小米的开源监控系统open-falcon架构设计,看完明白如何设计一个好的系统
小米的开源监控系统open-falcon架构设计,看完明白如何设计一个好的系统
小米的http://book.open-falcon.org/zh/intro/
早期,一直在用zabbix,不过随着业务的快速发展,以及互联网公司特有的一些需求,现有的开源的监控系统在性能、扩展性、和用户的使用效率方面,已经无法支撑了。
因此,我们在过去的一年里,从互联网公司的一些需求出发,从各位SRE、SA、DEVS的使用经验和反馈出发,结合业界的一些大的互联网公司做监控,用监控的一些思考出发,设计开发了小米的监控系统:open-falcon。
Highlights and features
强大灵活的数据采集:自动发现,支持falcon-agent、snmp、支持用户主动push、用户自定义插件支持、opentsdb data model like(timestamp、endpoint、metric、key-value tags)
水平扩展能力:支持每个周期上亿次的数据采集、告警判定、历史数据存储和查询
高效率的告警策略管理:高效的portal、支持策略模板、模板继承和覆盖、多种告警方式、支持callback调用
人性化的告警设置:最大告警次数、告警级别、告警恢复通知、告警暂停、不同时段不同阈值、支持维护周期
高效率的graph组件:单机支撑200万metric的上报、归档、存储(周期为1分钟)
高效的历史数据query组件:采用rrdtool的数据归档策略,秒级返回上百个metric一年的历史数据
dashboard:多维度的数据展示,用户自定义Screen
高可用:整个系统无核心单点,易运维,易部署,可水平扩展
开发语言: 整个系统的后端,全部golang编写,portal和dashboard使用python编写。
Architecture
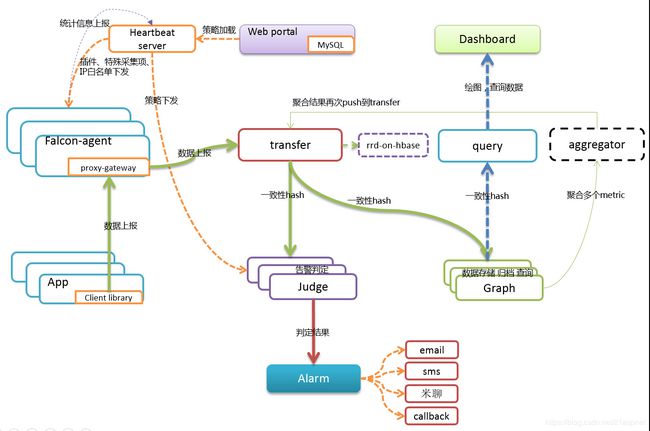
每台服务器,都有安装falcon-agent,falcon-agent是一个golang开发的daemon程序,用于自发现的采集单机的各种数据和指标,这些指标包括不限于以下几个方面,共计200多项指标。
- CPU相关
- 磁盘相关
- IO
- Load
- 内存相关
- 网络相关
- 端口存活、进程存活
- ntp offset(插件)
- 某个进程资源消耗(插件)
- netstat、ss 等相关统计项采集
- 机器内核配置参数
只要安装了falcon-agent的机器,就会自动开始采集各项指标,主动上报,不需要用户在server做任何配置(这和zabbix有很大的不同),这样做的好处,就是用户维护方便,覆盖率高。当然这样做也会server端造成较大的压力,不过open-falcon的服务端组件单机性能足够高,同时都可以水平扩展,所以自动多采集足够多的数据,反而是一件好事情,对于SRE和DEV来讲,事后追查问题,不再是难题。
另外,falcon-agent提供了一个proxy-gateway,用户可以方便的通过http接口,push数据到本机的gateway,gateway会帮忙高效率的转发到server端。
Data model
Data Model是否强大,是否灵活,对于监控系统用户的“使用效率”至关重要。比如以zabbix为例,上报的数据为hostname(或者ip)、metric,那么用户添加告警策略、管理告警策略的时候,就只能以这两个维度进行。举一个最常见的场景:
hostA的磁盘空间,小于5%,就告警。一般的服务器上,都会有两个主要的分区,根分区和home分区,在zabbix里面,就得加两条规则;如果是hadoop的机器,一般还会有十几块的数据盘,还得再加10多条规则,这样就会痛苦,不幸福,不利于自动化(当然zabbix可以通过配置一些自动发现策略来搞定这个,不过比较麻烦)。
Data collection
transfer,接收客户端发送的数据,做一些数据规整,检查之后,转发到多个后端系统去处理。在转发到每个后端业务系统的时候,transfer会根据一致性hash算法,进行数据分片,来达到后端业务系统的水平扩展。
