《机器学习实战》之六——支持向量机(一)
SVM目录
- 一、什么是SVM
- 二、将SVM转换为数学问题
- (一)“决策面”方程
- (二)“分类间隔”方程
- (三)SVM优化问题
- (四)SVM的约束条件
- 三、求解SVM的数学问题
- (一)拉格朗日
- (二)对偶问题求解
- 四、求解数学问题——SMO算法
- 五、python代码
- 总结:
- 参考资料
一、什么是SVM
SVM的英文全称为(Support Vector Machines),大家都叫支持向量机。SVM一直被认为是现成可用的效果最好的分类算法之一。
从线性分类器开始,先考虑二分类的问题,数据点用X来表示(这是一个n维向量),类别标签用Y表示,标签类别值取1或者-1,分别代表两个不同的类别(这里选择1和-1是为了方便SVM的推导)。
一个线性分类器在二维空间中是要找到一条直线,而在n维的数据空间中是要找到一个超平面(hyperplane)


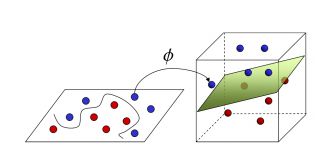
从几何直观上来看,由于超平面是用于分隔两类数据的,越接近超平面的点就越难分隔,因为超平面稍微转一下,他们就可能跑到另一边去。我们希望找到的是离分离超平面最近的点,确保他们离分离面的距离尽可能的远。如下图所示。这里点到分隔面的距离被称为间隔(margin)。
**支持向量(support vector)**就是离分隔超平面最近的那些点。接下来就是要试着最大化支持向量到分隔面的距离,需要找到此问题的优化求解方法。

二、将SVM转换为数学问题
SVM算法就是要寻找具有“最大间隔”的决策面。在SVM算法中,目标函数显然就是那个“分类间隔”,而优化的对象则是“决策面”。
我们在构建数学模型的时候,先从二维空间开始,然后再推广到多维。
(一)“决策面”方程
二维空间下一条直线的方程为:
![]()
让X轴变成x1,Y轴变成x2
![]()
![]()
将公式向量化得:
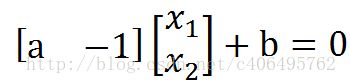
进一步向量化,用w列向量和x列向量和标量γ表示:
![]()
其中: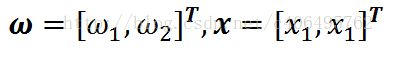
在这里w1=a,w2=-1.我们知道最开始的那个直线方程,a表示直线的斜率,b表示直线的截距。a决定了直线与x轴的方向,b决定了直线与y轴交点的位置。而这里用向量表示后,w和γ分别代表什么呢,我们画出直线和向量来看。

蓝色的线代表向量w,红色的线代表直线y。从上图可以看出向量w与直线y是垂直的。我们称w为直线的法向量。γ代表直线y的截距,这个任何时候不会变。
现将上述问题从二维空间推广到n维空间,就变成了超平面方程。但是,公式没变,依然是:
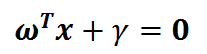
不同的是:
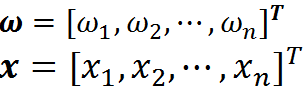
现在得到的方程就是我们要的超平面方程。
(二)“分类间隔”方程
依然先从二维平面来进行推导:

上图中,点到直线的距离公式为:
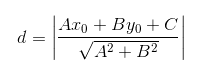
现在,将直线方程推广到多维空间,得到支持向量点到超平面的方程如下:
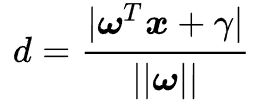
这里求到的d就是“分类间隔”,其中||w||表示w的二范数,即所有元素的平方和,然后再开方。
从上面的图中可以看出分类间隔大小就是W=2d的大小。那么这个W越大,我们认为这个超平面的分类效果越好。此时,问题已经变成了求解分类间隔W最大化的问题。W的最大化也就是d的最大化问题。
(三)SVM优化问题
现在我们已经得到了SVM的优化目标是使得d最大化,而d的表示如下:

并且,我们是用支持向量上的点来求解d的,而,支持向量上的点具有下面的特点:
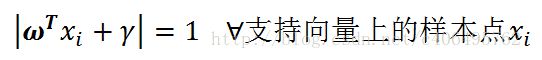
那么,现在上述d的公式可以进一步进行简化,得到:
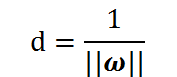
现在问题又得到进一步的转换,转换为求解||w||的最小化问题。即:

这就是我们得到的SVM的目标函数,但是该目标函数是有约束条件的。到底应该满足什么前提条件呢?
(四)SVM的约束条件
对应一个二分类问题, 如果我们的超平面能够完全正确的对上图中的样本点进行分类,并且,假设决策面正好处于间隔区域的中轴线上,那么,所有的样本点都应该满足下面的方程:
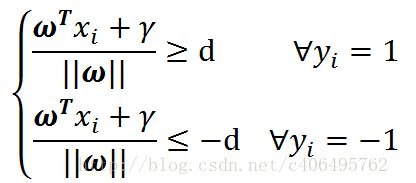
上述公式的意思是,对所有的分类标签为1的样本点,他们到直线的距离都≥d,对于所有分类标签为-1的样本点,它们到直线的距离都≤d。公式两边都除以d便可得到下面的方程:

上述的方程就是SVM最优化问题的约束条件。(这里就能很好的解释为什么分类标签值为1和-1了,因为这样标记方便我们将约束条件变成一个约束方程,即如下的形式,方便我们计算)
![]()
因此,现在SVM的目标函数就变成为求解如下的问题了:
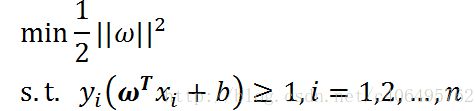
s.t.表示(subject to),是“服从某某条件”的意思。
三、求解SVM的数学问题
(一)拉格朗日
将有约束的原始目标函数转换为无约束的新构造的拉格朗日目标函数,公式变成如下:
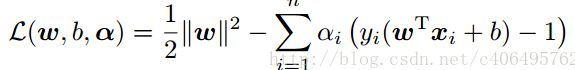
其中αi是拉格朗日乘子,αi大于等于0,是我们构造新目标函数时引入的系数变量(我们自己设置)。现在我们令:
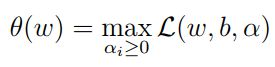
现在,我们的问题就变成了求新的目标函数的最小值了,即:
![]()
使用拉格朗日函数对偶性,将最小和最大的位置交换一下,这样就变成了:
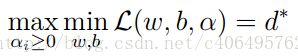
交换以后的新问题是原始问题的对偶问题,这个新问题的最优值用d来表示。而且d<=p*。我们关心的是d=p的时候,这才是我们要的解。需要什么条件才能让d=p呢?
- 首先必须满足这个优化问题是凸优化问题。
- 其次,需要满足KKT条件
(二)对偶问题求解
第一步:求解内侧的最小值
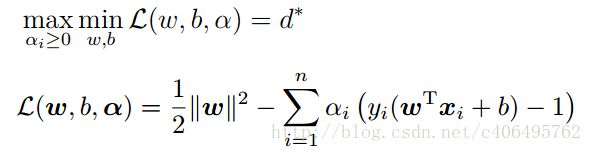
首先固定α,要让L(w,b,α)关于w和b最小化,我们分别对w和b偏导数,令其等于0,即:
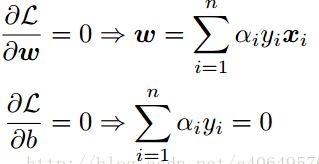
将上述结果带回L(w,b,α)得到:

从上面的最后一个式子,我们可以看出,此时的L(w,b,α)函数只含有一个变量,即αi。
**第二步:求外侧的最大值(之一)。
**
现在我们的优化问题变成了如下的形式。对于这个问题,我们有更高效的优化算法,即序列最小优化(SMO)算法。我们通过这个优化算法能得到α,再根据α,我们就可以求解出w和b,进而求得我们最初的目的:找到超平面,即”决策平面”

现在,我们再将目标函数变形,在前面增加一个负号,将求解最大值问题转换为最小值问题。目标函数如下所示:

至此,一切都很完美,但是这里有一个假设:数据必须100%线性可分。目前为止,我们知道几乎所有数据都不那么“干净”,这时我们就可以通过引入所谓松弛变量(slack variable),来允许有些数据点可以处于分隔面的错误一侧。这样我们的优化目标就能保持仍然不变,但是此时新的约束条件则变为:

四、求解数学问题——SMO算法
1996年,John Platt发布了一个称为SMO的强大算法,用于训练SVM。SM表示序列最小化(Sequential Minimal Optimizaion)。Platt的SMO算法是将大优化问题分解为多个小优化问题来求解的。这些小优化问题往往很容易求解,并且对它们进行顺序求解的结果与将它们作为整体来求解的结果完全一致的。在结果完全相同的同时,SMO算法的求解时间短很多。
SMO算法的目标是求出一系列α和b,一旦求出了这些α,就很容易计算出权重向量w并得到分离超平面。
SMO算法的工作原理是:每次循环中选择两个α进行优化处理。一旦找到了一对合适的α,那么就增大其中一个同时减少另一个。这里所谓的“合适”,就是指两个α必须符合上面提到的两个约束条件。
寻找到的α不仅要满足第一个条件,即α是正数,且小于某个常数。还得受到第二个条件的限制,即。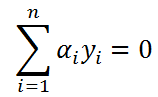
由于,分类标签y的取值是+1和-1,受第二个条件的约束,我们只有同时更新两个α值,因为只有成对更新,才能保证更新之后的值仍然满足和为0的约束,假设我们选择的两个乘子为α1和α2:
![]()
其中, ζ为常数。因为两个因子不好同时求解,所以可以先求第二个乘子α2的解(α2 new),得到α2的解(α2 new)之后,再用α2的解(α2 new)表示α1的解(α1 new )。为了求解α2 new ,得先确定α2 new的取值范围。假设它的上下边界分别为H和L,那么有:
![]()
综合两个约束条件,得到如下:
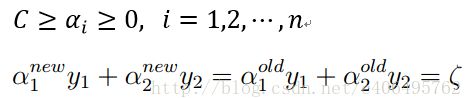
当y1不等于y2时,即一个为正1,一个为负1的时候,可以得到:
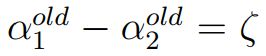
所以有:
![]()
当y1等于y2时,即两个都为正1或者都为负1,可以得到:
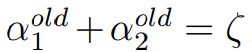
所以有:
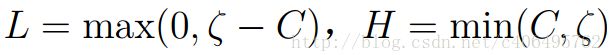
如此,根据y1和y2异号或同号,可以得出α2 new的上下界分别为:
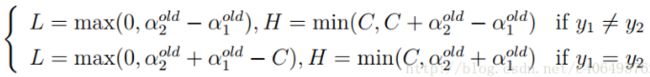
接下来就是讨论如何更新α值。我们依然假设选择的两个乘子为α1和α2。固定这两个乘子,进行推导。于是目标函数变成了:

为了描述方便,我们定义如下符号:
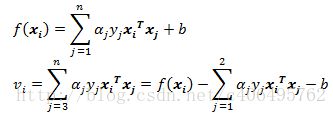
最终目标函数变为:
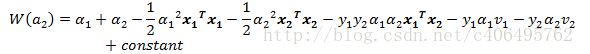
我们不关心constant的部分,因为对于α1和α2来说,它们都是常数项,在求导的时候,直接变为0。对于这个目标函数,如果对其求导,还有个未知数α1,所以要推导出α1和α2的关系,然后用α2代替α1,这样目标函数就剩一个未知数了,我们就可以求导了,推导出迭代公式。所以现在继续推导α1和α2的关系。注意第一个约束条件:
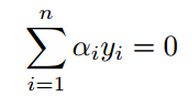
我们在求α1和α2的时候,可以将α3,α4,…,αn和y3,y4,…,yn看作常数项。因此有:
![]()
我们不必关心常数B的大小,现在将上述等式两边同时乘以y1,得到(y1y1=1):
![]()
其中γ为常数By1,我们不关心这个值,s=y1y2。接下来,我们将得到的α1带入W(α2)公式得:

这样目标函数中就只剩下α2了,我们对其求偏导(注意:s=y1y2,所以s的平方为1,y1的平方和y2的平方均为1):
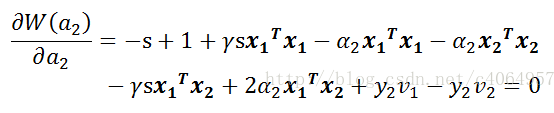
继续化简,将s=y1y2带入方程。
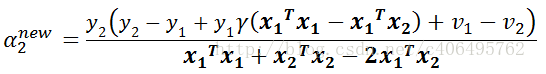
我们令:
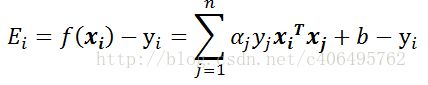
![]()
Ei为误差项,η为学习速率。
再根据我们已知的公式:
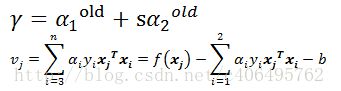
将α2 new继续化简得:
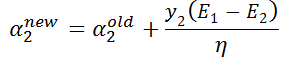
这样,我们就得到了最终需要的迭代公式。这个是没有经过剪辑是的解,需要考虑约束:![]()
根据之前推导的α取值范围,我们得到最终的修剪的解为:
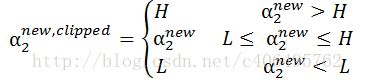
又因为:
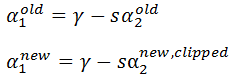
消去γ得:
![]()
这样,我们就知道了怎样计算α1和α2了,也就是如何对选择的α进行更新。
当我们更新了α1和α2之后,需要重新计算阈值b,因为b关系到了我们f(x)的计算,也就关系到了误差Ei的计算。
我们要根据α的取值范围,去更正b的值,使间隔最大化。当α1 new在0和C之间的时候,根据KKT条件可知,这个点是支持向量上的点。因此,满足下列公式:
![]()
公式两边同时乘以y1得(y1y1=1):
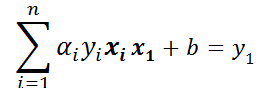
因为我们是根据α1和α2的值去更新b,所以单独提出i=1和i=2的时候,整理可得:

其中前两项为:
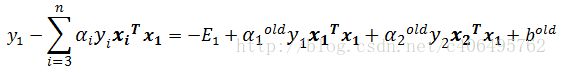
将上述两个公式,整理得到最终更新b1和b2的公式如下:
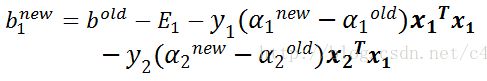
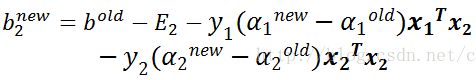
当b1和b2都有效的时候,它们是相等的,即:
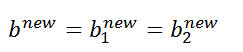
当两个乘子都在边界上,则b阈值和KKT条件一致。当不满足的时候,SMO算法选择他们的中点作为新的阈值:
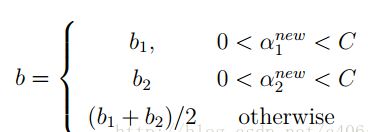
最后,更新所有的α和b,这样模型就出来了,从而即可求出我们的分类函数。
现在,整理下SMO算法的步骤:
步骤1:计算误差
步骤2:计算上下界L和H
步骤3:计算η
步骤4:更新αj
步骤5:根据取值范围修剪αj
步骤6:更新αi
步骤7:更新b1和b2
步骤8:根据b1和b2更新b
五、python代码
# -*- coding: utf-8 -*-
import numpy as np
import matplotlib.pyplot as plt
import random
""" 函数说明:读取数据 parameters: fileName:文件名 Returns: dataMat:数据矩阵 labelMat:数据标签 """
def loadDataSet(fileName):
dataMat = []; labelMat = []
fr = open(fileName)
for line in fr.readlines():
lineArr = line.strip().split('\t')
dataMat.append([float(lineArr[0]), float(lineArr[1])])
labelMat.append(float(lineArr[2]))
return dataMat, labelMat
""" 函数说明:随机选择alpha parameters: i:第一个alpha的下标 m:所有alpha数目 Returns: j """
def selectJrand(i, m):
j = i
while(j == i):
j = int(np.random.uniform(0,m)) #选择一个不等于i的j
return j
""" 函数说明:修剪alpha parameters: aj:alpha值 H: alpha上限 L:alpha下限 Returns: aj:alpha值 """
def clipAlpha(aj, H, L):
if aj > H:
aj = H
if L > aj:
aj = L
return aj
""" 函数说明:简化版SMO算法 Parameters: dataMatIn:数据矩阵 classLabels:数据标签 C:松弛变量 toler:容错率 maxIter:最大迭代次数 Returns: Null """
def smoSimple(dataMatIn, classLabels, C, toler, maxIter):
#转换为numpy的mat存储
dataMatrix = np.mat(dataMatIn)
labelMat = np.mat(classLabels).transpose()
#初始化参数b,统计dataMatrix的维度
b = 0
m,n = np.shape(dataMatrix)
#初始化alpha参数,设为0
alphas = np.mat(np.zeros((m,1)))
#初始化迭代次数
iter = 0
while(iter < maxIter):
alphaPairsChanged = 0
for i in range(m):
#步骤1:计算误差Ei
fXi = float(np.multiply(alphas, labelMat).T*(dataMatrix*dataMatrix[i,:].T)) + b
Ei = fXi - float(labelMat[i])
#优化alpha,设定一定的容错率。
if ((labelMat[i]*Ei < -toler) and (alphas[i] < C)) or ((labelMat[i]*Ei > toler) and (alphas[i] > 0)):
#随机选择另一个与alpha_i成对优化的alpha_j
j = selectJrand(i, m)
fXj = float(np.multiply(alphas, labelMat).T*(dataMatrix*dataMatrix[j,:].T)) + b
#步骤1:计算误差Ej
Ej = fXj - float(labelMat[j])
#保存更新前的aplpha值,使用深拷贝
alphaIold = alphas[i].copy()
alphaJold = alphas[j].copy()
#步骤2:计算上下界L和H
if(labelMat[i] != labelMat[j]):
L = max(0, alphas[j] - alphas[i])
H = min(C, C + alphas[j] + alphas[i])
else:
L = max(0, alphas[j] + alphas[i] - C)
H = min(C, alphas[j] + alphas[i])
if (L == H):
print("L==H")
continue
#步骤3:计算eta
eta = 2.0 * dataMatrix[i,:]*dataMatrix[j,:].T - dataMatrix[i,:]*dataMatrix[i,:].T - dataMatrix[j,:] * dataMatrix[j,:].T
if eta >= 0:
print("eta>=0")
continue
#步骤4:更新alpha_j
alphas[j] -= labelMat[j]*(Ei-Ej)/eta
#步骤5:修剪alpha_j
