MySQL实战-5
目录
Memory引擎
自增主键
insert...select的锁问题
快速复制表
grant的权限问题
分区表
自增id
Memory引擎
InnoDB引擎的索引组织方式
Memory使用的是hash索引,索引的key不是有序的
Memory使用的是hash索引,索引的key不是有序的
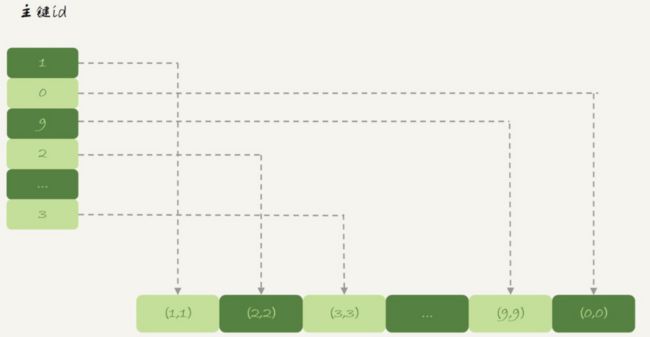
InnoDB引擎把数据放在主键索引上,其他索引上保存的是主键id,这种方式成为 索引组织表
Memory引擎采用的是把数据单独存放,索引上保存数据位置的数据组织形式,成为 堆组织表
区别
- InnoDB表的数据总是有序存放的,而内存表的数据就是按照写入顺序存放的
- 当数据文件有空洞的时候,InnoDB表在插入新数据的时候,为了保证数据有序性,只能在固定位置写入新值,而内存表找到空位就可以插入新值
- 数位置发生变化的时候,InnoDB表只需要修改主键索引,而内存表需要修改所有索引
- InnoDB表用主键索引查询的时候走一次索引查找,普通索引走两次,内存表没有这个区别
- InnoDB支持变长数据类型,内存表不支持
内存表也支持B-Tree索引,可以在id列上创建一个索引
alter table t1 add index a_btree_index using btree (id);
表t1的数据组织形式如下
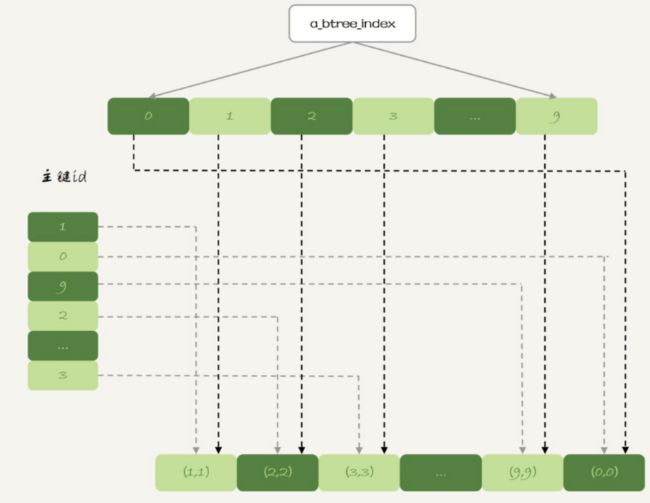
内存表的锁是表级别的,比起InnoDB并发度差了很多
内存表也不支持持久化,在高可用架构下就不能用了
另外对于大量读的场景,InnoDB有Buffer Pool,其性能也不差
建议普通的内存表都用InnoDB来替代
但有一个场景可以用内存表,即临时表的情况
- 临时表不会被其他线程访问,没有并发问题
- 临时表重启后也是需要删除的,清空数据这个问题不存在
- 备库的临时表也不会影响主库的用户线程
自增主键
自增的id未必是连续的
默认是放到内存中,mysql5.7之后开始有了持久化
新的自增算法是
从auto_increment_offset开始,以auto_increment_increment为步长,持续叠加,直到找到第一个大于x的值,作为新的自增值
其中auto_increment_offset和auto_increment_increment是两个系统参数,分别用来标识自增的初始化和步长,默认值都是1
双M的时候,可以让步长设置为1,初始值分别为1和2,这样每次都是奇数和偶数保证不冲突
如果使用了自定义的值
- 插入的值>=当前自增值,新的自增值就是 准备插入的值+1
- 否则,自增值不变
自增id不连续的原因
- 唯一键冲突后自增值不会回滚,导致不连续
- 事务回滚也会产生类型的现象
- 自增锁优化时候,批量返回自增id
批量申请自增id策略
- 语句执行过程中,第一次申请自增id,会分配1
- 一个用完后,第二次申请会分配2个
- 第三次分配四个
- 用同一个语句去申请自增id,每次都会得到自增id个数据都是上一次的两倍
如果第一次插入1条,第二次插入2条(2,3),第三次插入2条(4,5),第四次的自增id就是8
但是第三次只插入两条,所以6,7这两个id就没有,导致了不连续
insert...select的锁问题
。。。
