NLP实践-SwiftKey预测输入法(一)
目录
0.准备阶段:
·了解数据的结构:
·数据的来源:
·依靠外部的数据材料来优化此数据的处理
·NLP的普遍处理步骤
·text mining的普遍步骤和要求
·NLP与data science 基础知识的联系:
1.加载与初步处理数据:
·加载数据。
·了解基本数据的内容
-标记化
-亵渎过滤
·基本处理数据
·相关练习:
2、探索数据阶段:
3、构建模型:
早在20世纪50年代,自然语言处理就被提起,
自然语言处理(英语:Natural Language Processing,缩写作 NLP)是人工智能和语言学领域的分支学科。此领域探讨如何处理及运用自然语言;自然语言处理包括多方面和步骤,基本有认知、理解、生成等部分。
但直到20世纪80年代前,自然语言处理的系统大多仅支持有限的词汇并需要大量的人工编写的规则。到了80年代,机器计算能力的飞速提升以及机器学习算法的出现,为自然语言处理领域带来了变革。隐马可夫模型的使用,以及越来越多的基于统计模型的研究,使得系统拥有了更强的对未知输入的处理能力。如今,研究更多的集中于无监督学习或者语义监督学习,比较成功的便是自动翻译系统。近几年,大数据时代的到来,以及深度学习算法的广泛应用,又为自然语言处理带来了新的突破。
NLP通常包含两方面内容:词法、语法。词法的经典问题为分词、拼写检查、语音识别等;语法的经典问题有词类识别、词义消歧、结构分析等;语音识别领域经典问题有语言识别、语音指令、电话监听、语音生成等。
文本挖掘是抽取有效、新颖、有用、可理解的、散布在文本文件中的有价值知识,并且利用这些知识更好地组织信息的过程。
文本挖掘可以视为NLP(Natural language processing,自然语言处理)的一个子领域,目标是在大量非结构化文本中整理析取出有价值的内容。事实上自从自然语言处理技术发展之时,文字挖掘技术就得以急速在科学领域发展。今随着大量非结构化、半结构化的文字资料在企业资料环境中产生,文字挖掘也得到了越来越多的商业运用。
·TM包:
- DirSource:处理目录
- VectorSource:由文档构成向量
- DataframeSource:数据框,就像CSV 文件
- Map操作:对文档内容应用转换函数
- Xml转化为纯文本
- 去除多余空白
- 去除停用词
- 填充
- Reduce操作:将多个转换函数的输出合并成一个
0.准备阶段:
在真正处理这个课题的时候,充分了解起背景知识可以为下部处理数据、构建模型等步骤提供非常大的用处:
·了解数据的结构:
数据为txt文档,内部包括了各种文字存档,为行分布,每一行是一条”句子“。
·数据的来源:
数据来源于SwiftKey(预测文本模型的公司) 的大量文本文档,用其以发现数据中的结构以及单词如何组合在一起。
·依靠外部的数据材料来优化此数据的处理
·NLP的普遍处理步骤
·text mining的普遍步骤和要求
·NLP与data science 基础知识的联系:
常用的理论和算法有下面几种:
- 维特比算法 Viterbi
- 朴素贝叶斯分类器 Naïve Bayes, Maxent classifiers
- n元语法(下文会用到) N-gram language modeling:也称 n 元文法(n-gram)模型,用于将特定概率与单词相关联的马尔可夫概率模型,取决于先前的(N-1)个单词。
- StaIsIcal Parsing
- • Inverted index, tf-idf,vector$models of meaning .
1.加载与初步处理数据:
在初步了解了数据的背景和建立了对数据处理的大概步骤,现在是开始真正处理数据的时候:
- 标记化 - 识别适当的标记,例如单词,标点符号和数字。编写一个将文件作为输入并返回其标记化版本的函数。
- 亵渎过滤 - 删除亵渎和其他你不想预测的单词。
- Tokenization - identifying appropriate tokens such as words, punctuation, and numbers. Writing a function that takes a file as input and returns a tokenized version of it.
- Profanity filtering - removing profanity and other words you do not want to predict.
