基于日志的同步数据一致性和实时抽取
宜信技术研发中心架构师
- 目前就职于宜信技术研发中心,任架构师,负责流式计算和大数据业务产品解决方案。
- 曾任职于Naver china(韩国最大搜索引擎公司)中国研发中心资深工程师,多年从事CUBRID分布式数据库集群开发和CUBRID数据库引擎开发http://www.cubrid.org/blog/news/cubrid-cluster-introduction/
主题简介:
- DWS的背景介绍
- dbus+wormhole总体架构和技术实现方案
- DWS的实际运用案例
大家好,我是王东,来自宜信技术研发中心,这是我来社群的第一次分享,如果有什么不足,请大家多多指正、包涵。
本次分享的主题是《基于日志的DWS平台实现和应用》,主要是分享一下目前我们在宜信做的一些事情。这个主题里面包含到2个团队很多兄弟姐妹的努力的结果(我们团队和山巍团队的成果)。这次就由我代为执笔,尽我努力给大家介绍一下。
其实整个实现从原理上来说是比较简单的,当然也涉及到不少技术。我会尝试用尽量简单的方式来表达,让大家了解这个事情的原理和意义。在过程中,大家有问题可以随时提出,我会尽力去解答。
DWS是一个简称,是由3个子项目组成,我稍后做解释。
事情是从公司前段时间的需求说起,大家知道宜信是一个互联网金融企业,我们的很多数据与标准互联网企业不同,大致来说就是:
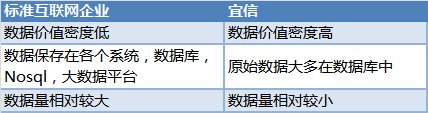
玩数据的人都知道数据是非常有价值的,然后这些数据是保存在各个系统的数据库中,如何让需要数据的使用方得到一致性、实时的数据呢?
- DBA开放各个系统的备库,在业务低峰期(比如夜间),使用方各自抽取所需数据。由于抽取时间不同,各个数据使用方数据不一致,数据发生冲突,而且重复抽取,相信不少DBA很头疼这个事情。
- 公司统一的大数据平台,通过Sqoop 在业务低峰期到各个系统统一抽取数据, 并保存到Hive表中, 然后为其他数据使用方提供数据服务。这种做法解决了一致性问题,但时效性差,基本是T+1的时效。
- 基于trigger的方式获取增量变更,主要问题是业务方侵入性大,而且trigger也带来性能损失。
这些方案都不算完美。我们在了解和考虑了不同实现方式后,最后借鉴了 linkedin的思想,认为要想同时解决数据一致性和实时性,比较合理的方法应该是来自于log。
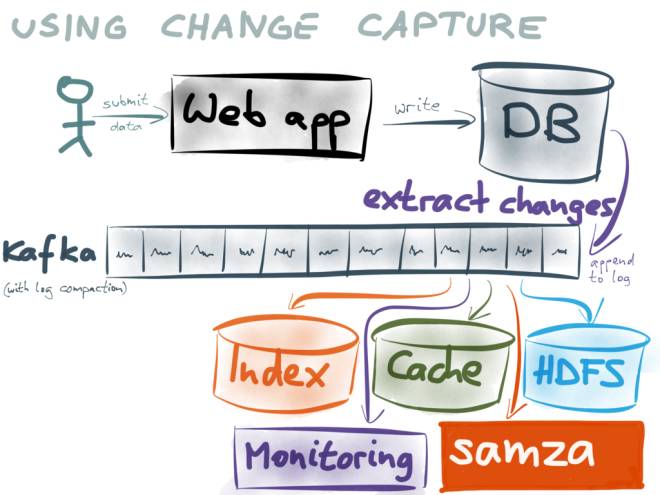
(此图来自:https://www.confluent.io/blog/using-logs-to-build-a-solid-data-infrastructure-or-why-dual-writes-are-a-bad-idea/)
把增量的Log作为一切系统的基础。后续的数据使用方,通过订阅kafka来消费log。
