NLP案例——命名实体识别(Named Entity Recongition)
NLP案例——命名实体识别(Named Entity Recongition)
命名实体识别是NLP里的一项很基础的任务,就是指从文本中识别出命名性指称项,为关系抽取等任务做铺垫。狭义上,是识别出人命、地名和组织机构名这三类命名实体(时间、货币名称等构成规律明显的实体类型可以用正则表达式等方式识别)。当然,在特定的领域中,会相应地定义领域内的各种实体类型。
小明 在 北京大学 的 燕园 看了 中国男篮 的一场比赛
PER ORG LOC ORG
汉语作为象形文字,相比于英文等拼音文字来说,针对中文的NER任务来说往往要更有挑战性,下面列举几点:
(1) 中文文本里不像英文那样有空格作为词语的界限标志,而且“词”在中文里本来就是一个很模糊的概念,中文也不具备英文中的字母大小写等形态指示
(2) 中文的用字灵活多变,有些词语在脱离上下文语境的情况下无法判断是否是命名实体,而且就算是命名实体,当其处在不同的上下文语境下也可能是不同的实体类型
(3) 命名实体存在嵌套现象,如“北京大学第三医院”这一组织机构名中还嵌套着同样可以作为组织机构名的“北京大学”,而且这种现象在组织机构名中尤其严重
(4) 中文里广泛存在简化表达现象,如“北医三院”、“国科大”,乃至简化表达构成的命名实体,如“国科大桥”。
专著 [1] 里比较详细地介绍了 NER 的各种方法(由于出版年限较早,未涵盖神经网络方法),这里笼统地摘取三类方法:
1. 基于规则的方法:
利用手工编写的规则,将文本与规则进行匹配来识别出命名实体。例如,对于中文来说,“说”、“老师”等词语可作为人名的下文,“大学”、“医院”等词语可作为组织机构名的结尾,还可以利用到词性、句法信息。在构建规则的过程中往往需要大量的语言学知识,不同语言的识别规则不尽相同,而且需要谨慎处理规则之间的冲突问题;此外,构建规则的过程费时费力、可移植性不好。
2. 基于特征模板的方法:
统计机器学习方法将 NER 视作序列标注任务,利用大规模语料来学习出标注模型,从而对句子的各个位置进行标注。常用的应用到 NER 任务中的模型包括生成式模型HMM、判别式模型CRF等。比较流行的方法是特征模板 + CRF的方案:特征模板通常是人工定义的一些二值特征函数,试图挖掘命名实体内部以及上下文的构成特点。对于句子中的给定位置来说,提特征的位置是一个窗口,即上下文位置。而且,不同的特征模板之间可以进行组合来形成一个新的特征模板。CRF的优点在于其为一个位置进行标注的过程中可以利用到此前已经标注的信息,利用Viterbi解码来得到最优序列。对句子中的各个位置提取特征时,满足条件的特征取值为1,不满足条件的特征取值为0;然后把特征喂给CRF,training阶段建模标签的转移,进而在inference阶段为测试句子的各个位置做标注。关于这种方法可以参阅文献 [2] 和 [3]。
3. 基于神经网络的方法:
近年来,随着硬件能力的发展以及词的分布式表示(word embedding)的出现,神经网络成为可以有效处理许多NLP任务的模型。这类方法对于序列标注任务(如CWS、POS、NER)的处理方式是类似的,将token从离散one-hot表示映射到低维空间中成为稠密的embedding,随后将句子的embedding序列输入到RNN中,用神经网络自动提取特征,Softmax来预测每个token的标签。这种方法使得模型的训练成为一个端到端的整体过程,而非传统的pipeline,不依赖特征工程,是一种数据驱动的方法;但网络变种多、对参数设置依赖大,模型可解释性差。此外,这种方法的一个缺点是对每个token打标签的过程中是独立的分类,不能直接利用上文已经预测的标签(只能靠隐状态传递上文信息),进而导致预测出的标签序列可能是非法的,例如标签B-PER后面是不可能紧跟着I-LOC的,但Softmax不会利用到这个信息。