·加载数据。
这个数据集相当大,无需全部加载,通常较少的随机选择得出的块,来获得对使用所有数据获得的结果的精确近似。在此,使用R的readLines或扫描函数读取
##download the data
setwd("E://coursera//final proj//final//en_US")
if(!file.exists("./Coursera-SwiftKey.zip")){
download.file("https://d396qusza40orc.cloudfront.net/dsscapstone/dataset/Coursera-SwiftKey.zip",
destfile="./Coursera-SwiftKey.zip")}
unzip(zipfile="./Coursera-SwiftKey.zip")
path_rf <- file.path("./data" , "data.csv")
files<-list.files(path_rf, recursive=TRUE)
##load the library:(tm包实现了将文字转换至向量的一切工作)
library(tm)
##load the twitter dataset into R:
twitter <- readLines(con <- file("./en_US.twitter.txt"),
encoding = "UTF-8", skipNul = TRUE)
close(con)
在看完以后,最重要的一点是,关闭这个connections,具体可以参考?connections
> close(con)
> readLines(con, 2)
Error in readLines(con, 2) : invalid connection
·了解基本数据的内容
twitterlength<-length(twitter)
twitterSize<-file.info("en_US.twitter.txt")$size / 1024 /1000
twitterWords <- sum(sapply(gregexpr("\\S+", twitter), length))
制造个table 来显示比较好 比较:如下:
dname<-c("LENGTH","SIZE","WORDS")
dnum<-c(twitterlength,twitterSize,twitterWords)
data.frame(dname,dnum)
dname dnum
1 LENGTH 2.360148e+06
2 SIZE 1.631888e+02
3 WORDS 3.037358e+07
-标记化
识别适当的标记,例如单词,标点符号和数字。编写一个将文件作为输入并返回其标记化版本的函数。
所有的NLP都要做 文本正则化(TEXT NORMALIZATION),基本的想法是你希望能够采取一堆文本和把它分成我们称之为单词的东西。因此,您将需要处理许多问题,包括如何处理标点符号,如何思考大写和小写字母的数字和如何处理错别字,因为人们可以拼写错误的东西。因此,当您编写解决方案时,您将不得不考虑处理所有这些问题的最佳策略,并以优化性能和准确性的方式思考它们。主要内容是 :
-
在运行文本中对单词进行分段/标记
- 规范化单词格式
- 在运行文本中分割句子
-亵渎过滤
- 删除亵渎和其他你不想预测的单词。
使用文本函数sub,gsub和grep操纵字符串并识别可能感兴趣的模式。
通过正则表达式就能够将有效的内容提取出来
·基本处理数据:
| Tokenization: stemming, punctuation, analysis of linked and contracted words ("it's", "-"). | |
| * Sentence and structure detection: deal with punctuation. | |
| * Part of speech tagging, normalization: resolve ambiguities related to poly semantic words. | |
| * Named entity resolution: associate the word to a concept, use ontologies and synonyms. | |
| * Parsing: find the structure of a sentence. | |
| * Building a language model: use N-grams, rules, synonyms. Find a representation of the language model. |
基本载入数据了, 然后在随机取5000条来为下面了解基本数据:
cleanedT<- iconv(twitter, 'UTF-8', 'ASCII', "byte")
set.seed(404)
Tsample<-sample(cleanedT, 5000,replace = T)
为了方便,直接建立了 function:来一次处理,减少typing的麻烦:
BasicClean<-function(x){
Dvector<-VectorSource(x)
dCorpus<-Corpus(Dvector)
dCorpus<-tm_map(dCorpus,tolower)
dCorpus<-tm_map(dCorpus,removePunctuation)
dCorpus<-tm_map(dCorpus,removeNumbers)
dCorpus<-tm_map(dCorpus,stripWhitespace)
dCorpus<-tm_map(dCorpus,PlainTextDocument)
return(dCorpus)
}
TWSCorpus<-BasicClean(Tsample)
很多时候,处理完数据,还得vector多 一次,具体为什么我也暂时未去深究。当时 主要是未能用处理好的数据去做一个wordcloud图
当时报错是 这个:
Error in simple_triplet_matrix(i, j, v, nrow = length(terms), ncol = length(corpus), :
'i, j' invalid
查了很多方法,就用了这个方法解决了
TWSCorpus <- Corpus(VectorSource(TWSCorpus))

得到是这个词云图,当然大家可以各种参数优化来 使其更美。
总结性:
(1)删除所有不相关的字符,例如任何非字母数字字符; (2)把你的文章分成一个个单独的单词; (3)删除不相关的单词,比如“@”twitter或网址; (4)将所有字符转换为小写,以处理诸如“hello”、“Hello”和“HELLO”等单词; (5)考虑将拼错的单词或拼写单词组合成一类(如:“cool”/“kewl”/“cooool”); (6)考虑词性还原(将「am」「are」「is」等词语统一为常见形式「be」)。
在这个dataset内,主要清理了twitter 的数据集:主要如下:
cleanedT<- iconv(twitter, 'UTF-8', 'ASCII', "byte")
Tsample<-sample(cleanedT, 10000)
dataVector <- VectorSource(Tsample)
dataCorpus<-Corpus(dataVector)
dataCorpus<-tm_map(dataCorpus,tolower)
dataCorpus<-tm_map(dataCorpus,removePunctuation)
dataCorpus<-tm_map(dataCorpus,removeNumbers)
dataCorpus<-tm_map(dataCorpus,stripWhitespace)
dataCorpus<-tm_map(dataCorpus,PlainTextDocument)
| removeNumbers | 去除所有数字 |
| removePuncuation | 去除所有标点符号 |
| removeWords | 去除指定文字,文字需要自定义,也可以使用自带函数stopwords() |
| stemDocument | 提取单词词干 |
| stripWhitespace | 去除多余空格 |
·相关练习:
在加载、清理数据方面,有一份练习可以加深一下对“data”的理解:
点击 -> Data Science Capstone-Quiz 1
不过不知道大家有没有从wordcloud上面发现,出现最多的是“the ”,“to”这样的词。这样做出来的词云可以说是非常笼统而意义不大
所以建议 大家在清数据的时候再加上:
tm_map(data, stemDocument)
tm_map(data, removeWords, stopwords("english"))
2、探索数据阶段:
这里的基本目标是培养对各种方面的理解 数据集的统计属性如此 你可以建立一个良好的预测模型。
2 keys:(1)某些词语的频率 出现在数据集中以及某些单词成对出现的频率是多少? (2)三胞胎( triplets of words)的单词如何一起出现?