transfer 提供jsonRpc接口和telnet接口两种方式,transfer自身是无状态的,挂掉一台或者多台不会有任何影响,同时transfer性能很高,每分钟可以转发超过500万条数据。
transfer目前支持的业务后端,有三种,judge、graph、opentsdb。judge是我们开发的高性能告警判定组件,graph是我们开发的高性能数据存储、归档、查询组件,opentsdb是开源的时间序列数据存储服务。可以通过transfer的配置文件来开启。
transfer的数据来源,一般有三种:
- falcon-agent采集的基础监控数据
- falcon-agent执行用户自定义的插件返回的数据
- client library:线上的业务系统,都嵌入使用了统一的perfcounter.jar,对于业务系统中每个RPC接口的qps、latency都会主动采集并上报
说明:上面这三种数据,都会先发送给本机的proxy-gateway,再由gateway转发给transfer。
基础监控是指只要是个机器(或容器)就能加的监控,比如cpu mem net io disk等,这些监控采集的方式固定,不需要配置,也不需要用户提供额外参数指定,只要agent跑起来就可以直接采集上报上去; 非基础监控则相反,比如端口监控,你不给我端口号就不行,不然我上报所有65535个端口的监听状态你也用不了,这类监控需要用户配置后才会开始采集上报的监控(包括类似于端口监控的配置触发类监控,以及类似于mysql的插件脚本类监控),一般就不算基础监控的范畴了。
Alerting
报警判定,是由judge组件来完成。用户在web portal来配置相关的报警策略,存储在MySQL中。heartbeat server 会定期加载MySQL中的内容。judge也会定期和heartbeat server保持沟通,来获取相关的报警策略。
heartbeat sever不仅仅是单纯的加载MySQL中的内容,根据模板继承、模板项覆盖、报警动作覆盖、模板和hostGroup绑定,计算出最终关联到每个endpoint的告警策略,提供给judge组件来使用。
transfer转发到judge的每条数据,都会触发相关策略的判定,来决定是否满足报警条件,如果满足条件,则会发送给alarm,alarm再以邮件、短信、米聊等形式通知相关用户,也可以执行用户预先配置好的callback地址。
用户可以很灵活的来配置告警判定策略,比如连续n次都满足条件、连续n次的最大值满足条件、不同的时间段不同的阈值、如果处于维护周期内则忽略 等等。
另外也支持突升突降类的判定和告警。
Query
到这里,数据已经成功的存储在了graph里。如何快速的读出来呢,读过去1小时的,过去1天的,过去一月的,过去一年的,都需要在1秒之内返回。
这些都是靠graph和query组件来实现的,transfer会将数据往graph组件转发一份,graph收到数据以后,会以rrdtool的数据归档方式来存储,同时提供查询RPC接口。
query面向终端用户,收到查询请求后,会去多个graph里面,查询不同metric的数据,汇总后统一返回给用户。
Dashboard
dashboard首页,用户可以以多个维度来搜索endpoint列表,即可以根据上报的tags来搜索关联的endpoint。
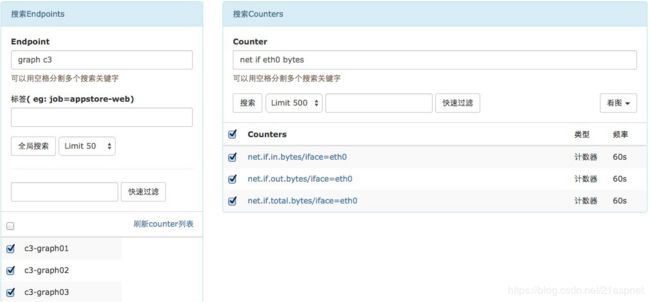
用户可以自定义多个metric,添加到某个screen中,这样每天早上只需要打开screen看一眼,服务的运行情况便尽在掌握了。
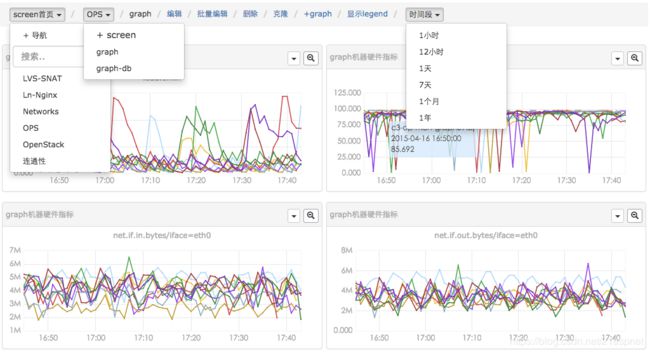
当然,也可以查看清晰大图,横坐标上zoom in/out,快速筛选反选。总之用户的“使用效率”是第一要务。
Web portal
一个高效的portal,对于提升用户的“使用效率”,加成很大,平时大家都这么忙,能给各位SRE、Devs减轻一些负担,那是再好不过了。
这是host group的管理页面,可以和服务树结合,机器进出服务树节点,相关的模板会自动关联或者解除。这样服务上下线,都不需要手动来变更监控,大大提高效率,降低遗漏和误报警。
Storage
对于监控系统来讲,历史数据的存储和高效率查询,永远是个很难的问题!
