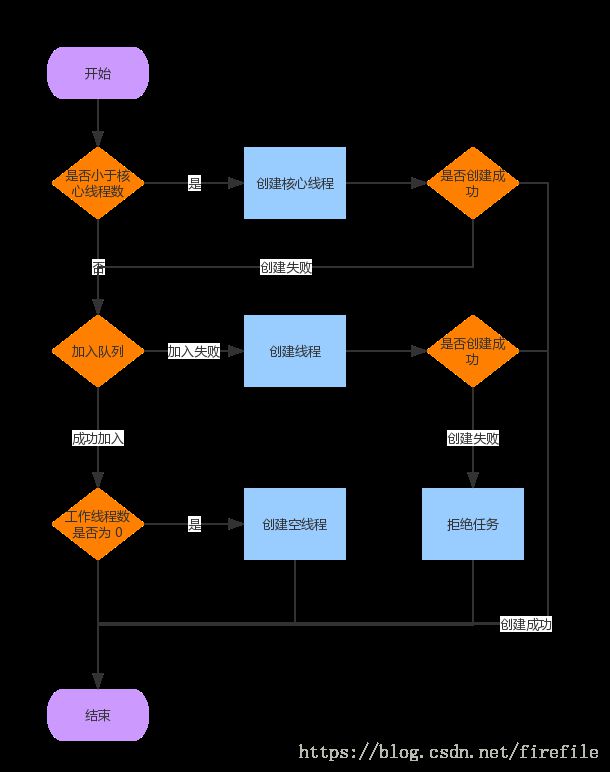
线程池的队列一定设置为有界队列,否则最大线程数不起作用。无界队列就是不设置上限大小,一直添加成功,直到内存不够。
39.Netty线程模型
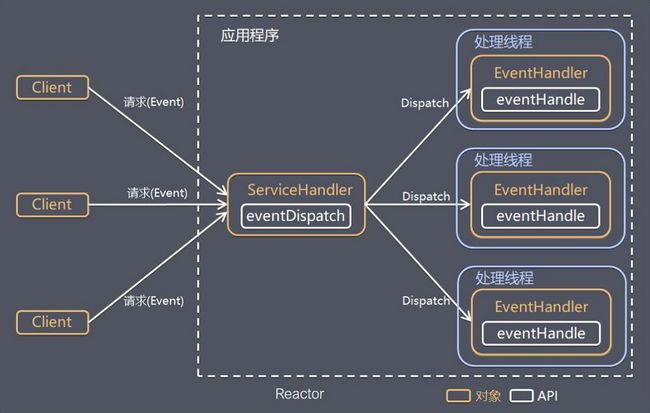
请求处理模型,其实无非两种,一种是请求/轮询方式,一个是事件驱动方式。传统IO是轮询方式,比如linux的select函数。后来采用性能高效的epoll函数就是事件驱动的机制。
http://www.sohu.com/a/272879207_463994
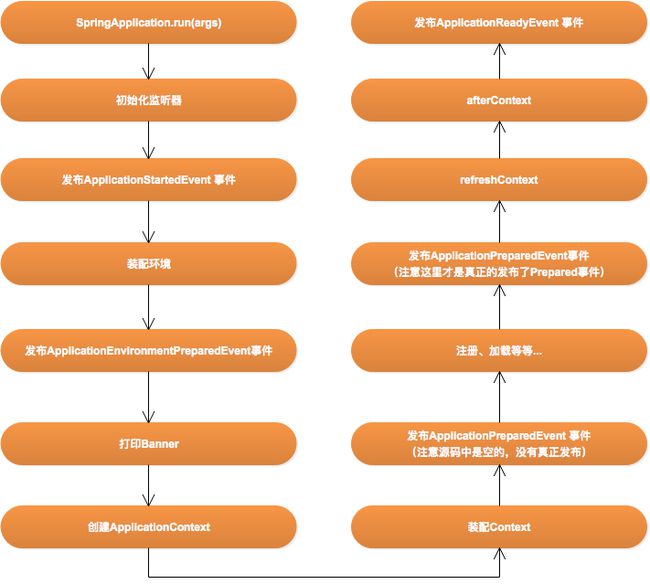
40.Spring boot启动流程
Select,poll和epoll
(1)select==>时间复杂度O(n)
它仅仅知道了,有I/O事件发生了,却并不知道是哪那几个流(可能有一个,多个,甚至全部),我们只能无差别轮询所有流,找出能读出数据,或者写入数据的流,对他们进行操作。所以select具有O(n)的无差别轮询复杂度,同时处理的流越多,无差别轮询时间就越长。
(2)poll==>时间复杂度O(n)
poll本质上和select没有区别,它将用户传入的数组拷贝到内核空间,然后查询每个fd对应的设备状态, 但是它没有最大连接数的限制,原因是它是基于链表来存储的.
