python网络爬虫学习笔记之实力爬虫(
淘宝商品比价定向爬虫
插播一句 过几天就是双十一了,emmmmmmmm又要剁手了四不四
-------------------------------------------------------------------------------------------好了 言归正传,正经分割线---------------------------------------------------------------------------------------
功能描述:
目标 是获取淘宝搜索页面的信息,提取其中的商品名称和价格
理解 获取淘宝的接口,怎么通过程序 向淘宝提交申请进行访问
翻页的处理
技术路线 采用requests 库和re库
我们看一下在淘宝搜索页面提交书包关键词 浏览器返回的链接信息
书包书我们搜索的关键词 所以前面的q就是引入关键词的变量,所以前面这一部分就可以作为对淘宝提交关键词的接口
其实你可以搜索第二页第三页淘宝商品的信息 后面有
所以通过简单的分析我们可以知道向淘宝提交搜索的接口 以及对应每一个翻页的不同url的参数变量
基于这样两个观察 我们可以确定向淘宝商品提交的url接口 作为一个爬虫我们还需要知道淘宝是否允许用户向它爬取相关信息
我们可以看一下它的robots协议
http://www.taobao.com/robots.txt

很不幸,robots协议对所有的爬虫限定了disallow根目录的相关的约定 ,也就是说搜索页面不允许爬虫对他的信息进行爬取的
程序的结构设计
步骤一: 提交商品的搜索请求,循环获取页面
步骤二:对于每个页面,提取商品名称和价格信息
步骤三:将信息输出到屏幕上
淘宝商品比价定向爬虫实例编写 这里我们使用requests库获取相关链接 使用正则表达式库获取相关内容
#首先引入两个库
import requests
import re
然后定义三个函数:
def getHTMText(url): #获取网页的相关内容
print("")
第二部分 需要对每个获得的html页面进行解析,我们定义一个parsePage()函数,它有两个变量,一个结果的列表类型 还有一个是相关的html页面的信息
def parsePage(ilt,html):
print("")
第三部分 我们要将爬取的相关信息显示在屏幕上 printGoodsList(ist):
def printGoodsList(ilt):
print("")
最后我们需要定义一个主函数,main()
def main():
goods='书包' #搜索关键词我们定义一个变量叫做goods 这里的商品我们使用书包作为检索词
同时要设定对下一页进行爬取的深度 我们这里假设爬取当前页和下一页 所以将深度设置为2
depth=2
还要给出淘宝爬取相关信息的url
start_url='http://s.taobao.com/search?q='+goods #通过和goods进行整合来进行商品的检索
对整个的输出结果定义一个变量infoList
infoList=[]
然后我们开始对网页进行爬取,针对我们要访问的页面深度返回的页面中每一个页面都是一个不同的url 如果我们点击下一页 会有下一个url,因此我们对于每一个页面进行单独的访问并处理 这里我们使用一个for循环,然后对于每一个url链接 进行一个设计
for i in range (depth):
try:
url=start_url+'&s=' +str(44*i) 因为我们知道对于每一个页面 后面的s变量后面的数字为44的倍数 第一页 首页 没有 可是视为44*0 下一页就是&s=44 第三页就是&s=88
html=getHTMLText(url) 用gstHTMLText()函数获取url的页面信息
parsePage(infoList,html) 用parsePage 处理每一个页面的解析过程
except:
continue #用try except 就是保证如果当前页面解析发生错误 会继续也一个页面的解析 不影响
将所有页面解析完成后 我们用printGoodsList打印所有信息 并保存在info列表中
printGoodsList(infoList)
也就是main()函数的功能可以描述为:
def main():
goods='书包'
depth=2
infoList=[]
start_url='http://www.taobao.com/search?q='+goods
for i in range(depth):
try:
url=start_url+'&s'+str(44*i)
html=getHTMLText(url)
parsePage(infoList,html)
except:
continue
printGoodsList(infoList)
main()
以上就是整个函数的整体框架 下面对每一个函数进行具体的编写:
def HTMLText(url):
try:
r=requests.get(url,timeout=30)
r.raise_for_status()
r.encoding=r.apparent_encoding
print(r.text)
except:
return""
#这个函数其实是程序的关键 也就是我们需要从商品信息中获取商品的名称和价格 我们除了要进行编写代码以外我们呢还要看看html页面本身代码的编写具有什么特点
def parsePage(ist,html):
soup=BeautifulSoup(html,"html.parser")
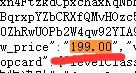
可以看到在html页面中价格信息用view_price 商品名称用raw_title来表示
因此如果我们想要获取这两个信息 只需要在获取的文本中检索view_price和raw_title即可,并把后续的内容提取出来即可,从众多的文本中提取我们想要的信息用正则表达式是非常合适的,这段商品信息虽然包含在html页面中但是它是一种脚本语言的体现,并不是完整的html页面的一个表示,所以我们并没有用BeautifulSoup库,如果不需要用BeautifulSoup来解析 而仅仅使用查找的方式 应该是最简单的,这里只采用正则表达式的方式来获取商品价格和名称
def parsePage(ilt,html):
try:
plt=re.findall(r'\"view_price\"\:\"[\d.]*\"',html)
tlt=re.findall(r'\"raw_title\"\:\".*?\"',html) # .*?是最小匹配 .是匹配任意字符这里就是汉字 *以问号结尾是最小匹配 就是汉字弄完之后遇到一个“ 后就结束了 即使后边有类似的结构 也不匹配了 保证输出的就是商品的名称 关于最小匹配如果还不懂 看我之前的文章 有讲到最小匹配的
对price信息进行提取 去掉view_price信息只保留价格部分
我们使用eval去掉获得信息的最外层部分 然后采用split函数对:进行分割 获取后半部分
for i in range(len(pit)):
price=eval(plt[i].aplit(':')[1])
title=eval(tlt[i].split(':')[1])
ilt.append([price,title])
except:
print("") #就是当你解析的时候有可能会产生这样或那样的错误,有可能eval 会出错 aplit 也会出错 使用try except 会很好的避免这种情况
程序不会因为一点错误就终止掉
下面将获取的信息打印出来
def printGoodsList(ist):
tplt="{:4}\t{:8}\t{:16}' 定义槽的长度 第一个槽给定长度为4,,,,
下面打印输出信息的表头 ‘
print(tplt.format("序号",”价格“,"商品名称"))
count=0
下面将所有的信息进行输出显示
for g in ilt:
count=count+1
print(tplt.format(count,g[0],g[1])) count是序号 后两个是价格和商品名称
************************************************************好了 我回宿舍啦明天再看 ******************************************************************************************