比如:
- 大数据的使用方可以将数据保存到Hive表或者Parquet文件给Hive或Spark查询;
- 提供搜索服务的使用方可以保存到Elasticsearch或HBase 中;
- 提供缓存服务的使用方可以将日志缓存到Redis或alluxio中;
- 数据同步的使用方可以将数据保存到自己的数据库中;
- 由于kafka的日志是可以重复消费的,并且缓存一段时间,各个使用方可以通过消费kafka的日志来达到既能保持与数据库的一致性,也能保证实时性;
为什么使用log和kafka作为基础,而不使用Sqoop进行抽取呢? 因为:
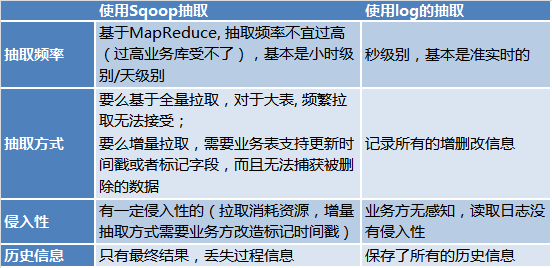
为什么不使用dual write(双写)呢?,请参考https://www.confluent.io/blog/using-logs-to-build-a-solid-data-infrastructure-or-why-dual-writes-are-a-bad-idea/
我这里就不多做解释了。
于是我们提出了构建一个基于log的公司级的平台的想法。
下面解释一下DWS平台, DWS平台是有3个子项目组成:
- Dbus(数据总线):负责实时将数据从源端实时抽出,并转换为约定的自带schema的json格式数据(UMS 数据),放入kafka中;
- Wormhole(数据交换平台):负责从kafka读出数据 将数据写入到目标中;
- Swifts(实时计算平台):负责从kafka中读出数据,实时计算,并将数据写回kafka中。
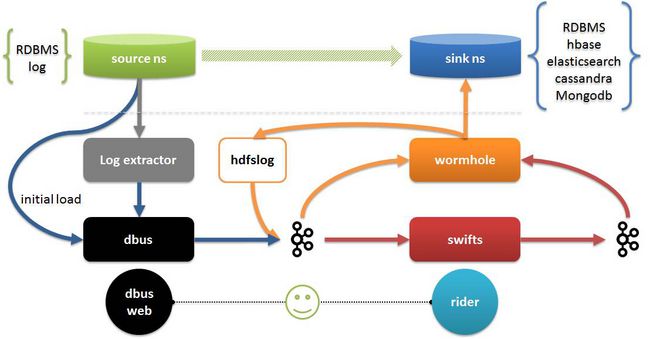
图中:
- Log extractor和dbus共同完成数据抽取和数据转换,抽取包括全量和增量抽取。
- Wormhole可以将所有日志数据保存到HDFS中; 还可以将数据落地到所有支持jdbc的数据库,落地到HBash,Elasticsearch,Cassandra等;
- Swifts支持以配置和SQL的方式实现对进行流式计算,包括支持流式join,look up,filter,window aggregation等功能;
- Dbus web是dbus的配置管理端,rider除了配置管理以外,还包括对Wormhole和Swifts运行时管理,数据质量校验等。
由于时间关系,我今天主要介绍DWS中的Dbus和Wormhole,在需要的时候附带介绍一下Swifts。
如前面所说,Dbus主要解决的是将日志从源端实时的抽出。 这里我们以MySQL为例子,简单说明如何实现。
我们知道,虽然MySQL InnoDB有自己的log,MySQL主备同步是通过binlog来实现的。如下图:
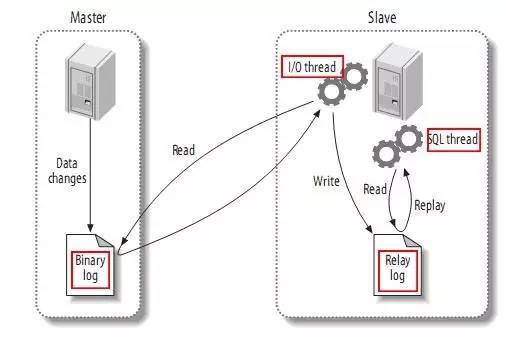
图片来自:https://github.com/alibaba/canal