(3)epoll==>时间复杂度O(1)
41.CPU 负载过高排查
- 查消耗cpu最高的进程Pid ,利用top命令,查找cpu过高的进程
- 根据Pid查出消耗cpu最高的线程号
top -Hp pid可以查看某个进程的线程信息
-H 显示线程信息,-p指定pid
- 根据线程号查出对应的java线程,进行处理。 jstack [-l]
得到堆栈信息,线程id记得转为16进制
42.Voliatile和synchronized
线程安全性包括两个方面,①可见性。②原子性。
从上面自增的例子中可以看出:仅仅使用volatile并不能保证线程安全性。而synchronized则可实现线程的安全性
43.线程生命周期
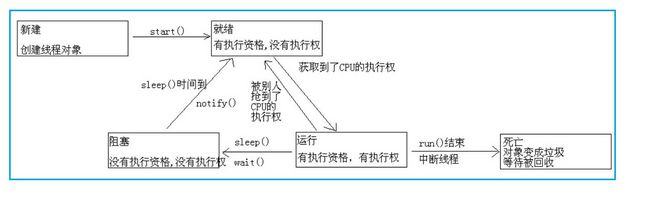
Thread.Sleep(0) 并非是真的要线程挂起0毫秒,意义在于这次调用Thread.Sleep(0)的当前线程确实的被冻结了一下,让其他线程有机会优先执行。
Thread.Sleep(0) 是你的线程暂时放弃cpu,也就是释放一些未用的时间片给其他线程或进程使用,就相当于一个让位动作
44.Spring单例
实质上这种理解是错误的,Java里有个API叫做ThreadLocal,spring单例模式下用它来切换不同线程之间的参数。用ThreadLocal是为了保证线程安全,实际上ThreadLoacal的key就是当前线程的Thread实例。单例模式下,spring把每个线程可能存在线程安全问题的参数值放进了ThreadLocal。这样虽然是一个实例在操作,但是不同线程下的数据互相之间都是隔离的,因为运行时创建和销毁的bean大大减少了,所以大多数场景下这种方式对内存资源的消耗较少,而且并发越高优势越明显。
总的来说就是,单利模式因为大大节省了实例的创建和销毁,有利于提高性能,而ThreadLocal用来保证线程安全性。
另外补充说一句,单例模式是spring推荐的配置,它在高并发下能极大的节省资源,提高服务抗压能力。spring IOC的bean管理器是“绝对的线程安全”
45.三个线程输出ABC循环10次
package org.shopping.mall.loan.web.server;
public class MyTest1 {
private static Boolean flagA = true;
private static Boolean flagB = false;
private static Boolean flagC = false;
public static void main(String[] args) {
final Object lock = new Object();
Thread aThread = new Thread(new Runnable() {
@Override
public void run() {
for (int i = 0; i < 10; ) {
synchronized (lock) {
if (flagA) {
//线程A执行
System.out.println("A");
flagA = false;
flagB = true;