- 数据量大:目前我们的监控系统,每个周期,大概有2000万次数据上报(上报周期为1分钟和5分钟两种,各占50%),一天24小时里,从来不会有业务低峰,不管是白天和黑夜,每个周期,总会有那么多的数据要更新。
- 写操作多:一般的业务系统,通常都是读多写少,可以方便的使用各种缓存技术,再者各类数据库,对于查询操作的处理效率远远高于写操作。而监控系统恰恰相反,写操作远远高于读。每个周期几千万次的更新操作,对于常用数据库(MySQL、postgresql、mongodb)都是无法完成的。
- 高效率的查:我们说监控系统读操作少,是说相对写入来讲。监控系统本身对于读的要求很高,用户经常会有查询上百个meitric,在过去一天、一周、一月、一年的数据。如何在1秒内返回给用户并绘图,这是一个不小的挑战。
open-falcon在这块,投入了较大的精力。我们把数据按照用途分成两类,一类是用来绘图的,一类是用户做数据挖掘的。
对于绘图的数据来讲,查询要快是关键,同时不能丢失信息量。对于用户要查询100个metric,在过去一年里的数据时,数据量本身就在那里了,很难1秒之类能返回,另外就算返回了,前端也无法渲染这么多的数据,还得采样,造成很多无谓的消耗和浪费。我们参考rrdtool的理念,在数据每次存入的时候,会自动进行采样、归档。我们的归档策略如下,历史数据保存5年。同时为了不丢失信息量,数据归档的时候,会按照平均值采样、最大值采样、最小值采样存三份。
对于原始数据,transfer会打一份到hbase,也可以直接使用opentsdb,transfer支持往opentsdb写入数据。
集群聚合
集群监控的本质是一个聚合功能。
单台机器的监控指标难以反应整个集群的情况,我们需要把整个集群的机器(体现为某个HostGroup下的机器)综合起来看。比如所有机器的qps加和才是整个集群的qps,所有机器的request_fail数量 ÷ 所有机器的request_total数量=整个集群的请求失败率。
我们计算出集群的某个整体指标之后,也会有“查看该指标的历史趋势图” “为该指标配置报警” 这种需求,故而,我们会把这个指标重新push回监控server端,于是,你就可以把它当成一个普通监控数据来对待了。
首先,用户要在某个HostGroup下去添加集群聚合规则,我们就知道这个规则涵盖的机器是当前这个HostGroup下的机器。
其次,整个集群的指标计算是一个除法,除法的话就有分子,有分母。上面提到的“所有机器的qps加和才是整个集群的qps” 这个场景中每个机器应该有个qps的counter
自定义push数据到open-falcon
不仅仅是falcon-agent采集的数据可以push到监控系统,一些场景下,我们自定义的一些数据指标,也可以push到open-falcon中,比如:
- 线上某服务的qps
- 某业务的在线人数
- 某个接⼝的响应时间
- 某个⻚面的状态码(500、200)
- 某个接⼝的请求出错次数
- 某个业务的每分钟的收⼊统计
- ......
1.1. 一个shell脚本编写的,自定义push数据到open-falcon的例子
1.2. 一个python的、自定义push数据到open-falcon的例子
1.3. 一个go的、自定义push数据到open-falcon的例子
1.4. API详解
- metric: 最核心的字段,代表这个采集项具体度量的是什么, 比如是cpu_idle呢,还是memory_free, 还是qps
- endpoint: 标明Metric的主体(属主),比如metric是cpu_idle,那么Endpoint就表示这是哪台机器的cpu_idle
- timestamp: 表示汇报该数据时的unix时间戳,注意是整数,代表的是秒
- value: 代表该metric在当前时间点的值,float64
- step: 表示该数据采集项的汇报周期,这对于后续的配置监控策略很重要,必须明确指定。
- counterType: 只能是COUNTER或者GAUGE二选一,前者表示该数据采集项为计时器类型,后者表示其为原值 (注意大小写)
- GAUGE:即用户上传什么样的值,就原封不动的存储
- COUNTER:指标在存储和展现的时候,会被计算为speed,即(当前值 - 上次值)/ 时间间隔
- tags: 一组逗号分割的键值对, 对metric进一步描述和细化, 可以是空字符串. 比如idc=lg,比如service=xbox等,多个tag之间用逗号分割
说明:这7个字段都是必须指定
端口监控
falcon-agent编写初期是把本机监听的所有端口上报给server端,比如机器监听了80、443、22三个端口,就会自动上报三条数据:
net.port.listen/port=22
net.port.listen/port=80
net.port.listen/port=443
上报的端口数据,value是1,如果后来某些端口不再监听了,那就会停止上报数据。这样是否OK呢?存在两个问题:
- 机器监听的端口可能很多很多,但是真正想做监控的端口可能不多,这会造成资源浪费
- 目前Open-Falcon还不支持nodata监控,端口挂了不上报数据了,没有nodata机制,是发现不了的
改进之。
agent到底要采集哪些端口是通过用户配置的策略自动计算得出的。因为无论如何,监控配置策略是少不了的。比如用户配置了2个端口:
net.port.listen/port=8080 if all(#3) == 0 then alarm()
net.port.listen/port=8081 if all(#3) == 0 then alarm()