而binlog有三种模式:
- Row 模式:日志中会记录成每一行数据被修改的形式,然后在slave端再对相同的数据进行修改。
- Statement 模式: 每一条会修改数据的sql都会记录到 master的bin-log中。slave在复制的时候SQL进程会解析成和原来master端执行过的相同的SQL来再次执行。
- Mixed模式: MySQL会根据执行的每一条具体的sql语句来区分对待记录的日志形式,也就是在Statement和Row之间选择一种。
他们各自的优缺点如下:
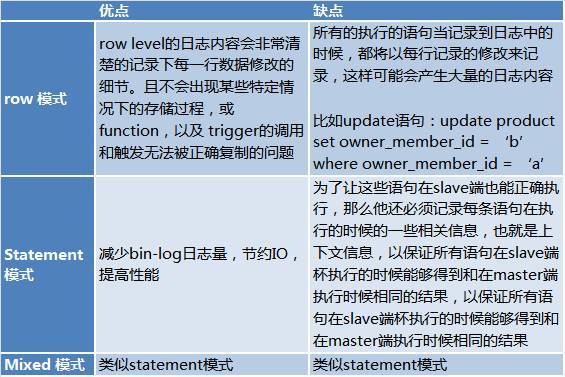
此处来自:http://www.jquerycn.cn/a_13625
由于statement 模式的缺点,在与我们的DBA沟通过程中了解到,实际生产过程中都使用row 模式进行复制。这使得读取全量日志成为可能。
通常我们的MySQL布局是采用 2个master主库(vip)+ 1个slave从库 + 1个backup容灾库 的解决方案,由于容灾库通常是用于异地容灾,实时性不高也不便于部署。
为了最小化对源端产生影响,显然我们读取binlog日志应该从slave从库读取。
读取binlog的方案比较多,github上不少,参考https://github.com/search?utf8=%E2%9C%93&q=binlog。最终我们选用了阿里的canal做位日志抽取方。
Canal最早被用于阿里中美机房同步, canal原理相对比较简单:
- Canal模拟MySQL Slave的交互协议,伪装自己为MySQL Slave,向MySQL Slave发送dump协议
- MySQL master收到dump请求,开始推送binary log给Slave(也就是canal)
- Canal解析binary log对象(原始为byte流)

图片来自:https://github.com/alibaba/canal
Dbus 的MySQL版主要解决方案如下:
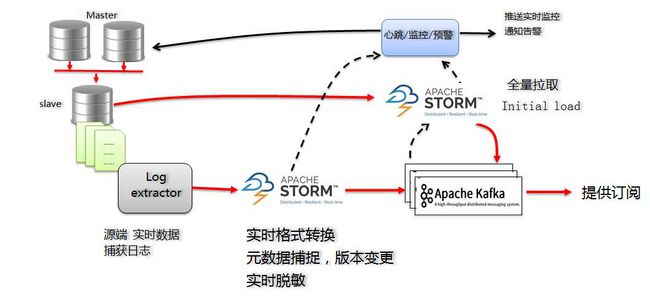
对于增量的log,通过订阅Canal Server的方式,我们得到了MySQL的增量日志:
- 按照Canal的输出,日志是protobuf格式,开发增量Storm程序,将数据实时转换为我们定义的UMS格式(json格式,稍后我会介绍),并保存到kafka中;
- 增量Storm程序还负责捕获schema变化,以控制版本号;
- 增量Storm的配置信息保存在Zookeeper中,以满足高可用需求。
- Kafka既作为输出结果也作为处理过程中的缓冲器和消息解构区。
在考虑使用Storm作为解决方案的时候,我们主要是认为Storm有以下优点:
- 技术相对成熟,比较稳定,与kafka搭配也算标准组合;