flagC = false;
lock.notifyAll();
i++;
} else {
try {
lock.wait();
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
}
}
});
Thread bThread = new Thread(new Runnable() {
@Override
public void run() {
for (int i = 0; i < 10; ) {
synchronized (lock) {
if (flagB) {
//线程执行
System.out.println("B");
flagA = false;
flagB = false;
flagC = true;
lock.notifyAll();
i++;
} else {
try {
lock.wait();
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
}
}
});
Thread cThread = new Thread(new Runnable() {
@Override
public void run() {
for (int i = 0; i < 10; ) {
synchronized (lock) {
if (flagC) {
//线程执行
System.out.println("C");
flagA = true;
flagB = false;
flagC = false;
lock.notifyAll();
i++;
} else {
try {
lock.wait();
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
}
}
});
cThread.start();
bThread.start();
aThread.start();
}
}
46.原子类原理
CAS+Volatile
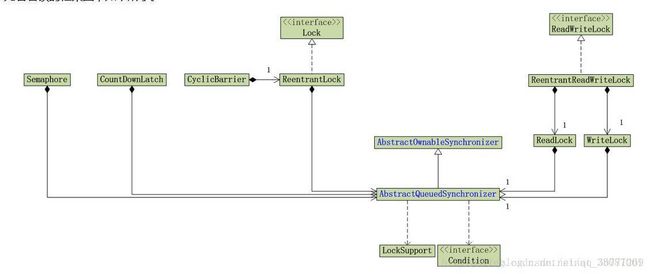
47.JUC用过那些并发工具类
48.CAS
cas操作存在ABA问题,值虽然和原来一样,但是其实已经被修改。如果解决?不能只是比较值,可以增加版本号。利用乐观锁实现
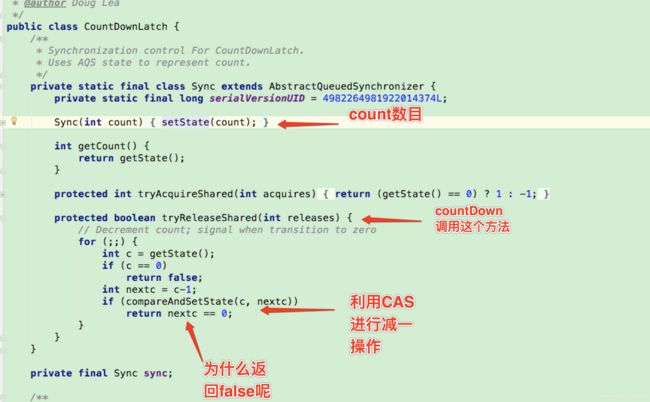
49.CountDownLatch
- 对于CountDownLatch来说,重点是那个“一个线程”, 是它在等待, 而另外那N的线程在把“某个事情”做完之后可以继续等待,可以终止。而对于CyclicBarrier来说,重点是那N个线程,他们之间任何一个没有完成,所有的线程都必须等待。
- Countdownlatch不能重新开始,只能重置
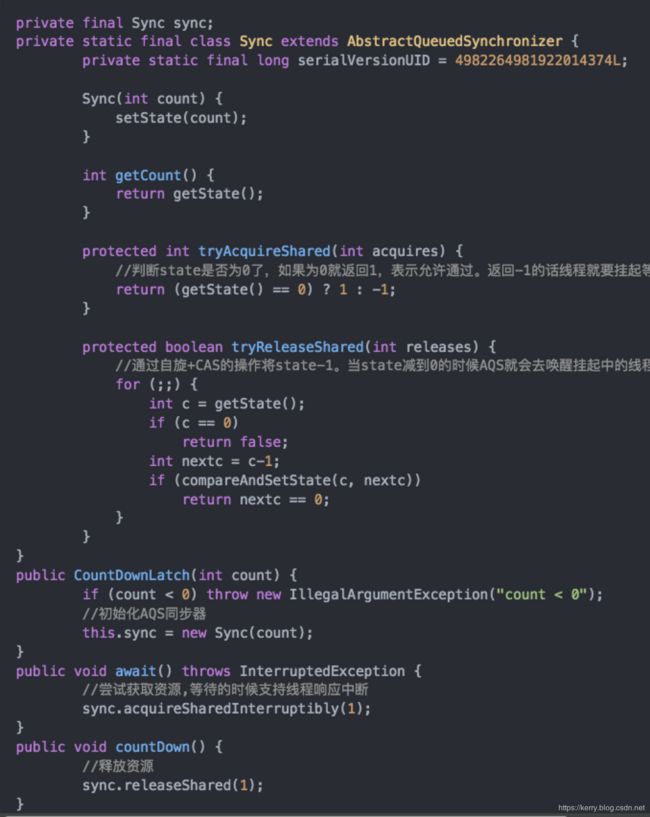
原理
- CountdownLatch内部实现是一个Sync类,其继承了AQS,实现原理是CAS+自旋
- AQS是一个抽象同步队列。主要方法如下,线程安全是基于CAS实现的
/**
* CAS head field. Used only by enq.
