机器学习算法-层次聚类AGNES
层次聚类方法对给定的数据集进行层次的分解,直到某种条件满足为止。具体又可分为:
凝聚的层次聚类:一种自底向上的策略,首先将每个对象作为一个簇,然后合并这些原子簇为越来越大的簇,直到某个终结条件被满足。
分裂的层次聚类:采用自顶向下的策略,它首先将所有对象置于一个簇中,然后逐渐细分为越来越小的簇,直到达到了某个终结条件。
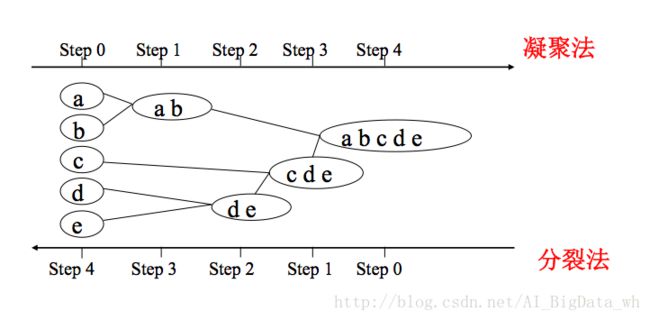
层次凝聚的代表是AGNES(AGglomerative NESting)算法。AGNES 算法最初将每个对象作为一个簇,然后这些簇根据某些准则被一步步地合并。两个簇间的相似度有多种不同的计算方法。聚类的合并过程反复进行直到所有的对象最终满足簇数目。
一、算法步骤
AGNES(自底向上凝聚算法)算法的具体步骤如下所示:
输入:包含 n 个对象的数据库。
输出:满足终止条件的若干个簇。
(1) 将每个对象当成一个初始簇;
(2) REPEAT
(3) 计算任意两个簇的距离,并找到最近的两个簇;
(4) 合并两个簇,生成新的簇的集合;
(5) UNTIL 终止条件得到满足。
二、距离计算
上述算法的关键在于如何计算聚类簇之间的距离?实际上每个簇是一个样本集合,因此只需要采用关于集合的某种距离即可。例如给定聚类簇 Ci 和 Cj ,两个簇的距离可以通过以下定义得到:

显然最小距离是由两个簇的最近样本决定、最大距离由两个簇的最远样本决定、均值距离由两个簇的中心位置决定、而平均距离则由两个簇的所有样本共同决定。当聚类距离由 dmin 、 dmax 或 davg 计算时,AGNES算法被相应地称为“单链接”、“全链接”或“均链接”算法。
三、算法举例
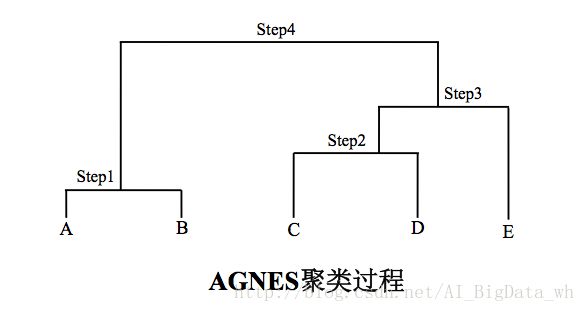
使用AGNES算法对下面的数据集进行聚类,以最小距离计算簇间的距离。刚开始共有5个簇: C1={A} 、 C2={B} 、 C3={C} 、 C4={D} 和 C5={E} 。
| 样本点 | A | B | C | D | E |
|---|---|---|---|---|---|
| A | 0 | 0.4 | 2 | 2.5 | 3 |
| B | 0.4 | 0 | 1.6 | 2.1 | 1.9 |
| C | 2 | 1.6 | 0 | 0.6 | 0.8 |
| D | 2.5 | 2.1 | 0.6 | 0 | 1 |
| E | 3 | 1.9 | 0.8 | 1 | 0 |
Step1. 簇 C1 和簇 C2 的距离最近,将二者合并,得到新的簇结构: C1={A,B} 、 C2={C} 、 C3={D} 和 C4={E} 。
| 样本点 | AB | C | D | E |
|---|---|---|---|---|
| AB | 0 | 1.6 | 2.1 | 1.9 |
| C | 1.6 | 0 | 0.6 | 0.8 |
| D | 2.1 | 0.6 | 0 | 1 |
| E | 1.9 | 0.8 | 1 | 0 |
Step2. 接下来簇 C2 和簇 C3 的距离最近,将二者合并,得到新的簇结构: C1={A,B} 、 C2={C,D} 和 C3={E} 。
| 样本点 | AB | CD | E |
|---|---|---|---|
| AB | 0 | 1.6 | 1.9 |
| CD | 1.6 | 0 | 0.8 |
| E | 1.9 | 0.8 | 0 |
Step3. 接下来簇 C2 和簇 C3 的距离最近,将二者合并,得到新的簇结构: C1={A,B} 和 C2={C,D,E} 。
| 样本点 | AB | CDE |
|---|---|---|
| AB | 0 | 1.6 |
| CDE | 1.6 | 0 |
Step4. 最后只剩下簇 C1 和簇 C2 ,二者的最近距离为1.6,将二者合并,得到新的簇结构: C1={A,B,C,D,E} 。