- 实时性比较高,能够满足实时性需求;
- 满足高可用需求;
- 通过配置Storm并发度,可以活动性能扩展的能力;
对于流水表,有增量部分就够了,但是许多表需要知道最初(已存在)的信息。这时候我们需要initial load(第一次加载)。
对于initial load(第一次加载),同样开发了全量抽取Storm程序通过jdbc连接的方式,从源端数据库的备库进行拉取。initial load是拉全部数据,所以我们推荐在业务低峰期进行。好在只做一次,不需要每天都做。
全量抽取,我们借鉴了Sqoop的思想。将全量抽取Storm分为了2 个部分:
- 数据分片
- 实际抽取
数据分片需要考虑分片列,按照配置和自动选择列将数据按照范围来分片,并将分片信息保存到kafka中。
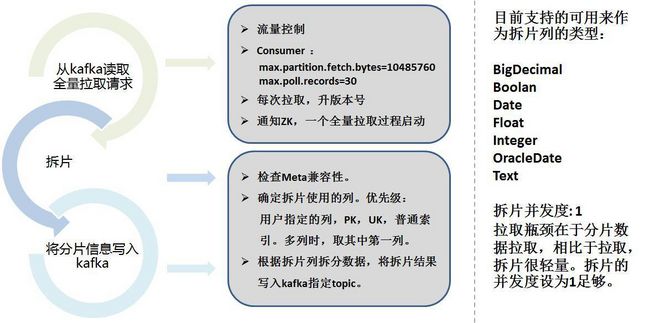
下面是具体的分片策略:
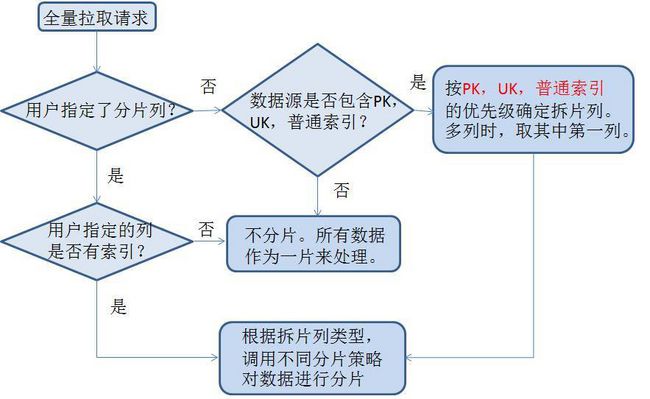
全量抽取的Storm程序是读取kafka的分片信息,采用多个并发度并行连接数据库备库进行拉取。因为抽取的时间可能很长。抽取过程中将实时状态写到Zookeeper中,便于心跳程序监控。
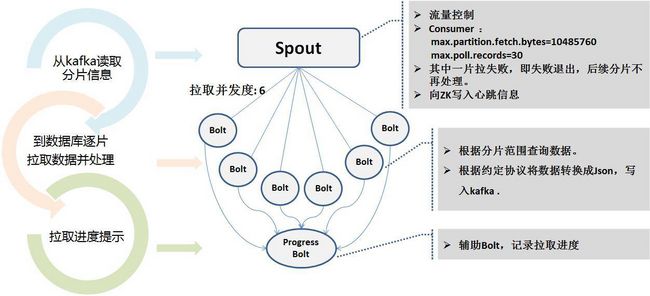
无论是增量还是全量,最终输出到kafka中的消息都是我们约定的一个统一消息格式,称为UMS(unified message schema)格式。
如下图所示:


消息中schema部分,定义了namespace 是由 类型+数据源名+schema名+表名+版本号+分库号+分表号 能够描述整个公司的所有表,通过一个namespace就能唯一定位。
- _ums_op_ 表明数据的类型是I(insert),U(update),D(删除);
- _ums_ts_ 发生增删改的事件的时间戳,显然新的数据发生的时间戳更新;
- _ums_id_ 消息的唯一id,保证消息是唯一的,但这里我们保证了消息的先后顺序(稍后解释);
payload是指具体的数据,一个json包里面可以包含1条至多条数据,提高数据的有效载荷。
UMS中支持的数据类型,参考了Hive类型并进行简化,基本上包含了所有数据类型。
在整个数据传输中,为了尽量的保证日志消息的顺序性,kafka我们使用的是1个partition的方式。在一般情况下,基本上是顺序的和唯一的。
但是我们知道写kafka会失败,有可能重写,Storm也用重做机制,因此,我们并不严格保证exactly once和完全的顺序性,但保证的是at least once。
因此_ums_id_变得尤为重要。
对于全量抽取,_ums_id_是唯一的,从zk中每个并发度分别取不同的id片区,保证了唯一性和性能,填写负数,不会与增量数据冲突,也保证他们是早于增量消息的。