*/
private final boolean compareAndSetHead(Node update) {
return unsafe.compareAndSwapObject(this, headOffset, null, update);
}
/**
* CAS tail field. Used only by enq.
*/
private final boolean compareAndSetTail(Node expect, Node update) {
return unsafe.compareAndSwapObject(this, tailOffset, expect, update);
}
/**
* CAS waitStatus field of a node.
*/
private static final boolean compareAndSetWaitStatus(Node node,
int expect,
int update) {
return unsafe.compareAndSwapInt(node, waitStatusOffset,
expect, update);
}
/**
* CAS next field of a node.
*/
private static final boolean compareAndSetNext(Node node,
Node expect,
Node update) {
return unsafe.compareAndSwapObject(node, nextOffset, expect, update);
}
public void await() throws InterruptedException {
sync.acquireSharedInterruptibly(1);
}
await:尝试获取资源,代码主要逻辑是判断state是否为0,如果为0,则可以继续,如果state不为0,则把当前线程构建node,加入队列等待。
countdown:自旋判断(就是for一直循环),判断是否是0,是0,中断不需要进行。如果不是0,进行CAS操作进行减1.如果减去1之后的nextc是0,unblock所有的等待线程
https://www.jianshu.com/p/de164687c880
50.ThreadLocal注意点
- Threadlocal内部是个hashmap,解决hash冲突依赖线性探测,不是链表的方式
- ThreadLocal申明为private static final。
- ThreadLocal使用后务必调用remove方法。
- 多线程处理中,先remove,然后set,保存需要隔离的数据
final ExecutorService pool = Executors.newFixedThreadPool(10);
String channelCode = ChannelContext.getChannelConfig().getChannelCode();
CompletableFuture> c1 = CompletableFuture.supplyAsync(() -> {
ChannelContext.removeAll();
ChannelContext.setChannelConfigData(channelConfig);
return saveSdkInfo("contacts", bldSaveLoanInfoRequest, user, channelCode);
}, pool).whenComplete((v, e) -> {
if (e != null) {
logger.error("saveSdkInfo contacts", e);
throw new RuntimeException(e);
}
}).exceptionally(e -> {
logger.error("saveSdkInfo contacts", e);
throw new RuntimeException(e);
});
package com.puhui.common.channelconfig.session;
import com.puhui.common.channelconfig.entity.ChannelConfig;
/**
* @author : banxiaohua
* @date : 2019/4/1 7:13 PM
*/
public class ChannelContext {
/**
* 渠道信息
*/
private static ThreadLocal CHANNEL_CONFIG_DATA = new ThreadLocal<>();
/**
* 设置渠道配置
* @param channelConfigData channelConfigData
*/
public static void setChannelConfigData(ChannelConfig channelConfigData) {