将策略绑定到某个HostGroup,那么这个HostGroup下的机器就要去采集8080和8081这俩端口的情况了。这个信息是通过agent和hbs的心跳机制下发的。
agent通过ss -tln拿到当前有哪些端口在监听,如果8080在监听,就设置value=1,汇报给transfer,如果发现8081没在监听,就设置value=0,汇报给transfer。
进程监控
进程监控和端口监控类似,也是通过用户配置的策略自动计算出来要采集哪个进程的信息然后上报。
JMX监控
jmxmon是一个基于open-falcon的jmx监控插件,通过这个插件,结合open-falcon agent,可以采集任何开启了JMX服务端口的java进程的服务状态,并将采集信息自动上报给open-falcon服务端
1.1. 主要功能
通过jmx采集java进程的jvm信息,包括gc耗时、gc次数、gc吞吐、老年代使用率、新生代晋升大小、活跃线程数等信息。
对应用程序代码无侵入,几乎不占用系统资源。
1.2. 采集指标
| Counters | Type | Notes |
|---|---|---|
| parnew.gc.avg.time | GAUGE | 一分钟内,每次YoungGC(parnew)的平均耗时 |
| concurrentmarksweep.gc.avg.time | GAUGE | 一分钟内,每次CMSGC的平均耗时 |
| parnew.gc.count | GAUGE | 一分钟内,YoungGC(parnew)的总次数 |
| concurrentmarksweep.gc.count | GAUGE | 一分钟内,CMSGC的总次数 |
| gc.throughput | GAUGE | GC的总吞吐率(应用运行时间/进程总运行时间) |
| new.gen.promotion | GAUGE | 一分钟内,新生代的内存晋升总大小 |
| new.gen.avg.promotion | GAUGE | 一分钟内,平均每次YoungGC的新生代内存晋升大小 |
| old.gen.mem.used | GAUGE | 老年代的内存使用量 |
| old.gen.mem.ratio | GAUGE | 老年代的内存使用率 |
| thread.active.count | GAUGE | 当前活跃线程数 |
| thread.peak.count | GAUGE | 峰值线程数 |
1.3. 建议设置监控告警项
不同应用根据其特点,可以灵活调整触发条件及触发阈值
| 告警项 | 触发条件 | 备注 |
|---|---|---|
| gc.throughput | all(#3)<98 | gc吞吐率低于98%,影响性能 |
| old.gen.mem.ratio | all(#3)>90 | 老年代内存使用率高于90%,需要调优 |
| thread.active.count | all(#3)>500 | 线程数过多,影响性能 |
Nginx 监控
在数据采集一节中我们介绍了常见的监控数据源。open-falcon作为一个监控框架,可以去采集任何系统的监控指标数据,只要将监控数据组织为open-falcon规范的格式就OK了。
Nginx的数据采集可以通过ngx_metric来做。
ngx_metric是借助lua-nginx-module的log_by_lua功能实现nginx请求的实时分析,然后借助ngx.shared.DICT存储中间结果。最后通过外部python脚本取出中间结果加以计算、格式化并输出。按falcon格式输出的结果可直接push到falcon agent。
MySQL监控实践
在数据采集一节中我们介绍了常见的监控数据源。open-falcon作为一个监控框架,可以去采集任何系统的监控指标数据,只要将监控数据组织为open-falcon规范的格式就OK了。
MySQL的数据采集可以通过mymon来做。
mymon是一个cron,每分钟跑一次,配置文件中配置了数据库连接地址,mymon连到该数据库,采集一些监控指标,比如global status, global variables, slave status等等,然后组装为open-falcon规定的格式的数据,post给本机的falcon-agent。falcon-agent提供了一个http接口,使用方法可以参考数据采集中的例子。
比如我们有1000台机器都部署了MySQL实例,可以在这1000台机器上分别部署1000个cron,即:与数据库实例一一对应。
Redis监控
在数据采集一节中我们介绍了常见的监控数据源。open-falcon作为一个监控框架,可以去采集任何系统的监控指标数据,只要将监控数据组织为open-falcon规范的格式就OK了。
Redis的数据采集可以通过采集脚本redis-monitor 或者 redismon来做。
redis-monitor是一个cron,每分钟跑一次采集脚本redis-monitor.py,其中配置了redis服务的地址,redis-monitor连到redis实例,采集一些监控指标,比如connected_clients、used_memory等等,然后组装为open-falcon规定的格式的数据,post给本机的falcon-agent。falcon-agent提供了一个http接口,使用方法可以参考数据采集中的例子。
比如,我们有1000台机器都部署了Redis实例,可以在这1000台机器上分别部署1000个cron,即:与Redis实例一一对应。
RMQ监控
在数据采集一节中我们介绍了常见的监控数据源。open-falcon作为一个监控框架,可以去采集任何系统的监控指标数据,只要将监控数据组织为open-falcon规范的格式就OK了。