对于增量抽取,我们使用的是MySQL的日志文件号 + 日志偏移量作为唯一id。Id作为64位的long整数,高7位用于日志文件号,低12位作为日志偏移量。
例如:000103000012345678。 103 是日志文件号,12345678 是日志偏移量。
这样,从日志层面保证了物理唯一性(即便重做也这个id号也不变),同时也保证了顺序性(还能定位日志)。通过比较_ums_id_ 消费日志就能通过比较_ums_id_知道哪条消息更新。
其实_ums_ts_与_ums_id_意图是类似的,只不过有时候_ums_ts_可能会重复,即在1毫秒中发生了多个操作,这样就得靠比较_ums_id_了。
整个系统涉及到数据库的主备同步,Canal Server,多个并发度Storm进程等各个环节。
因此对流程的监控和预警就尤为重要。
通过心跳模块,例如每分钟(可配置)对每个被抽取的表插入一条心态数据并保存发送时间,这个心跳表也被抽取,跟随着整个流程下来,与被同步表在实际上走相同的逻辑(因为多个并发的的Storm可能有不同的分支),当收到心跳包的时候,即便没有任何增删改的数据,也能证明整条链路是通的。
Storm程序和心跳程序将数据发送公共的统计topic,再由统计程序保存到influxdb中,使用grafana进行展示,就可以看到如下效果:

图中是某业务系统的实时监控信息。上面是实时流量情况,下面是实时延时情况。可以看到,实时性还是很不错的,基本上1~2秒数据就已经到末端kafka中。
Granfana提供的是一种实时监控能力。
如果出现延时,则是通过dbus的心跳模块发送邮件报警或短信报警。
考虑到数据安全性,对于有脱敏需求的场景,Dbus的全量storm和增量storm程序也完成了实时脱敏的功能。脱敏方式有3种:
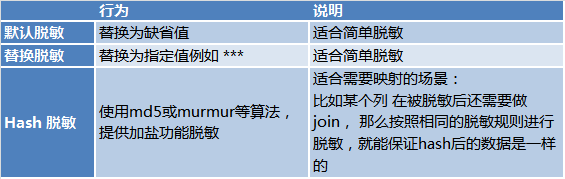
总结一下:简单的说,Dbus就是将各种源的数据,实时的导出,并以UMS的方式提供订阅, 支持实时脱敏,实际监控和报警。
说完Dbus,该说一下Wormhole,为什么两个项目不是一个,而要通过kafka来对接呢?
其中很大一个原因就是解耦,kafka具有天然的解耦能力,程序直接可以通过kafka做异步的消息传递。Dbus和Wornhole内部也使用了kafka做消息传递和解耦。
另外一个原因就是,UMS是自描述的,通过订阅kafka,任何有能力的使用方来直接消费UMS来使用。
虽然UMS的结果可以直接订阅,但还需要开发的工作。Wormhole解决的是:提供一键式的配置,将kafka中的数据落地到各种系统中,让没有开发能力的数据使用方通过wormhole来实现使用数据。
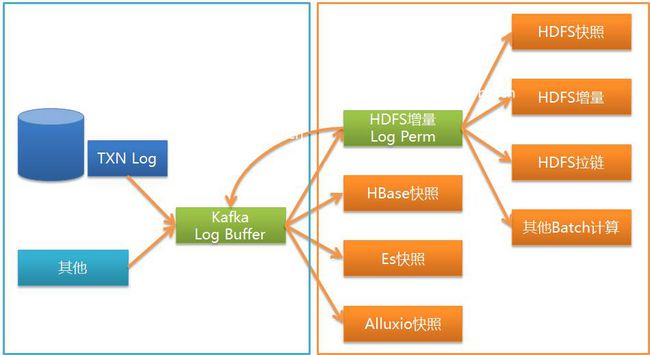
如图所示,Wormhole 可以将kafka中的UMS 落地到各种系统,目前用的最多的HDFS,JDBC的数据库和HBase。