关键是当你对数据集没有任何期望时, 那么当你开始查看数据时,一切看起来都是正确的。 而且很难弄清楚什么是有用的,什么在数据中没用。。
- 探索性分析(Exploratory analysis) - 对数据进行彻底的探索性分析,理解单词的分布以及语料库中单词之间的关系。perform a thorough exploratory analysis of the data, understanding the distribution of words and relationship between the words in the corpora.
- 理解单词和单词对的频率(Understand frequencies of words and word pairs) - 构建数字和表格,以了解数据中单词和单词对的频率变化。build figures and tables to understand variation in the frequencies of words and word pairs in the data.
要考虑的问题
- 有些词比其他词更频繁 - 词频的分布是什么?
- 数据集中2-gram和3-gram的频率是多少?
- 在频率排序字典中,您需要多少个独特单词才能覆盖该语言中所有单词实例的50%?90%?
- 你如何评价有多少单词来自外语?
- 你能想出一种增加覆盖面的方法 - 识别可能不在语料库中的单词,或者使用字典中较少数量的单词来覆盖相同数量的短语吗?
下面是具体演示:
·理解单词的分布
我用的包主要是普通的R-GRAM包,比较通用实在:
library(ngram)
corpus.datatxt<-sapply(dataCorpus, paste, collapse = " ")
unigram <- ngram(corpus.datatxt,n=1,sep = " ")
unigramTable<-get.phrasetable(unigram)
unigramFram<-data.frame(unigramTable)
unigramOrder<-unigramFram[order(unigramFram$freq,decreasing = T),]
使用Rgram包的时候常出错的要注意:ngram()输入的数据是str,不要变成dataframe。
下面看看1-gram做出来的图:
barplot(unigramOrder[1:50,2], names.arg=unigramOrder[1:50,1],
col = "red", main="unigrams", las=2,
ylab = "freq")
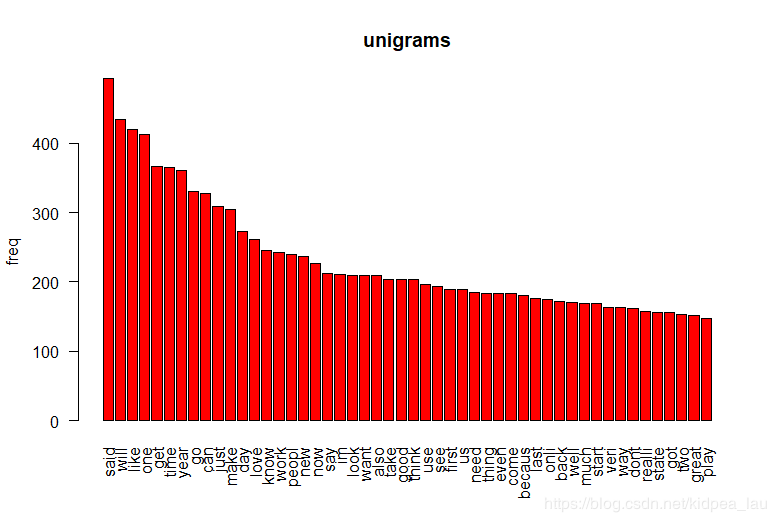
其他多元的就不多累述了,参考以上可以成功构建。
·语料库中单词之间的关系(把标记转化为特征)
接下来,是建立詞條-文件關係矩陣,其核心思想就是通過把所有文件所用到的詞提取出來,然後行(或列)代表文件,列(或行)代表詞,若該文件中該詞出現n次,則此處的矩陣元素為n,反之為0。從而構造出一個稀疏矩陣。
在tm包中提供了兩個函式來構造此矩陣,TermDocumentMatrix 和 DocumentTermMatrix,分別以詞條文件為行列、文件詞條為行列
其他词频矩阵:
removeSparseTerms()
findFreqTerms()
findAssocs()
--查询一定频数范围的词。findFreqTerms() 函式, findFreqTerms(x, lowfreq = 0, highfreq = Inf) 找出出现次数高于lowfreq并低于highfreq的条目。例如,findFreqTerms(dtm, 5) 找出出现5次以上的条目
--查询与某个词相关性高于一定范围的词。 findAssocs(x, terms, corlimit) ,其中tems,corlimit可以是一个向量。例如,findAssocs(tdm,"recent",0.5),找出与recent相关性大于0.5的词,返回的是一个列表。删减稀疏度大于指定数值的条目。删减removeSparseTerms(x, sparse) ,sparse是指稀疏度,0为最大,1为最小。
具体做法:
·多少个独特单词才能覆盖该语言中所有单词实例的50%?90%
sumCover <- 0
