手写数字识别的全栈尝试
心血来潮想进行一次full stack尝试,以前一直做单机的开发,没有做过web service。web service比单机应用会更加容易传播,不会对用户有太多的要求。之前就有考虑过前端和后台通信的问题,但一直没有真正去实现过,这次还是遇到了一些问题。
整个项目的逻辑是,用户在前端网页手写一个数字,前端将图片发送给后台,后台对图片进行识别,将识别结果返回给前端。整个项目是基于Django,Django是一个Python的web应用框架,很好地将前后端结合起来,方便开发。前端部分,写了一个简单的网页,主体是个canvas,用户可以在canvas上进行画写。后端用python写的,用tensorflow训练好的模型进行预测。
项目上传在github上, 网站demo部署在heroku,刚连接时可能需要等待,因为太久没有连接,网站会进入睡眠状态。
前端
前端之前不是很熟悉,花了几天看了下htmL+css+js,能够写一些简单的东西,还用了bootstrap库来快速开发。说实话,我是真的没有任何美感啊…做东西完全做的不好看。
基本的界面如下:
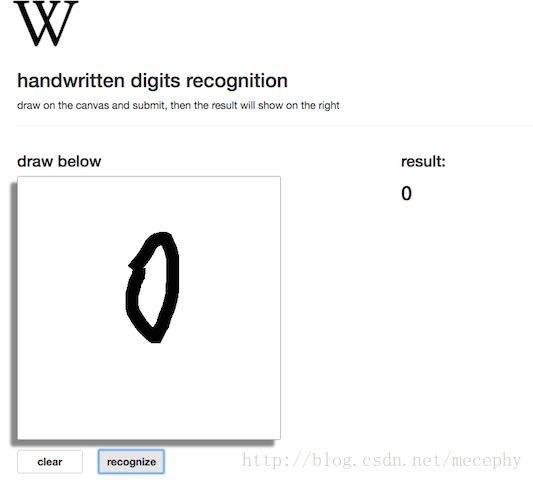
前端将canvas转化为图像数据的代码如下:
var scribbler = document.getElementById ("the_stage");
var imageData = scribbler.toDataURL('image/png');
var dataTemp = imageData.substr(22);后端
用python语言写的,工作流程如下:
- 响应前端请求
- 解析数据成图像数据并进行预处理
- 用tensorflow进行识别
- 将识别结果返回给后端
前端传来的数据是经过base64编码的,我们解码后将其转换为numpy矩阵,就能用opencv的一些函数进行处理,将3通道转为灰度图,并resize成28x28大小,最后拉成1x784的矩阵,进行识别。
预处理部分还加入了一些位置的控制,找到数字位置并把其移到图像中央。有个有趣的地方是调用opencv的resize函数有个插值参数可选,如果用它默认的线性插值的话,最后得到的识别结果并不好,尝试了几个最后选用的最近邻插值,效果不错。
识别部分是用tensorflow训练好的模型进行预测,就是tensorflow官网的tutorial中的模型。
解析接收数据部分代码:
imgStr = request.POST.get('txt') #'txt'是传送的json数据中图像数据对应的key
imgStr = base64.b64decode(imgStr)
img = cv2.imdecode(numpy.array(bytearray(imgStr)), -1)前后端通信
这部分是我整个项目中关注的重点,之前对前后端通信不是很了解。
前端发送请求是通过url方式进行的,如访问url:www.xx.com/index,Django将url和python的函数绑定,函数用来响应请求:
from mnist.view import index
urlpatterns = [
url(r'^index', index)
]index函数如下,其返回index.html网页数据,前端获取到网页,就能加载在浏览器上:
def index(request):
return render(request, 'index.html')上面提到发送请求是通过url方式的,并且一个url对应一个python的响应函数,这样前端就能发送数据给后台并接收后台处理后的数据。假设前端是把json数据post过来的,后端函数可以通过 request.POST.get('txt')来获取json数据中“txt”这个key所对应的value。处理完毕后可以通过HttpResponse来返回数据给前端。
ajax
AJAX 是与服务器交换数据的技术,它在不重载全部页面的情况下,实现了对部分网页的更新。后端把识别结果发送给前端,前端就能把结果更新在识别结果的区域。
$.post() 方法通过 HTTP POST 请求从服务器上请求数据。 $.post(URL,data,callback);
- URL:希望请求的url
- data:发送的数据
- callback:请求成功后执行的函数
在这里,url绑定着后端的识别函数,data是要发送的手写数据,callback是成功后把识别结果显示在识别结果区域的js函数。
部署heroku
将项目部署在了国外的一个云平台heroku上,部署好会给你的项目分配一个网址,很方便。当然免费的东西还是有局限的地方,首先,在国外,可能连接比较慢;再是,网站长时间没有别访问,系统会将其变成睡眠状态,再次连接时可能要等待一会。
不过能给开发者提供这样一个测试的平台,heroku还是相当好的,不用自己花钱去租服务器或者vps了。
- 我的github上博客:http://zealerww.github.io/
- github主页:https://github.com/zealerww