快速复制表
用mysqldump方式
mysqldump -h$host -P$port -u$user --add-locks=0 --no-create-info --single-transaction --set-gtid-purged=OFF db1 t --where="a>900" --result-file=/client_tmp/t.sql
如果希望生产的文件中一条insert语句只插入一行数据的话,加上-skip-extended-insert
mysql -h127.0.0.1 -P13000 -uroot db2 -e "source /client_tmp/t.sql"
导出CSV文件
select * from db1.t where a>900 into outfile '/server_tmp/t.csv';
注意这个导出的文件会保存在服务端
导出后,使用下面命令将将数据导入到目标表db2.t中
load data infile '/server_tmp/t.csv' into table db2.t;
这个语句执行流程如下
1.主库执行完后,将csv文件内容写到binlog中
2.往binlog文件中写入语句load data local infile '/tmp/SQL_LOAD_MB-1-0' INTO TABLE ‘db2.t’
3.把这个binlog日志传到备库
4.备库的apply线程在执行这个事务日志时
先将binlog中t.csv文件中的内容读出来,写入到本地临时目录/tmp/SQL_LOAD_MB-1-0中
再执行load data语句,往备库的db2.t表中插入跟主库相同的数据
执行图如下

不加local读的是服务端,加了local读的是客户端
selelct... into outfile 方法不会生产表结构文件
mysqldump 提供了一个方式,可以同时导出表结构定义文件和csv数据文件
mysqldump -h$host -P$port -u$user ---single-transaction --set-gtid-purged=OFF db1 t --where="a>900" --tab=$secure_file_priv
物理拷贝
直接拷贝db1.t表的.frm文件,以及.ibd文件是不行的
InnoDB表除了包含这两个物理文件,还需要在数据字典中注册,mysql5.6之后引入了 可传输表空间
通过导出 导入表空间的方式,实现物理拷贝表
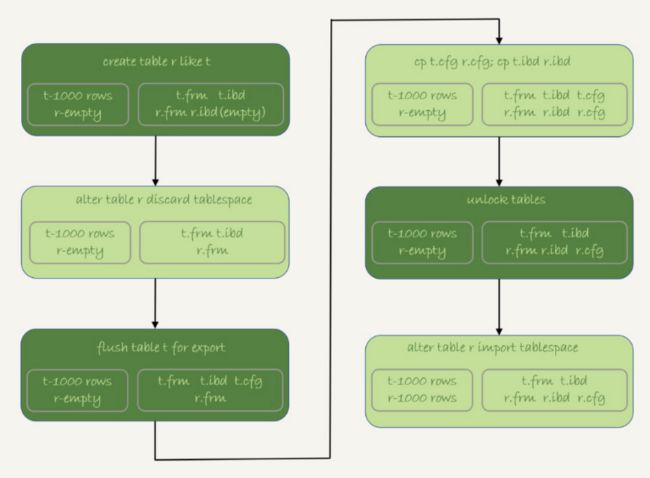
具体操作步骤
- 执行create table r like t,创建一个相同的空表
- 执行alter table r discard tablespace,这时候r.ibd文件会被删除
- 执行flush table t for export,这时候db1目录下会生成一个t.cfg文件
- 在db1目录下还行cp t.cfg r.cfg, cpt.idb r.idb
- 执行unlock tables,这时候t.cfg文件会被删除
- 执行alter table r import tablespace,将r.ibd文件作为表r的新表空间,由于这个文件的数据内容和t.ibd是相同的,所以表r中就有了和表t相同的数据
整个过程如下图