alphas[j] = clipAlpha(alphas[j], H, L)
if(abs(alphas[j] - alphaJold) < 0.00001):
print("alpha_j 变化太小")
continue
#步骤6:更新alpha_i
alphas[i] += labelMat[j]*labelMat[i]*(alphaJold-alphas[j])
#步骤7:更新b_1和b_2
b1 = b - Ei - labelMat[i]*(alphas[i]-alphaIold)*dataMatrix[i,:]*dataMatrix[i,:].T-labelMat[j]*(alphas[j]-alphaJold)*dataMatrix[i,:]*dataMatrix[j,:].T
b2 = b - Ej - labelMat[i]*(alphas[i]-alphaIold)*dataMatrix[i,:]*dataMatrix[j,:].T-labelMat[j]*(alphas[j]-alphaJold)*dataMatrix[j,:]*dataMatrix[j,:].T
#步骤8:根据b_1和b_2更新b
if (0 < alphas[j]) and (C > alphas[i]):
b = b1
elif (0 < alphas[j]) and (C > alphas[j]):
b = b2
else:
b = (b1 + b2)/2.0
#统计优化次数
alphaPairsChanged += 1
#打印统计信息
print("第%d次迭代,样本:%d,alpha优化次数 %d" % (iter, i, alphaPairsChanged))
#更新迭代次数
if (alphaPairsChanged == 0):
iter += 1
else:
iter = 0
print("iteration number: %d" % iter)
return b, alphas
""" 函数说明:分类结果可视化 Parameters dataMat:数据矩阵 w:直线法向量 b:直线截距 Returns Null """
def showClassifer(dataMat,labelMat,alphas,w,b):
data_plus = [] #存放正样本
data_minus = [] #存放负样本
for i in range(len(dataMat)):
if labelMat[i] > 0:
data_plus.append(dataMat[i])
else:
data_minus.append(dataMat[i])
data_plus_np = np.array(data_plus) #转换为numpy矩阵
data_minus_np = np.array(data_minus)
plt.scatter(np.transpose(data_plus_np)[0],np.transpose(data_plus_np)[1],s=30,alpha=0.7) #绘制正样本的散点图
plt.scatter(np.transpose(data_minus_np)[0],np.transpose(data_minus_np)[1],s=30,alpha=0.7) #绘制负样本的散点图
#绘制直线
x1 = max(dataMat)[0]
x2 = min(dataMat)[0]
a1, a2 = w
b = float(b)
a1 = float(a1[0])
a2 = float(a2[0])
y1, y2 = (-b-a1*x1)/a2, (-b-a1*x2)/a2
plt.plot([x1,x2],[y1,y2])
#找出支持向量点
for i, alpha in enumerate(alphas):
if abs(alpha) > 0:
x, y = dataMat[i]
plt.scatter([x],[y],s=150, c='none',alpha=0.7, linewidth=1.5,edgecolor='red')
plt.show()
""" 函数说明:计算w Parameters: dataMat:数据矩阵 labelMat:数据标签 alphas:alphas值 Returns Null """
def get_w(dataMat, labelMat, alphas):
alphas, dataMat, labelMat = np.array(alphas),np.array(dataMat),np.array(labelMat)
w = np.dot((np.tile(labelMat.reshape(1,-1).T, (1,2))* dataMat).T, alphas)
return w.tolist()
if __name__ == '__main__':
dataMat, labelMat = loadDataSet('testSet.txt')
b,alphas = smoSimple(dataMat, labelMat, 0.6, 0.001, 40)
w = get_w(dataMat, labelMat, alphas)
showClassifer(dataMat,labelMat,alphas, w, b)
运行结果如下图所示

总结:
虽然通过看书、读一些人的经典博客,看吴恩达的机器学习视频将SVM的数学公式进行了推导,对《机器学习实战》书中代码的理解有很大的帮助,但之后有时间了会拿原版platt的论文进行阅读,现在就先偷懒了。另外,对推导过程中遇到的KKT条件不是特别的明白。
在这里要非常感谢一些大牛博主的经典博客,非常受益。所以现在自己学了一些东西后,也坚持书写博客,一来供自己整理思路,留存学习。二来,可以供一些新手进行学习,少走弯路。
参考资料
- 博客https://blog.csdn.net/c406495762/article/details/78072313
- 《机器学习实战》第六章内容
- pluskid大牛博客:http://blog.pluskid.org/?page_id=683