论文阅读《云计算架构上的高光谱数据的并行和分布式降维》
论文《Parallel and Distributed Dimensionality Reduction of Hyperspectral Data on Cloud Computing Architectures》
Published in: IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing (Volume: 9 , Issue: 6 , June 2016 )
云计算架构上的高光谱数据的并行和分布式降维
摘要
云计算提供了以分布式方式存储和处理大量遥感高光谱数据的可能性。在高光谱成像中,降维是一项重要的任务,因为高光谱数据通常包含冗余,可以在对存储库数据进行分析之前删除。在这方面,云计算环境中降维技术的发展可以提供数据的有效存储和预处理。在本文中,我们开发了一种广泛应用于高光谱降维技术的并行和分布式实现:基于云计算架构的主成分分析(PCA)。我们的实现使用Hadoop的分布式文件系统(HDFS)来实现分布式存储,使用Apache Spark作为计算引擎,并且基于Map-reduce并行模型开发,充分利用了云计算环境的高吞吐量访问和高性能分布式计算能力。我们首先优化了传统的PCA算法,使其非常适合于并行和分布式计算,然后应用于现实的云计算架构。我们使用几个高光谱数据集进行的实验结果显示了所提出的分布式并行方法具有非常好的性能。
关键词:云计算,维度降低,Hadoop,高光谱成像,主成分分析(PCA),Spark
1 介绍
高光谱图像包含数百个连续的光谱带,从而在存储和数据处理方面有着显着的要求。重要的是有效降低高光谱图像的维数,并从数百个高度相关的光谱带中提取主要特征。由于高维数据空间大部分是空的,而高光谱数据主要集中在一个子空间中,所以它通常可以减少到一个子空间而不影响数据质量。
近几十年来,许多技术被用来将高光谱数据引入较低维的空间。主成分分析(PCA)是使用正交变换将一组(可能相关的)变量的观察值转换为称为主成分的线性不相关变量的一组值的统计过程。由于高光谱图像中的相邻频带经常相关,PCA可以有效地转换原始数据,并消除频带之间的相关性。然而,PCA算法是计算密集型的。为了克服这个问题,一些研究人员已经采用多核中央处理单元(CPU)和图形处理单元(GPU)来加速使高光谱数据量减少的PCA转换。
然而,最近在卫星和机载遥感技术上的技术进步使遥感图像数据的数量呈指数级增长,这些数据已经被收集并存储在高光谱数据存储库中。新的高光谱任务的可获得性,每天产生大量的数据,对在不同的应用领域(如要求数据解释降维)的高光谱数据的可扩展性和高效率处理提出了重要的挑战。
例如,NASA喷气推进实验室的机载可见/红外成像光谱仪(AVIRIS)的数据采集率为2.55 MB / s,这意味着在1 h内可以获得近9 GB的数据。中国Pushbroom高光谱成像仪(PHI)的数据采集率为7.2 MB / s,可在1小时内收集超过25 GB的数据。卫星Hyperion仪器在30秒内收集256×6925像素,242光谱带和12位辐射分辨率的高光谱立方数据,在1小时内收集近乎71.9 GB的数据(每天超过1.6 TB)。在其他即将投入运行的卫星任务,如环境分析和绘图方案(EnMAP)提供了类似的数据收集率。由于高光谱数据存储库的容量越来越大,而且由于它们的体积而分布在几个地理区域,因此不使用分布式计算设备很难满足大型高光谱数据处理应用程序的存储和计算需求。
分布式计算技术对于这种动态的、按需处理的大型高光谱数据集来说是非常需要的。过去,已经探索了商品集群,网格计算和云计算平台,用于遥感数据处理。最近,云计算已经成为分布式计算的标准,因为它具有先进的网格计算能力,面向服务的计算和高性能计算能力。它提供了利用分布式并行架构处理大量数据处理工作量的潜力。云计算可以看作是网格计算的演进,它依赖于网格计算原则作为其主干和基础结构,从而保持高性能分布式计算能力。因此,使用云计算分析大型高光谱数据存储库是一种自然的解决方案,也是以前开发的其他类型计算平台技术的演变。尽管如此,据我们所知(尽管在高光谱成像领域大量数据处理的需求不断增加),但是在文献中很少有人努力利用云计算基础设施进行高光谱成像技术,尤其是降维算法。
在本文中,我们为基于云计算的大规模高光谱图像处理引入了一个新的并行和分布式框架。具体来说,我们使用降维作为案例研究,以演示利用云计算技术有效地执行高光谱数据的分布式并行处理并加速高光谱数据计算的适用性和效率。为此,我们使用Hadoop分布式文件系统(HDFS)和Apache Spark等先进技术以及map-reduce方法,在云环境中开发并行和分布式PCA算法实现。用单个CPU上的串行PCA实现和使用Hadoop的PCA的分布式并行版本相比,评估了我们的实现效率在准确性和并行执行性能方面。
本文的其余部分安排如下。第二部分描述了提出的并行和分布式框架。第三部分介绍了PCA算法及其针对云计算架构的分布式并行实现。第四部分在精度和计算性能方面实验性地评估了所提出的方法。最后,第五部分总结了论文,并提出了一些合理的未来研究路线。
2 并行和分布式框架设计
为了在云计算架构上开发PCA的并行和分布式框架,需要解决三个主要问题:1)分布式编程模型; 2)计算引擎; 3)如何获得动态储存。
对于分布式编程,我们采用map-reduce模型,跨计算机集群并行处理,充分利用云计算架构提供的高性能功能。在这个模型中,一个任务由两个分布式操作来处理:map和reduce。数据集被组织为键/值对,并且映射函数处理一个键/值对以生成一组中间对,将任务分成若干独立子任务以并行运行。reduce函数负责处理与相同中间键相关联的所有中间值,然后收集所有子任务结果以收集整个任务的结果。
关于分布式计算引擎,可能的解决方案是Apache Hadoop1,由于其可靠性和可扩展性以及其完全开源的特性。它已被IBM,Yahoo和Facebook成功应用。 但是,Apache Hadoop仅支持简单的单通道计算(例如,聚合或数据库SQL查询),并且通常不适用于多径算法。Apache Spark2是一种新开发的用于云计算架构上的大规模数据处理的计算引擎,它为内存中集群计算实现容错抽象,并为大型集群提供快速和一般的数据处理。它不仅支持简单的单通道计算,而且还可以扩展到更多复杂数据分析所需的多通道算法。
它扩展了MapReduce模型,包含了用于数据共享的基元,命名为弹性分布式数据集(RDDs),并提供了基于粗粒度转换的API,允许它们使用血统来高效地恢复数据。Aparche Spark有一个高级的定向无环图(DAG)执行引擎,它支持循环数据流和内存计算,并且可以在内存中比Hadoop MapReduce快100倍,或者在磁盘上快10倍。要使用Apache Spark,开发人员应该编写一个驱动程序,定义一个或多个RDD,调用它们的操作,并跟踪RDD的血统。驱动程序通常连接到工作者集群,这是一个长期存在的进程,可以在跨操作的随机存取存储器(RAM)中存储RDD分区。在Apache Spark的运行时,用户的驱动程序启动了多个工作者,他们从分布式文件系统中读取数据块,并在内存中保存计算的RDD分区。
我们的应用需要动态存储能够在多个地理位置之间分配数据。幸运的是,HDFS3被设计为部署在低成本硬件上,并且可以提供对应用数据的高吞吐量访问,特别是对于大型数据集。我们使用HDFS中的文件作为Apache Spark上的输入RDD,我们可以使用公共接口。例如,函数partitions()为文件的每个块返回一个分区(块的偏移量存储在每个分区对象中)。 类似地,函数preferredLocations()给出了包含该块的节点的列表,并且函数iterator()可以用于读取块。考虑到上述问题,我们使用Apache Spark和HDFS进行超光谱数据处理的分布式并行框架的设计在图1中进行了图示。