CHANNEL_CONFIG_DATA.set(channelConfigData);
}
/**
* 获取渠道配置
* @return ChannelConfig
*/
public static ChannelConfig getChannelConfig() {
return CHANNEL_CONFIG_DATA.get();
}
/**
* 获取渠道id
* @return Long
*/
public static Integer getChannelId() {
return CHANNEL_CONFIG_DATA.get().getId();
}
/**
* remove
*/
public static void removeAll() {
CHANNEL_CONFIG_DATA.remove();
}
}
51 无锁数据结构
以上基本上就是所有的无锁队列的技术细节,这些技术都可以用在其它的无锁数据结构上。
1)无锁队列主要是通过CAS、FAA这些原子操作,和Retry-Loop实现。
2)对于Retry-Loop,我个人感觉其实和锁什么什么两样。只是这种“锁”的粒度变小了,主要是“锁”HEAD和TAIL这两个关键资源。而不是整个数据结构
https://www.cnblogs.com/alantu2018/p/8469168.html
52 Countdownlatch和CyclicBarrier
CountDownLatch的计数器只能使用一次,而CyclicBarrier的计数器可以使用reset()方法重置,可以使用多次,所以CyclicBarrier能够处理更为复杂的场景;
CyclicBarrier还提供了一些其他有用的方法,比如getNumberWaiting()方法可以获得CyclicBarrier阻塞的线程数量,isBroken()方法用来了解阻塞的线程是否被中断;
CountDownLatch允许一个或多个线程等待一组事件的产生,而CyclicBarrier用于等待其他线程运行到栅栏位置。
CyclicBarrier调用dowait方法进行等待,等待的时候利用ReentrantLock判断是否count减为0,或者有其他线程中断,
CountDownLatch利用AQS实现,本质代码是voliatile和CAS原子指令
53 AQS
提供了一个基于FIFO队列,可以用于构建锁或者其他相关同步装置的基础框架。该同步器(以下简称同步器)利用了一个int来表示状态,期望它能够成为实现大部分同步需求的基础。使用的方法是继承,子类通过继承同步器并需要实现它的方法来管理其状态,管理的方式就是通过类似acquire和release的方式来操纵状态。然而多线程环境中对状态的操纵必须确保原子性,因此子类对于状态的把握,需要使用这个同步器提供的以下三个方法对状态进行操作:
- java.util.concurrent.locks.AbstractQueuedSynchronizer.getState()
- java.util.concurrent.locks.AbstractQueuedSynchronizer.setState(int)
- java.util.concurrent.locks.AbstractQueuedSynchronizer.compareAndSetState(int, int)
1.AQS的基础CLH队列
- CLH队列是发明者命名的一个锁队列,一般用于自旋锁,spinlocks。AQS把CLH队列用于阻塞同步,所有等待的线程构建一个node节点,然后加入对了,CLH队列是一个无锁结构,利用CAS和自旋实现线程安全
- CountDownLatch内部实现是Sync类(实现了AQS的子类),ReentrantLock也是Sync类。都是利用AQS实现的。
2.Volatile和CAS
54 公平锁、非公平锁
- 公平锁:加锁前先查看是否有排队等待的线程,有的话优先处理排在前面的线程,先来先得。
- 非公平所:线程加锁时直接尝试获取锁,获取不到就自动到队尾等待。
55 TCP三次握手
-
为什么挥手是四次?
被动关闭方可能还需要发送一些数据后,再发送FIN报文表示同意现在可以关闭连接了,所以它这里的ACK报文和FIN报文多数情况下都是分开发送的
-
Close wait和Time wait
CLOSE_WAIT过多的原因出在程序本身,是由于被动关闭连接处理不当导致的。回到程序中检查连接关闭处理
56 页面打开流程
一次请求大致过程包括:域名解析--> 发起TCP的3次握手 --> 建立TCP连接后发起http请求 --> 服务器响应http请求--> 浏览器得到html代码 --> 浏览器解析html代码,并请求html代码中的资源(如js、css、图片等) --> 浏览器对页面进行渲染呈现给用户
57 长连接