物理拷贝速度最快,但必须是全表拷贝,需要导服务器上拷贝数据
select...into outfile最灵活,但每次只能导出一张表的数据
grant的权限问题
。。。
分区表
创建分区表的语句
CREATE TABLE `t` (
`ftime` datetime NOT NULL,
`c` int(11) DEFAULT NULL,
KEY (`ftime`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1
PARTITION BY RANGE (YEAR(ftime))
(PARTITION p_2017 VALUES LESS THAN (2017) ENGINE = InnoDB,
PARTITION p_2018 VALUES LESS THAN (2018) ENGINE = InnoDB,
PARTITION p_2019 VALUES LESS THAN (2019) ENGINE = InnoDB,
PARTITION p_others VALUES LESS THAN MAXVALUE ENGINE = InnoDB);
insert into t values('2017-4-1',1),('2018-4-1',1);
这个表包含了一个.frm文件和4个.ibd文件,每个分区对应一个.ibd文件
对于引擎来说是4个表
对于server层来说是1个表
普通的表如果插入两个数据'2017-4-1'和'2018-4-1',会触发间歇锁,如下

使用分区表后,间歇锁的状态如下
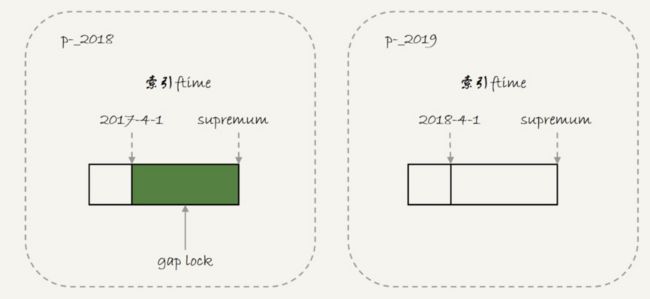
手工分区和表分区,一个是由server层决定使用哪个分区,一个是由应用层来决定使用哪个分区
从引擎层看是没有差别的
这两个方案的区别,主要在server层
当第一次访问一个分区表时,mysql需要把所有的分区都访问一遍
MyISAM分区策略是由server层控制的,存在严重性能问题
InnoDB由引擎层控制,到mysql8.0之后就不允许MyISAM创建分区
只有InnoDB和NDB允许
另一个性能问题是MDL锁,对于手工分区来说,MDL锁对于不同的分区是没影响的,但是对于分区表就是一个全局锁
分区表的优势是对业务透明,分区表可以很方便的清理历史数据
自增id
表定义自增id
主键的自增id如果达到了最大值后,就不会改变了,于是会报主键冲突
4字节的主键可能会出现这个问题,8字节无符号基本上就不会出现了
row_id
如果没有主键,mysql会生成一个默认主键,这个是2^48范围大小,理论上也是可能会到上限的
而且达到上限之后就回0了,会把之前的数据覆盖掉
xid
server层维护的事务id,是一个纯内存变量
mysql重启之后会重新生成binlog文件,所以再同一个binlog中xid是唯一的
这个变量是8字节,达到上限后会回0,如果一个binlog里面有2^64个查询会让xid回0
trx_id
这个是InnoDB内部维护的事务id,这个id会持久化的,当mysql实例运行足够久之后就会回0
这样老事务对比id大小,认为0比当前的id小就会读到这个id=0的内容,这就属于脏读了
thread_id
4个字节的变量,到达上限后会回0,mysql保证了新生成的线程id不会跟老的冲突