3 PCA分布式并行的实现
3.1 PCA算法

3.2 分布式并行实现算法优化


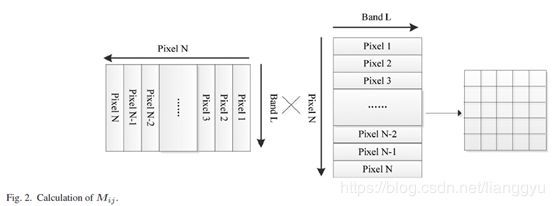
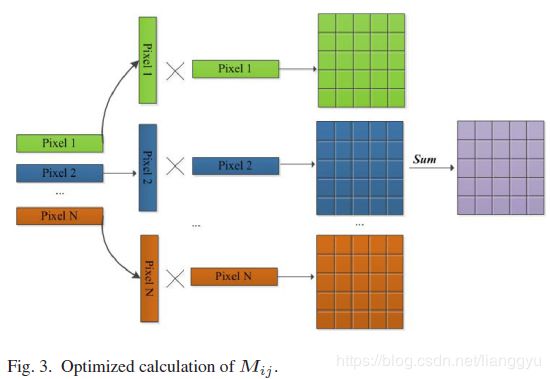
现在每个像素矢量只需要自己相乘,当计算Σ时,像素矢量之间没有相关性,这很适合于并行和分布式计算。此外,每个像素向量可以逐行地依次读取,引导程序向良好的数据位置,并且使得高速缓冲存储器更有效地被利用。
3.3 在Spark上实现并行和分布式
在本节中,我们描述了PCA算法的不同阶段的并行和分布式实现,并进一步描述了在分布式并行实现的开发中进行的架构相关优化。
如上所述,协方差矩阵的特征分解是优化的PCA算法最关键和耗时的过程。 为了充分利用云计算架构提供的高性能功能,我们首先利用map-reduce模型对Spark进行优化,如算法1所述。

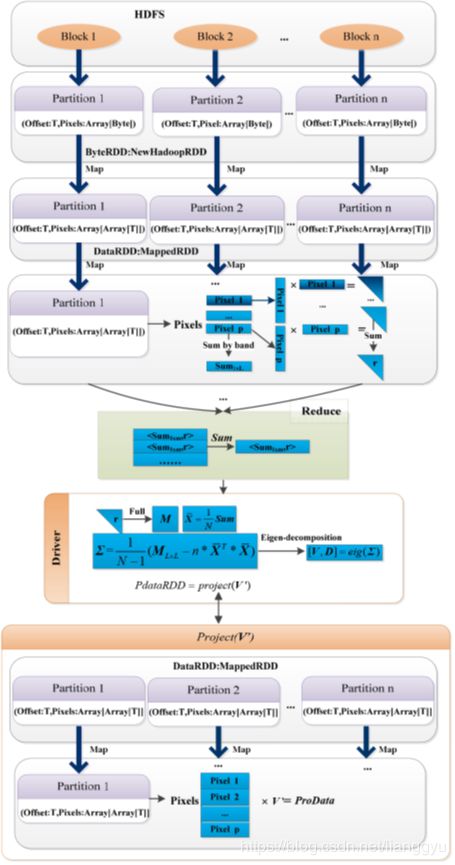
考虑到第二部分描述的分布式并行框架和map-reduce模型,PCA算法可以通过以下步骤并行和分布形式实现,如图4所示。


4 实验
5结论