RMQ的数据采集可以通过脚本rabbitmq-monitor来做。
rabbitmq-monitor是一个cron,每分钟跑一次脚本rabbitmq-monitor.py,其中配置了RMQ的用户名&密码等,脚本连到该RMQ实例,采集一些监控指标,比如messages_ready、messages_total、deliver_rate、publish_rate等等,然后组装为open-falcon规定的格式的数据,post给本机的falcon-agent。falcon-agent提供了一个http接口,使用方法可以参考数据采集中的例子。
比如我们部署了5个RMQ实例,可以在 每个RMQ实例机器上运行一个cron,即:与RMQ实例一一对应。
Data model
Open-Falcon,采用和OpenTSDB相似的数据格式:metric、endpoint加多组key value tags,举两个例子:
{
metric: load.1min,
endpoint: open-falcon-host,
tags: srv=falcon,idc=aws-sgp,group=az1,
value: 1.5,
timestamp: `date +%s`,
counterType: GAUGE,
step: 60
}
{
metric: net.port.listen,
endpoint: open-falcon-host,
tags: port=3306,
value: 1,
timestamp: `date +%s`,
counterType: GAUGE,
step: 60
}
其中,metric是监控指标名称,endpoint是监控实体,tags是监控数据的属性标签,counterType是Open-Falcon定义的数据类型(取值为GAUGE、COUNTER),step为监控数据的上报周期,value和timestamp是有效的监控数据。
机器负载信息
这部分比较通用,我们提供了一个agent部署在所有机器上去采集。不像zabbix,要采集什么数据需要在服务端配置,falcon无需配置,只要agent部署到机器上,配置好heartbeat和Transfer地址,就自动开始采集了,省去了用户配置的麻烦。目前agent只支持64位Linux,Mac、Windows均不支持。
硬件信息
硬件信息的采集脚本由系统组同学提供,作为plugin依托于agent运行,plugin机制介绍请看这里。
服务监控数据
服务的监控指标采集脚本,通常都是跟着服务的code走的,服务上线或者扩容,这个脚本也跟着上线或者扩容,服务下线,这个采集脚本也要相应下线。公司里Java的项目有不少,研发那边就提供了一个通用jar包,只要引入这个jar包,就可以自动采集接口的调用次数、延迟时间等数据。然后将采集到的数据push给监控,一分钟push一次。目前falcon的agent提供了一个简单的http接口,这个jar包采集到数据之后是post给本机agent。向agent推送数据的一个简单例子,如下:
curl -X POST -d '[{"metric": "qps", "endpoint": "open-falcon-graph01.bj", "timestamp": 1431347802, "step": 60,"value": 9,"counterType": "GAUGE","tags": "project=falcon,module=graph"}]' http://127.0.0.1:1988/v1/push
各种开源软件的监控指标
这都是大用户,比如DBA自己写一些采集脚本,连到各个MySQL实例上去采集数据,完事直接调用server端的jsonrpc汇报数据,一分钟一次,每次甚至push几十万条数据,比较好的发送方式是500条数据做一个batch,别几十万数据一次性发送。
部署实践
本文介绍了小米公司部署Open-Falcon的一些实践经验,同时试图以量化的方式分析Open-Falcon各组件的特性。
1.1. 概述
Open-Falcon组件,包括基础组件、作图链路、报警链路。小米公司部署Open-Falcon的架构,如下:
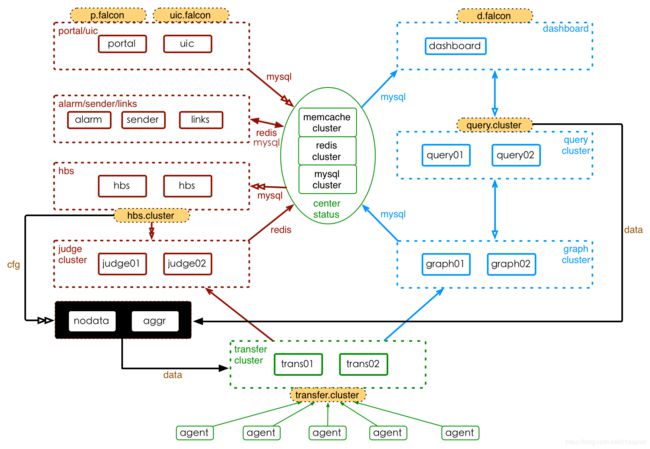
其中,基础组件以绿色标注圈住、作图链路以蓝色圈住、报警链路以红色圈住,橙色填充的组件为域名。每个模块(子服务)都有自己的特性,根据其特性来制定部署策略。
部署演进
Open-Falon的部署情况,会随着机器量(监控对象)的增加而逐渐演进,描述如下,
初始阶段,机器量很小(<100量级)。几乎无高可用的考虑,所有子服务可以混合部署在1台服务器上。此时,1台中高配的服务器就能满足性能要求。
机器量增加,到500量级。graph可能是第一个扛不住的,拿出来单独部署;接着judge也扛不住了,拿出来单独部署;transfer居然扛不住了,拿出来吧。这是系统的三个大件,把它们拆出来后devops可以安心一段时间了。
机器数量再增加,到1K量级。graph、judge、transfer单实例扛不住了,于是开始考虑增加到2+个实例、并考虑混合部署。开始有明确的高可用要求?除了alarm,都能搞成2+个实例的高可用结构。再往后,机器继续不停的增加,性能问题频现。好吧,见招拆招,Open-Falcon支持水平扩展、表示毫无压力。