四、终止条件
层次聚类方法的终止条件:
- 设定一个最小距离阈值 d¯ ,如果最相近的两个簇的距离已经超过 d¯ ,则它们不需再合并,聚类终止。
- 限定簇的个数 k ,当得到的簇的个数已经达到 k ,则聚类终止。
五、算法性能分析
AGNES算法比较简单,但一旦一组对象被合并,下一步的处理将在新生成的簇上进行。已做处理不能撤消,聚类之间也不能交换对象。增加新的样本对结果的影响较大。
假定在开始的时候有 n 个簇,在结束的时候有 1 个簇,因此在主循环中有 n 次迭代,在第 i 次迭代中,我们必须在 n−i+1 个簇中找到最靠近的两个进行合并。另外算法必须计算所有对象两两之间的距离,因此这个算法的复杂度为 O(n2) ,该算法对于 n 很大的情况是不适用的。
六、算法实战
AgglomerativeClustering是scikit-learn提供的层级聚类算法模型。一般只需要设置参数linkage和n_clusters,其中n_clusters是一个正整数,指定分类簇的数量;linkage是一个字符串,用于指定链接算法 :当其值为“ward”时表示采用单链接方法,值为“complete”时表示采用全链接方法,若取值为“average”时则使用均连接方法。
# -*- coding: utf-8 -*-
from sklearn import datasets
from sklearn.cluster import AgglomerativeClustering
import matplotlib.pyplot as plt
from sklearn.metrics import confusion_matrix
import pandas as pd
iris = datasets.load_iris()
irisdata = iris.data
clustering = AgglomerativeClustering(linkage='ward', n_clusters=3)
res = clustering.fit(irisdata)
print "各个簇的样本数目:"
print pd.Series(clustering.labels_).value_counts()
print "聚类结果:"
print confusion_matrix(iris.target,clustering.labels_)
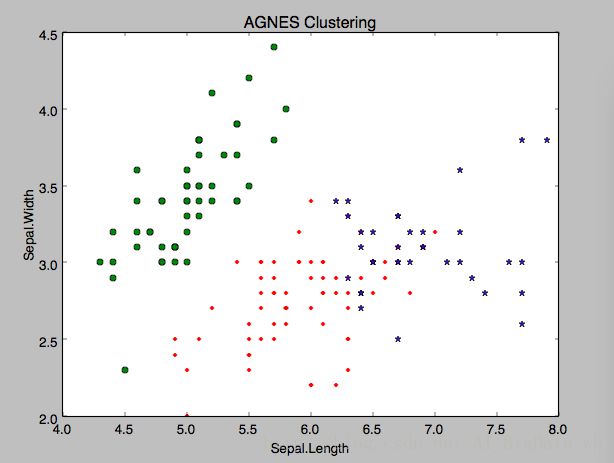
plt.figure()
d0 = irisdata[clustering.labels_==0]
plt.plot(d0[:,0],d0[:,1],'r.')
d1 = irisdata[clustering.labels_==1]
plt.plot(d1[:,0],d1[:,1],'go')
d2 = irisdata[clustering.labels_==2]
plt.plot(d2[:,0],d2[:,1],'b*')
plt.xlabel("Sepal.Length")
plt.ylabel("Sepal.Width")
plt.title("AGNES Clustering")
plt.show()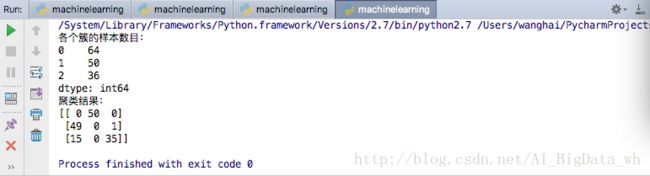
参考资料
- http://m.blog.csdn.net/Haiyang_Duan/article/details/77995665 Python机器学习——Agglomerative层次聚类
- http://scikit-learn.org/stable/modules/clustering.html#hierarchical-clustering 2.3.6. Hierarchical clustering
- https://item.jd.com/11867803.html 《机器学习》 周志华