网络上很多文章都是误人子弟,根本没有说明白这个概念。这里LZ要强调一下,HTTP协议是基于请求/响应模式的,因此只要服务端给了响应,本次HTTP连接就结束了,或者更准确的说,是本次HTTP请求就结束了,根本没有长连接这一说。那么自然也就没有短连接这一说了。
之所以网络上说HTTP分为长连接和短连接,其实本质上是说的TCP连接。TCP连接是一个双向的通道,它是可以保持一段时间不关闭的,因此TCP连接才有真正的长连接和短连接这一说。
http协议默认是长连接,header设置connection:keep-alive就是启用长连接。
HTTP协议采用“请求-应答”模式,不开启KeepAlive模式时,每个req/res客户端和服务端都要新建一个连接,完成之后立即断开连接(HTTP协议为无连接的协议);当开启Keep-Alive模式(又称持久连接、连接重用)时,Keep-Alive功能使客户端到服务器端的连接持续有效,当出现对服务器的后继请求时,Keep-Alive功能避免了建立或者重新建立连接。
The client cannot specify the timeout, it is the server configuration that determines the maximum timeout value. The extra Keep-Alive header can inform the client how long the server is willing to keep the connection open (timeout=N value) and how many requests you can do over the same connection (max=M) before the server will force a close of the connection
58 HTTPS
- 采用对称加密或者非对称加密进行传输
- https不是新的协议,在HTTP基础上利用SSL和TLS进行加密和认证
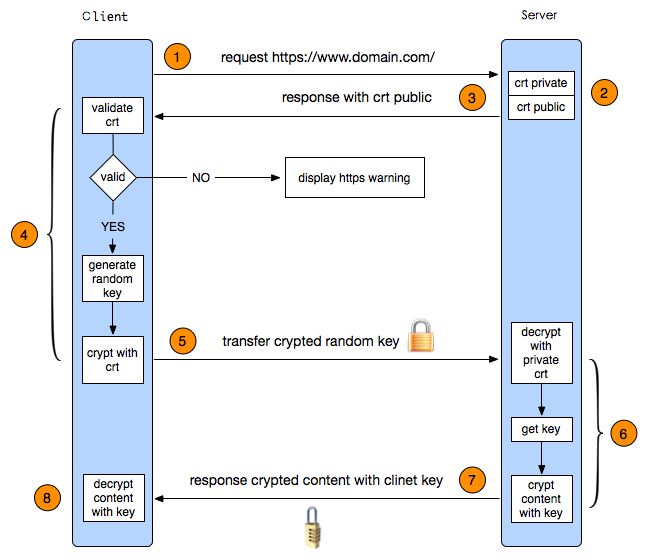
- https采用对称加密和非对称加密结合的方式。因为对称加密需要传递秘要,不安全,跟http没有区别。如果非对称加密,浏览器发给服务端,服务端利用私钥解密,再发送请求给客户端,只能用私钥,但是浏览器无非解密。是否可以两对非对称加密秘要就可以?我理解可以。但是非对称加密效率不如对称加密。但是没有搜索相关资料。网上的资料给的是里层采用对称加密,但是对称加密秘要在传输是采用非对称加密传输。浏览器生成对称秘要+服务端返回的公钥(下图中的证书就是,其实证书就是公钥+私钥以及其他附属信息,证书可以自己制作也可以是公认的)=传输秘要。服务端利用私钥解密得到对称秘要,以后就利用对称秘要直接传输。
- 使用数字证书可以确保公钥不被冒充。数字证书是经过权威机构(CA)认证的公钥,通过查看数字证书,可以知道该证书是由那家权威机构签发的,证书使用人的信息,使用人的公钥。我们下面图的第一步,如果公钥是恶意攻击回复的,那么下面的会话就会被劫持。
59 Session和Cookie
1.存放的位置
cookie保存在客户端,session一般保存在服务器端的文件系统或数据库或mamcache
2.安全性
由于session存放在服务器端,而客户端可以集中采用软、硬件技术保证安全性,所以cookie的安全性较session弱
3.网络传输量
cookie需通过网络实现客户端与服务器端之间的传输,而session保存在服务器端,无需传输
4.生存时间(以设置24分钟为例)
(1)cookie的生命周期是累计的。从创建的时候就开始计时,24分钟后cookie生命周期结束,cookie自动失效
(2)session的生命周期是间隔的,从创建时开始计时,比如在24分钟内(php.ini默认session的失效时间就是1440s,即24m)没有访问过session(指没有执行含session的文件),那么session信息就自动无效,但如果在24分钟之内,比如第23分钟访问过session,那么它的生命周期将重新开始计算。
60 分布式唯一ID生成策略
1.全局唯一性:不能出现重复的ID,最基本的要求。
2.趋势递增:MySQL InnoDB引擎使用的是聚集索引,由于多数RDBMS使用B-tree的数据结构来存储索引数据,在主键的选择上面我们应尽量使用有序的主键保证写入性能。
3.单调递增:保证下一个ID一定大于上一个ID。
4.信息安全:如果ID是连续递增的,恶意用户就可以很容易的窥见订单号的规则,从而猜出下一个订单号,如果是竞争对手,就可以直接知道我们一天的订单量。所以在某些场景下,需要ID无规则。
-
Snowflake算法
snowflake的结构如下(每部分用-分开):
0 - 0000000000 0000000000 0000000000 0000000000 0 - 00000 - 00000 - 000000000000