机器量达到了10K量级,这正是我们现在的情况。系统已经有3000+万个采集项。transfer部署了20个实例,graph部署了20个实例,judge扩到了60个实例(三大件混合部署在20台高配服务器上,judge单机多实例)。query有5个实例、平时很闲;hbs也有5个实例、很闲的样子;dashborad、portal、uic都有2个实例;alarm、sender、links仍然是bug般的单实例部署(这几个子服务部署在10左右台低配服务器上,资源消耗很小)。graph的db已经和portal、uic的db实例分开了,因为graph的索引已经达到了5000万量级、混用会危及到其他子系统。redis仍然是共享、单实例。这是我们的使用方式,有不合理的地方、正在持续改进。
机器上100K量级了。不好意思、木有经历过。目测graph索引、hbs将成为系统较为头疼的地方,Open-Falcon的系统运维可能需要1个劳动力来完成。
1.3. 基础组件
1.3.1. agent
agent应该随装机过程部署到每个机器实例上。agent从hbs拉取配置信息,进行数据采集、收集,将数据上报给transfer。agent资源消耗很少、运行稳定可靠。小米公司部署了10K+个agent实例,已稳定运行了1Y+。
1.3.2. transfer
transfer是一个无状态的集群。transfer接收agent上报的数据,然后使用一致性哈希进行数据分片、并把分片后的数据转发给graph、judge集群(transfer还会打一份数据到opentsdb,该功能还未完成)。
transfer集群会有缩扩容的情况,也会有服务器迁移的情况,导致集群实例不固定。如某个transfer实例故障后,要将其从transfer集群中踢出。为了屏蔽这种变化对agent的影响,建议在transfer集群前挂一个域名,agent通过域名方式访问transfer集群、实现自动切换。多IDC时,为了减少跨机房流量,建议每个IDC都部署一定数量的transfer实例、agent将数据push到本IDC的transfer(可以配置dns规则,优先将transfer域名解析为本地IDC内的transfer实例)。
transfer消耗的资源 主要是网络和CPU。使用机型/操作系统选择为Dell-R620/Centos6.3,对transfer进行性能测试。Dell-R620配置为24核心、1000Gb双工网卡。测试的结果为:
| 进入数据吞吐率 | 流出数据吞吐率 | 进入流量 | 流出流量 | CPU消耗(均值) |
|---|---|---|---|---|
| 50K条/s | 100K条/s | 180Mb/s | 370Mb/s | 300% |
| 100K条/s | 200K条/s | 360Mb/s | 740Mb/s | 620% |
性能测试是在理想条件下进行的,且远远未达到服务器的资源极限。当出现流量峰值、数据接收端处理缓慢时,transfer的内存会积压一些待发送的数据、使MEM消耗出现增加(可以调整发送缓存上限,来限制最大内存消耗)。考虑到流量不均、流量峰值、集群高可用等问题,评估transfer集群容量时要做至少1倍的冗余。这里给一个建议,10K/s的进入数据吞吐率、20K/s的流出数据吞吐率,网卡配置不小于100Mb、CPU不小于100%。
1.3.3. opentsdb
该功能还未完成。预计2015年下半年能搞定。欢迎一起交流tsdb相关的使用经验。
1.3.4. center-status
center-status是中心存储的统称。Open-Falcon用到的中心存储,包括Mysql、Redis(Memcached要被弃用)。Mysql主要用于存储配置信息(如HostGroup、报警策略、UIC信息、Screen信息等)、索引数据等,Redis主要被用作报警缓存队列。索引生成、查询比较频繁和耗资源,当监控数据上报量超过100K条/min时 建议为其单独部署Mysql实例、并配置SSD硬盘。一个有意义的数据是: graph索引库,开启bin日志,保存4000万个counter且连续运行60天,消耗了20GB的磁盘空间。
当前,我们的Mysql和Redis都是单实例部署的、存在高可用的问题。Mysql还没有做读写分离、分库分表等。
1.4. 作图链路
1.4.1. graph
graph组件用于存储、归档作图数据,可以集群部署。每个graph实例会处理一个分片的数据: 接收transfer发送来的分片数据,归档、存储、生成索引;接受query对该数据分片的查询请求。
graph会持久存储监控数据,频繁写入磁盘,状态数据会缓存在内存,因此graph消耗的主要资源是磁盘存储、磁盘IO和内存资源。用"机型/系统/磁盘"为"Dell-R620/Centos6.3/SSD 2TB"的环境 对graph进行性能测试,结果为:
| 采集项数目 | 存储时长 | DISK | 进入数据 吞吐率 |
DISK.WIRTE REQUEST |
DISK.IO UTIL |
MEM |
|---|---|---|---|---|---|---|
| 900K | 5Y | 91GB | 4.42K/s | 1.6K/s | 3.0% | 5.2GB |
| 1800K | 5Y | 183GB | 8.78K/s | 3.2K/s | 7.9% | 10.0GB |
上述测试远远没有达到服务器的资源极限。根据测试结果,建议部署graph的服务器,配置大容量SSD硬盘、大容量内存。一个参考值是: 存储10K个采集项、数据吞吐率100条/s时,配置SSD磁盘不小于1GB、MEM 不小于100M;一个采集项存5年,消耗100KB的磁盘空间。
1.4.2. query
数据分片存储在graph上,用户查询起来比较麻烦。query负责提供一个统一的查询入口、屏蔽数据分片的细节。query的使用场景主要有:(1)dashboard图表展示 (2)使用监控数据做二次开发。