在技术栈上, wormhole选择使用spark streaming来进行。
在Wormhole中,一条flow是指从一个namaspace从源端到目标端。一个spark streaming服务于多条flow。
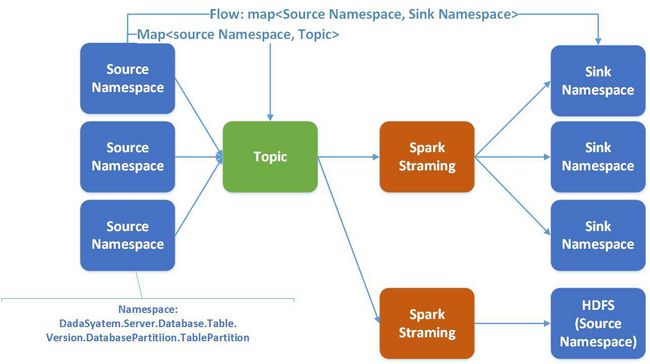
选用Spark的理由是很充分的:
- Spark天然的支持各种异构存储系统;
- 虽然Spark Stream比Storm延时稍差,但Spark有着更好的吞吐量和更好的计算性能;
- Spark在支持并行计算方面有更强的灵活性;
- Spark提供了一个技术栈内解决Sparking Job,Spark Streaming,Spark SQL的统一功能,便于后期开发;
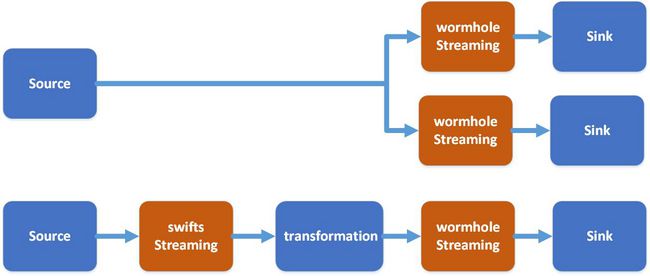
这里补充说一下Swifts的作用:
- Swifts的本质是读取kafka中的UMS数据,进行实时计算,将结果写入到kafka的另外一个topic。
- 实时计算可以是很多种方式:比如过滤filter,projection(投影),lookup, 流式join window aggregation,可以完成各种具有业务价值的流式实时计算。
Wormhole和Swifts对比如下:
通过Wormhole Wpark Streaming程序消费kafka的UMS,首先UMS log可以被保存到HDFS上。
kafka一般只保存若干天的信息,不会保存全部信息,而HDFS中可以保存所有的历史增删改的信息。这就使得很多事情变为可能:
- 通过重放HDFS中的日志,我们能够还原任意时间的历史快照。
- 可以做拉链表,还原每一条记录的历史信息,便于分析;
- 当程序出现错误是,可以通过回灌(backfill),重新消费消息,重新形成新的快照。
可以说HDFS中的日志是很多的事情基础。
介于Spark原生对parquet支持的很好,Spark SQL能够对Parquet提供很好的查询。UMS落地到HDFS上是保存到Parquet文件中的。Parquet的内容是所有log的增删改信息以及_ums_id_,_ums_ts_都存下来。
Wormhole spark streaming根据namespace 将数据分布存储到不同的目录中,即不同的表和版本放在不同目录中。

由于每次写的Parquet都是小文件,大家知道HDFS对于小文件性能并不好,因此另外还有一个job,每天定时将这些的Parquet文件进行合并成大文件。
每个Parquet文件目录都带有文件数据的起始时间和结束时间。这样在回灌数据时,可以根据选取的时间范围来决定需要读取哪些Parquet文件,不必读取全部数据。
常常我们遇到的需求是,将数据经过加工落地到数据库或HBase中。那么这里涉及到的一个问题就是,什么样的数据可以被更新到数据?