for(i in 1:length(onegrams$Freq)) {
sumCover <- sumCover + onegrams$Freq[i]
if(sumCover >= 0.5*sum(onegrams$Freq)){break}
}
print(i)
sumCover <- 0
for(i in 1:length(onegrams$Freq)) {
sumCover <- sumCover + onegrams$Freq[i]
if(sumCover >= 0.9*sum(onegrams$Freq)){break}
}
print(i)
full_a<-c(blogs_a,news_a,twitter_a)
full_a1<-unigrams(full_a)
wordcoverage<-function(x,wordcover) #x is the unigram output sorted by frequency, y is the percent word coverage
{nwords<-0 # initial counter
coverage<-wordcover*sum(x$freq) # number of words to hit coverage
for (i in 1:nrow(x))
{if (nwords >= coverage) {return (i)}
nwords<-nwords+x$freq[i]
}}
提取特征的方法:
·BOW(BAG OF WORDS)袋式词:
计算文本中特定标记的出现次数,这个过程叫做文本矢量化。
缺点:失去了词序;计数器没有标准化。
解决:提取n-gram;
改善:删大和小的n-gram,
·TF-IDF(Term frequency-Inverse document frequency)词频逆文档频率
"词频"(Term Frequency,缩写为TF)统计;这个权重叫做"逆文档频率"(Inverse Document Frequency,缩写为IDF),它的大小与一个词的常见程度成反比。TF-IDF是一个重要性调整系数,衡量一个词是不是常见词。如果某个词比较少见,但是它在这篇文章中多次出现,那么它很可能就反映了这篇文章的特性,正是我们所需要的关键词。知道了"词频"(TF)和"逆文档频率"(IDF)以后,将这两个值相乘,就得到了一个词的TF-IDF值。某个词对文章的重要性越高,它的TF-IDF值就越大。所以,排在最前面的几个词,就是这篇文章的关键词。
TF=w1在文章出现的次数/总词数
IDF= log[corpus文档总数/(包含该词文档数+1)]
而TF-IDF = TF * IDF
`BETTER BOW:
就是把TF-IDF 和BOW结合:用TF-IDF替换 ;逐行标准化 (用 ![]() -norm 欧几里德距离 去除)
-norm 欧几里德距离 去除)
3、构建模型:
- 构建基本的n-gram模型 - 使用您执行的探索性分析,构建一个基本的 n-gram模型(-N-gram model),用于根据之前的1,2或3个单词预测下一个单词。
- 建立一个模型来处理看不见的n-gram - 在某些情况下,人们会想要输入一个没有出现在语料库中的单词组合。构建模型以处理未观察到特定n-gram的情况。
- 你怎么能有效地存储一个n-gram模型(想想Markov Chains)?
- 如何使用有关字频的知识来使您的模型更小更高效?
- 你需要多少个参数(即n-gram模型中的n有多大)?
- 你能想出简单的方法来“平滑”概率(考虑给所有n-gram一个非零概率,即使它们没有在数据中被观察到)?
- 您如何评估您的模型是否有用?
- 如何使用退避模型来估计未观察到的n-gram的概率?
预测的模型也应最小化其大小和运行时间,应该非常仔细地考虑(1)工作区中的对象使用了多少内存; (2)运行模型需要多长时间。最终,您的模型需要在shinyapps.io服务器上运行的Shiny应用程序中运行。
在您处理算法时,以下是一些可能对您有用的工具:
- object.size():此函数报告R对象在内存中占用的字节数
- Rprof():此函数在R中运行探查器,可用于确定函数中可能存在瓶颈的位置。profr包(在CRAN上可用)提供了一些用于可视化和汇总分析数据的附加工具。
- gc():这个函数运行垃圾收集器来为R检索未使用的RAM。在这个过程中,它告诉你当前R正在使用多少内存。