为了方便用户访问,建议将query集群挂载到一个域名下。考虑到高可用,query至少部署两个实例(当前,两个实例部署的IDC、机架等需要负责高可用的规范)。具体的性能统计,待续。小米公司的部署实践为: 公司开发和运维人员均使用Open-Falcon的情况下,部署5个query实例(这个其实非常冗余,2个实例足够)。
1.4.3. dashboard
dashboard用户监控数据的图表展示,是一个web应用。对于监控系统来说,读数据 或者 看图的需求相对较少,需要的query较少、需要的dashboard更少。建议以web应用的方式 部署2+个实例。小米公司的部署实践为: 公司开发和运维人员均使用dashboard的情况下,部署2个dashboard实例。
1.5. 报警链路
1.5.1. judge
judge用于实现报警策略的触发逻辑。judge可以集群部署,每个实例上处理固定分片的采集项数据(transfer给哪些,就处理哪些)。judge实现触发计算时,会在本地缓存 触发逻辑的中间状态和定量的监控历史数据,因此会消耗较多的内存资源和计算资源。下面给出一组统计数据,
| 采集项数目 | 报警策略数 | MEM消耗 | CPU消耗(均值) |
|---|---|---|---|
| 550K | xxx | 10GB | 100% |
| 1100K | xxx | 20GB | 200% |
上述统计值来自线上judge的运行数据。根据上述统计,MEM消耗、CPU消耗(均值) 随着 处理的采集项数目 基本呈线性增长。关于MEM消耗的一个参考值是,10K个采集项占用200MB的内存资源、50%个CPU资源。建议部署judge时,单实例处理的采集项数目不大于1000K。
1.5.2. hbs
hbs是Open-Falcon的配置中心,负责 适配系统的配置信息、管理agent信息等。hbs单实例部署,每个实例都有完整的配置信息。可以考虑,部署2+个实例、挂在hbs域名下,实现高可用的同时又方便用户使用。
hbs消耗的资源较少,这里给出小米公司部署hbs的参考值: 10K个agent实例、3000万个采集项、150K/s的监控数据吞吐率时,部署5个hbs实例,每个hbs实例的资源消耗为{MEM:1.0GB, CPU:<100%, NET、DISK消耗忽略不计}; 这5个hbs需要处理的配置数据,量级如下
| host数量 | hostGroup数量 | hostGroup策略数量 | express策略数量 |
|---|---|---|---|
| 10K | 1.2K | 1.1K | 300 |
1.5.3. portal
portal提供监控策略管理相关的UI,使用频率较低、系统负载很小。建议以web应用的方式 部署2+个实例。小米公司的部署实践为: 公司开发和运维人员均使用portal的情况下,部署2个portal实例。
1.5.4. uic
uic是用户信息管理中心,提供用户管理的UI,使用频率较低、系统负载较小。建议以web应用的方式 部署2+个实例。小米公司的部署实践为: 360个用户、120个用户分组,部署2个uic实例。
1.5.5. alarm(sender)
alarm负责整理报警信息,使变成适合发送的形式。alarm做了一些报警合并相关的工作,当前只能单实例部署(待优化);报警信息的数量很少,alarm服务的压力非常小、单实例完全满足资源要求;考虑到高可用,当前只能做一个冷备。sender负责将报警内容发送给最终用户。sender本身无状态,可以部署多个实例。考虑到报警信息很少,2个sender实例 能满足性能及高可用的要求。
1.5.6. links
links负责报警合并后的详情展示工作。links支持多实例部署、分片处理报警合并相关的工作。该服务压力很小,资源消耗很少;可以部署2个实例。
1.6. 混合部署
混合部署可以提高资源使用率。这里先总结下Open-Falcon各子服务的资源消耗特点,
| 子服务 | MEM消耗 | CPU消耗 | DISK消耗 | NET消耗 | 关键资源 |
|---|---|---|---|---|---|
| agent | 低 | 低 | 低 | 低 | |
| transfer | 低 | 低 | 可忽略 | 高 | NET |
| graph | 中 | 中 | 高 | 中 | DISK |
| query | 低 | 低 | 可忽略 | 中 | |
| dashboard | 低 | 低 | 可忽略 | 低 | |
| judge | 高 | 中 | 可忽略 | 低 | MEM |
| hbs | 中 | 中 | 可忽略 | 低 | |
| portal | 低 | 低 | 可忽略 | 低 | |
| uic | 低 | 低 | 可忽略 | 低 | |
| alarm | 低 | 低 | 可忽略 | 低 | |
| sender | 低 | 低 | 可忽略 | 低 | |
| links | 低 | 低 | 可忽略 | 低 |
根据资源消耗特点、高可用要求等,可以尝试做一些混合部署。比如,
- transfer&graph&judge是Open-Falcon的三大件,承受的压力最大、资源消耗最大、但彼此间又不冲突,可以考虑在高配服务器上混合部署这三个子服务
- alarm&sender&links资源消耗较少、但稳定性要求高,可以选择低配稳定机型、单独部署
- hbs资源消耗稳定、不易受外部影响,可以选择低配主机、单独部署
- dashboard、portal、uic等是web应用,资源消耗都比较小、但易受用户行为影响,可以选择低配主机、混合部署、并留足余量