这里最重要的一个原则就是数据的幂等性。
无论是遇到增删改任何的数据,我们面临的问题都是:
- 该更新哪一行;
- 更新的策略是什么。
对于第一个问题,其实就需要定位数据要找一个唯一的键,常见的有:
- 使用业务库的主键;
- 由业务方指定几个列做联合唯一索引;
对于第二个问题,就涉及到_ums_id_了,因为我们已经保证了_ums_id_大的值更新,因此在找到对应数据行后,根据这个原则来进行替换更新。
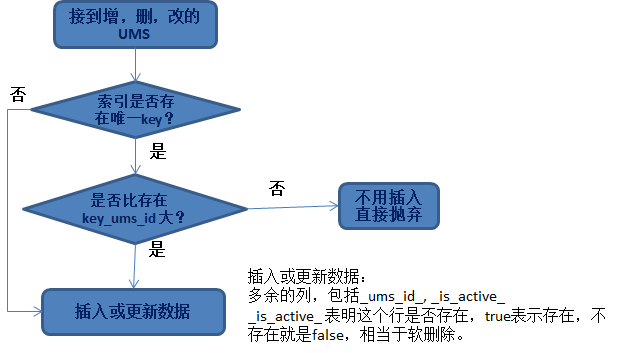
之所以要软删除和加入_is_active_列,是为了这样一种情况:
如果已经插入的_ums_id_比较大,是删除的数据(表明这个数据已经删除了), 如果不是软删除,此时插入一个_ums_id_小的数据(旧数据),就会真的插入进去。
这就导致旧数据被插入了。不幂等了。所以被删除的数据依然保留(软删除)是有价值的,它能被用于保证数据的幂等性。
插入数据到Hbase中,相当要简单一些。不同的是HBase可以保留多个版本的数据(当然也可以只保留一个版本)默认是保留3个版本;
因此插入数据到HBase,需要解决的问题是:
- 选择合适的rowkey:Rowkey的设计是可以选的,用户可以选择源表的主键,也可以选择若干列做联合主键。
- 选择合适的version:使用_ums_id_+ 较大的偏移量(比如100亿) 作为row的version。
Version的选择很有意思,利用_ums_id_的唯一性和自增性,与version自身的比较关系一致:即version较大等价于_ums_id_较大,对应的版本较新。
从提高性能的角度,我们可以将整个Spark Streaming的Dataset集合直接插入到HBase,不需要比较。让HBase基于version自动替我们判断哪些数据可以保留,哪些数据不需要保留。
Jdbc的插入数据:
插入数据到数据库中,保证幂等的原理虽然简单,要想提高性能在实现上就变得复杂很多,总不能一条一条的比较然后在插入或更新。
我们知道Spark的RDD/dataset都是以集合的方式来操作以提高性能,同样的我们需要以集合操作的方式实现幂等性。
具体思路是:
- 首先根据集合中的主键到目标数据库中查询,得到一个已有数据集合;
- 与dataset中的集合比较,分出两类:
A:不存在的数据,即这部分数据insert就可以;
B:存在的数据,比较_ums_id_, 最终只将哪些_ums_id_更新较大row到目标数据库,小的直接抛弃。
使用Spark的同学都知道,RDD/dataset都是可以partition的,可以使用多个worker并进行操作以提高效率。
在考虑并发情况下,插入和更新都可能出现失败,那么还有考虑失败后的策略。
比如:因为别的worker已经插入,那么因为唯一性约束插入失败,那么需要改为更新,还要比较_ums_id_看是否能够更新。
对于无法插入其他情况(比如目标系统有问题),Wormhole还有重试机制。说起来细节特别多。这里就不多介绍了。
有些还在开发中。
插入到其他存储中的就不多介绍了,总的原则是:根据各自存储自身特性,设计基于集合的,并发的插入数据实现。这些都是Wormhole为了性能而做的努力,使用Wormhole的用户不必关心 。
说了那么多,DWS有什么实际运用呢?下面我来介绍某系统使用DWS实现了的实时营销。
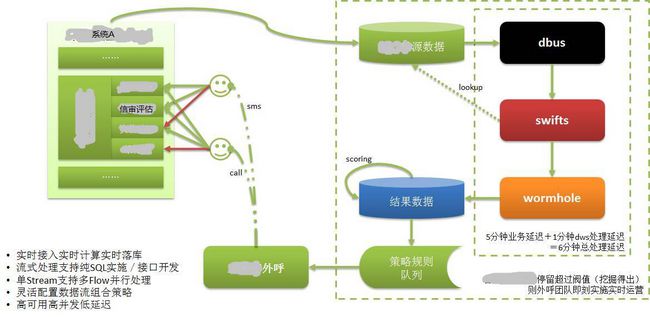
如上图所示:
系统A的数据都保存到自己的数据库中,我们知道,宜信提供很多金融服务,其中包括借款,而借款过程中很重要的就是信用审核。
借款人需要提供证明具有信用价值的信息,比如央行征信报告,是具有最强信用数据的数据。 而银行流水,网购流水也是具有较强的信用属性的数据。
借款人通过Web或手机APP在系统A中填写信用信息时,可能会某些原因无法继续,虽然可能这个借款人是一个优质潜在客户,但以前由于无法或很久才能知道这个信息,所以实际上这样的客户是流失了。
应用了DWS以后,借款人已经填写的信息已经记录到数据库中,并通过DWS实时的进行抽取、计算和落地到目标库中。根据对客户的打分,评价出优质客户。然后立刻将这个客户的信息输出到客服系统中。
客服人员在很短的时间(几分钟以内)就通过打电话的方式联系上这个借款人(潜客),进行客户关怀,将这个潜客转换为真正的客户。我们知道借款是有时效性的,如果时间太久就没有价值了。
如果没有实时抽取/计算/落库的能力,那么这一切都无法实现。
另外一个实时报表的应用如下:
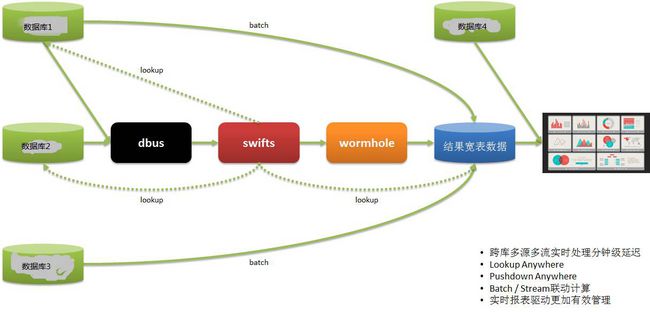
我们数据使用方的数据来自多个系统,以前是通过T+1的方式获得报表信息,然后指导第二天的运营,这样时效性很差。
通过DWS,将数据从多个系统中实时抽取,计算和落地,并提供报表展示,使得运营可以及时作出部署和调整,快速应对。
说了那么多,大致总结一下:
- DWS技术上基于主流实时流式大数据技术框架,高可用大吞吐强水平扩容,低延迟高容错最终一致。
- DWS能力上支持异构多源多目标系统,支持多数据格式(结构化半结构化非结构化数据)和实时技术能力。
- DWS将三个子项目合并作为一个平台推出,使得我们具备了实时的能力, 驱动各种实时场景应用。
适合场景包括:实时同步/实时计算/实时监控/实时报表/实时分析/实时洞察/实时管理/实时运营/实时决策
感谢大家的聆听,此次分享到此为止。
Q&A
Q1:Oracle log reader有开源方案吗?
A1:对于Oracle业界也有许多商业解决方案,例如:Oracle GoldenGate(原来的goldengate), Oracle Xstream, IBM InfoSphere Change Data Capture(原来的DataMirror),Dell SharePlex (原来的Quest),国内的DSG superSync等,开源的方案好用的很少。
Q2:这个项目投入了多少人力物力?感觉有点复杂。
Q2:DWS是三个子项目组成,平均每个项目5~7人。是有点复杂,其实也是试图使用大数据技术来解决我们公司目前遇到的困难。
因为是搞大数据相关技术,所有团队里面的兄弟姐妹都还是比较happy的:)
其实这里面,Dbus和Wormhole相对固定模式化,容易轻松复用。Swifts实时计算是与每个业务相关比较大的,自定义比较强,相对比较麻烦一些。
Q3:宜信的这个DWS系统会开源么?
A3:我们也考虑过向社区贡献,就像宜信的其他开源项目一样,目前项目刚刚成形,还有待进一步磨炼,我相信未来的某个时候,我们会给它开源出来。
Q4:架构师怎么理解,是不是系统工程师?
A4:不是系统工程师,在我们宜信有多位架构师,应该算是以技术驱动业务的技术管理人员。包含产品设计,技术管理等。
Q5:复制方案是否是OGG?
A5:OGG与上面提到的其他商业解决方案都是可选方案。
本文地址:http://www.linuxprobe.com/logs-data-extract.html