第一位为未使用,接下来的41位为毫秒级时间(41位的长度可以使用69年),然后是5位datacenterId和5位workerId(10位的长度最多支持部署1024个节点) ,最后12位是毫秒内的计数(12位的计数顺序号支持每个节点每毫秒产生4096个ID序号)
一共加起来刚好64位,为一个Long型。(转换成字符串长度为18)
snowflake生成的ID整体上按照时间自增排序,并且整个分布式系统内不会产生ID碰撞(由datacenter和workerId作区分),并且效率较高。据说:snowflake每秒能够产生26万个ID
缺点
- 依赖机器的时钟,如果服务器时钟回拨,会导致重复ID生成。
- 在分布式环境上,每个服务器的时钟不可能完全同步,有时会出现不是全局递增的情况。
-
UUID
UUID由以下几部分的组合:
(1)当前日期和时间。
(2)时钟序列。
(3)全局唯一的IEEE机器识别号,如果有网卡,从网卡MAC地址获得,没有网卡以其他方式获得。
标准的UUID格式为:xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx (8-4-4-4-12),以连字号分为五段形式的36个字符,示例:550e8400-e29b-41d4-a716-446655440000。Java标准类库中已经提供了UUID的API。
缺点
- 不易存储:UUID太长,16字节128位,通常以36长度的字符串表示,很多场景不适用。
- 信息不安全:基于MAC地址生成UUID的算法可能会造成MAC地址泄露,这个漏洞曾被用于寻找梅丽莎病毒的制作者位置。
- ID作为主键时在特定的环境会存在一些问题,比如做DB主键的场景下,UUID就非常不适用
-
Redis
public String createRequestId(String channel) {
// 生成编号 产品号(3位)+日期(8位)+每日从1开始自增长数(7位)
StringBuilder num = new StringBuilder(channel);
String dateStr = DateUtils.dateToStr(new Date(), 2);
num.append(dateStr);
Long count = redisTmp.incr(Constants.REDIS_APPLYNO + channel + dateStr);
if (count.intValue() != 0) {
num.append(String.format("%07d", count));
} else {
return "";
}
return num.toString();
}
利用redis的原子操作,incr函数进行自增运算。同样涉及时钟不一致问题。
61 延迟关闭交易
- 利用定时任务扫描,优点是简单,持久化存储。缺点是定时任务时间不准确,并且数据库压力大
- 利用延迟队列,优点是内存操作快,缺点是需要注意内存容量(无界队列),如果队列数据太大,是否也会有延迟在时间计算上。另外内存丢失如何解决?
62 无界队列
JDK7提供了7个阻塞队列。分别是
- ArrayBlockingQueue :一个由数组结构组成的有界阻塞队列。----数组必须指定大小,所以不能是无界的
- LinkedBlockingQueue :一个由链表结构组成的有界(可以设置为无界,Integer.MAX_VALUE)阻塞队列。
- PriorityBlockingQueue :一个支持优先级排序的无界阻塞队列。---基于数组实现,数组长度指定了最大值,初始值是11
- DelayQueue:一个使用优先级队列实现的无界阻塞队列。----基于PriorityQueue实现。
/**
* Priority queue represented as a balanced binary heap: the two
* children of queue[n] are queue[2*n+1] and queue[2*(n+1)]. The
* priority queue is ordered by comparator, or by the elements'
* natural ordering, if comparator is null: For each node n in the
* heap and each descendant d of n, n <= d. The element with the
* lowest value is in queue[0], assuming the queue is nonempty.
*/
transient Object[] queue; // non-private to simplify nested class access
- SynchronousQueue:一个不存储元素的阻塞队列。
- LinkedTransferQueue:一个由链表结构组成的无界阻塞队列。
- LinkedBlockingDeque:一个由链表结构组成的双向阻塞队列。