- query受用户行为影响较大、资源消耗波动较大,建议选择低配主机、单独部署、留足余量
1.7. 踩过的坑
为了提高服务器的资源利用率,单机部署了同一子服务的多个实例。这种情况会加大系统运维的难度、可能占用较多的人力资源。可以考虑使用低配服务器,来解决单机资源使用率低的问题。
自监控实践
本文介绍了,小米公司在 Open-Falcon集群自监控方面 的一些实践。
1.1. 概述
我们把对监控系统的监控,称为监控系统的自监控。自监控的需求,没有超出监控的业务范畴。同其他系统一样,自监控要做好两方面的工作: 故障报警和状态展示。故障报警,要求尽量实时的发现故障、及时的通知负责人,要求高可用性。状态展示,多用于事前预测、事后追查,实时性、可用性要求 较故障报警 低一个量级。下面我们从这两个方面,分别进行介绍。
1.2. 故障报警
故障报警相对简单。我们使用第三方监控组件AntEye,来监控Open-Falcon实例的健康状况。
Open-Falcon各个组件,都会提供一个描述自身服务可用性的自监控接口,描述如下。AntEye服务会定时巡检、主动调用Open-Falcon各实例的自监控接口,如果发现某个实例的接口没有如约返回"ok",就认为这个组件故障了(约定),就通过短信、邮件等方式 通知相应负责人员。为了减少报警通知的频率,AntEye采用了简单的报警退避策略,并会酌情合并一些报警通知的内容。
值得注意的是,原来故障发现功能是Open-Falcon的Task组件的一个代码片段。后来,为了满足多套部署的需求,我们把故障发现的逻辑从Task中剔除,转而使用独立的第三方监控组件AntEye。
1.3. 状态展示
状态展示,是将Open-Falcon各组件实例的状态数据,以图形化的形式展示出来,方便人的查看。鉴于实时性、可用性要求不高,我们选择Open-Falcon来做自身状态数据的存储、展示(用Open-Falcon监控Open-Falcon,自举了),剩下的工作就是状态数据的采集了。
有了Open-Falcon自身状态数据的Screen,运维就会变得很方便: 每天早上开始正式工作之前,花10分钟时间看看这些历史曲线,小则发现已经发生的问题,大则预测故障、评估容量等。
1.4. 总结
对于自监控,简单整理下。
神医难自医。大型监控系统的故障监控,往往需要借助第三方监控系统(AntEye)。第三方监控系统,越简单、越独立,越好。
一个系统,充分暴露自身的状态数据,才更有利于维护。我们尽量,把状态数据的存储容器做成通用的、把获取状态数据的接口做成一致的、把状态数据的采集服务做成集中式的,方便继承、方便运维。当前,程序获取自己状态数据的过程还不太优雅、入侵严重。
1.5. 附录
1.5.1. 1. Open-Falcon状态指标
以下是Open-Falcon较重要的状态指标(非全部)及其含义。
## transfer
RecvCnt.Qps 接收数据的Qps
GraphSendCacheCnt 转发数据至Graph的缓存长度
SendToGraphCnt.Qps 转发数据至Graph的Qps
SendToGraphDropCnt.Qps 转发数据至Graph时, 由于缓存溢出而Drop数据的Qps
SendToGraphFailCnt.Qps 转发数据至Graph时, 发送数据失败的Qps
JudgeSendCacheCnt 转发数据至Judge的缓存长度
SendToJudgeCnt.Qps 转发数据至Judge的Qps
SendToJudgeDropCnt.Qps 转发数据至Judge时, 由于缓存溢出而Drop数据的Qps
SendToJudgeFailCnt.Qps 转发数据至Judge时, 发送数据失败的Qps
## graph
GraphRpcRecvCnt.Qps 接收数据的Qps
GraphQueryCnt.Qps 处理Query请求的Qps
GraphLastCnt.Qps 处理Last请求的Qps
IndexedItemCacheCnt 已缓存的索引数量,即监控指标数量
IndexUpdateAll 全量更新索引的次数
## query
HistoryRequestCnt.Qps 历史数据查询请求的Qps
HistoryResponseItemCnt.Qps 历史数据查询请求返回点数的Qps
LastRequestCnt.Qps Last查询请求的Qps
## task
CollectorCronCnt 自监控状态数据采集的次数
IndexDeleteCnt 索引垃圾清除的次数
IndexUpdateCnt 索引全量更新的次数
## gateway
RecvCnt.Qps 接收数据的Qps
SendCnt.Qps 发送数据至transfer的Qps
SendDropCnt.Qps 发送数据至transfer时,由于缓存溢出而Drop数据的Qps
SendFailCnt.Qps 发送数据至transfer时,发送失败的Qps
SendQueuesCnt 发送数据至transfer时,发送缓存的长度
## anteye
MonitorCronCnt 自监控进行状态判断的总次数
MonitorAlarmMailCnt 自监控报警发送邮件的次数
MonitorAlarmSmsCnt 自监控报警发送短信的次数
MonitorAlarmCallbackCnt 自监控报警调用callback的次数
## nodata
FloodRate nodata发生的百分比
CollectorCronCnt 数据采集的次数
JudgeCronCnt nodata判断的次数
NdConfigCronCnt 拉取nodata配置的次数
SenderCnt.Qps 发送模拟数据的Qps