《机器学习实战》Logistics回归学习心得
第一次接触机器学习的东西,现在看到《机器学习实战》第五章,分享一下学习心得
Logistics回归就是为了找一条能够进行尽最大能力进行分类的拟合线,包括直线和曲线,但是要符合函数,也就是说这条线可以用函数进行表达,不然不能够进行分类。

如上图所示,要用一条直线将绿色的原点与红色的框点进行分成两类,很明显,无法用一条直线能够将他们完全正确的进行分类,因此需要找到一条拟合线尽最大限度进行分类,使得误差最小。如下图所示:
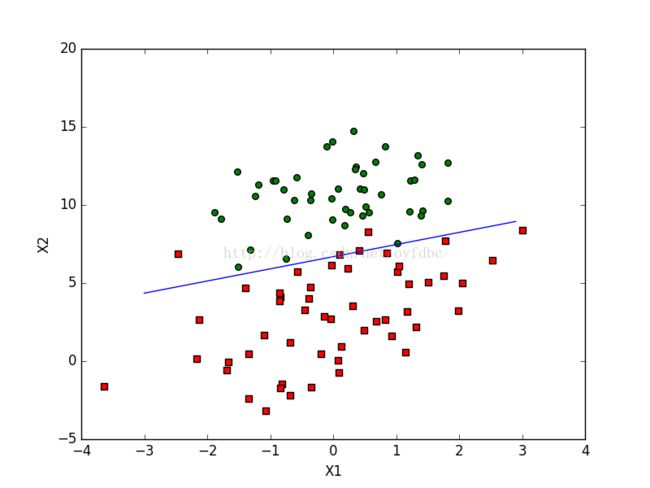
算法比较简单,书中的实现代码也比较好理解,用的事Python语言,在这里主要讲解下书中代码的实现方式,因为有几个人来请教我说算法大概知道,但是书中的代码没看懂。其实书中的代码主要以矩阵的方式处理。
其中从文件中获取原始数据的代码很简单,不做详细说明,贴图即可:
原始数据:

最后一列0和1代表类型,例如1代表绿色的圆点,0代表红色的框点,如果你缺少这个数据文件可以评论区回复我
LoadDataSet函数:
由于要拟合一条直线,所以假设该直线为a+bx+cy=0。其中a为常数,其他的不说也应该知道,之所以dataMat第一个数为1.0,因为我们要拟合的直线的参数为(a,b,c),其实就是假设a*1.0+b*x+c*y=0,因此dataMat第一个数为1.0,其他两个不解释了。而labelsMat就是类型了。因此得到返回值是:

现在讲一下分类函数了,先来一波代码:
其中mat函数是将数组转变为矩阵,因此dataMat和labelsMat已经转为矩阵形式,方便进行矩阵乘法计算。这个函数就是求解(a,b,c)三个数。weights初始化为(1,1,1),假设dataMatrix某一行为(1,x,y),则dataMatirx与weights的乘积结果就是1+x+y,因此dataMatrix与weights第一次的乘积结果就是:

他们的结果:1.0+x+y有大于0的,也有小于0的,也有等于0的,现在的假设这条直线函数为1+x+y=0,因为weights初始化为(1,1,1)嘛,所以当上面的结果大于0时候也就是(x,y)在直线的上方,等于0说明该店(x,y)在直线上,小于0说明该店(x,y)在该直线的下方,因此现在要判断是否有错,因为labelsMat中只有0和1两种类型,所以要将1+x+y的结果进行二值化,这时候就是Sigmiod函数的作用,函数为:
也就是:
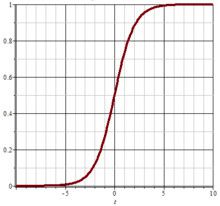
该曲线图是盗图,所以将就着看吧,这里讲下该曲线,该曲线就是将大于0的数趋向于1,小于0的数趋向于0,因此,上面的1+x+y中,如果大于0,也就是在拟合线的上方,这结果为1,在拟合线的下方或者在曲线上则结果为0,这样就可以得到一个利用初始拟合线计算之后的1+x+y的结果集,结果集只包含了0和1,跟labelsMat差不多,知识labelsMat的0和1是正确的分类,而h中的0和1是利用weights中的参数的拟合线进行计算的分类,不一定正确,所以需要对weights中的参数(a,b,c)进行逐次趋近。
error利用labelsMat-h,也就是用已经有正确分类的减去用weights参数的拟合线进行计算的估计分类进行相减,这样就会出现(正确分类,估计分类)有(0,0)、(0,1)、(1,0)、(1,1)四种,结果error中就有三种类型:-1,0,1。-1表示(0,1),也就是本应该在正确拟合线的下方,可是用该拟合线计算之后,该点却在拟合线的上方,0表示分类正确,1表示(1,0),本应该在正确拟合线上方的,却在该拟合线的下方,因此需要对拟合线(a,b,c)的参数进行调整:
比如上面的调整利用随机梯度上升的算法进行调整a、b和c,然后再重复计算error,直到weights中的参数的拟合线能够正确分类,也就是当h与labelsMat相等,error全部为0时候,该拟合线为最优拟合线,达到分类效果