学界提出了 LSTM-CRF 模型做序列标注。文献[4][5]在LSTM层后接入CRF层来做句子级别的标签预测,使得标注过程不再是对各个token独立分类。引入CRF这个idea最早其实可以追溯到文献[6]中。文献[5]还提出在英文NER任务中先使用LSTM来为每个单词由字母构造词并拼接到词向量后再输入到LSTM中,以捕捉单词的前后缀等字母形态特征。文献[8]将这个套路用在了中文NER任务中,用偏旁部首来构造汉字。关于神经网络方法做NER,可以看博客[9] ,介绍的非常详细~
基于字的BiLSTM-CRF模型
使用基于字的BiLSTM-CRF模型,主要参考的是文献[4,5]。使用Bakeoff-3评测中所采用的的BIO标注集,即B-PER、I-PER代表人名首字、人名非首字,B-LOC、I-LOC代表地名首字、地名非首字,B-ORG、I-ORG代表组织机构名首字、组织机构名非首字,O代表该字不属于命名实体的一部分。如:
小 明 在 北 京 大 学 的 燕 园
B-PER I-PER O B-ORG I-ORG I-ORG I-ORG O B-LOC I-LOC
这里当然也可以采用更复杂的BIOSE标注集。
以句子为单位,将一个含有n个字的句子(字的序列)记作:
![]()
其中,![]() 表示句子的第i个字在字典中的id,进而可以得到每个子的one-hot向量,维数是字典大小。
表示句子的第i个字在字典中的id,进而可以得到每个子的one-hot向量,维数是字典大小。
模型的第一层是look-up层,利用预训练或随机初始化的embedding矩阵将句子中的每个字![]() 由one-hot向量映射为低维稠密的字向量(character embedding)
由one-hot向量映射为低维稠密的字向量(character embedding)![]() ,d是embedding的维度。在输入下一层之前,设置dropout以缓解过拟合。
,d是embedding的维度。在输入下一层之前,设置dropout以缓解过拟合。
模型的第二层是双向LSTM层,自动提取句子特征。将一个句子的各个字的character embedding序列![]()
![]() 作为双向LSTM各个时间步的输入,再将正向LSTM输出的隐状态序列
作为双向LSTM各个时间步的输入,再将正向LSTM输出的隐状态序列![]() 与反向LSTM的
与反向LSTM的![]() 在各个位置输出的隐状态进行按位置拼接
在各个位置输出的隐状态进行按位置拼接![]() ,得到完整的隐状态序列
,得到完整的隐状态序列
![]()
在设置dropout后,接入一个线性层,将隐状态向量从m维映射到k维,k是标注集的标签数,从而得到自动提取的句子特征,记作矩阵![]() 。可以把
。可以把![]() 的每一维
的每一维![]() 都视作字
都视作字![]() 分类到第j个标签的打分值,如果再对P进行Softmax的话,就相当于对各个位置独立进行k类分类。但是这样对各个位置进行标注时无法利用已经标注过的信息,所以接下来将进入一个CRF层来进行标注。
分类到第j个标签的打分值,如果再对P进行Softmax的话,就相当于对各个位置独立进行k类分类。但是这样对各个位置进行标注时无法利用已经标注过的信息,所以接下来将进入一个CRF层来进行标注。
模型的第三层是CRF层,进行句子级的序列标注。CRF层的参数是一个![]() 的矩阵A,表示的是从第i个标签到第j个标签的转移得分,进而在一个位置进行标注的时候可以利用此前已经标注过的标签,之所以要加2是应为要为句子首部添加一个起始状态以及为句子尾部添加一个终止状态。如果记一个长度等于句子长度的标签序列
的矩阵A,表示的是从第i个标签到第j个标签的转移得分,进而在一个位置进行标注的时候可以利用此前已经标注过的标签,之所以要加2是应为要为句子首部添加一个起始状态以及为句子尾部添加一个终止状态。如果记一个长度等于句子长度的标签序列![]() ,那么模型对于句子x的标签等于y的打分为
,那么模型对于句子x的标签等于y的打分为
![]()
可以看出整个序列的打分等于各个位置的打分之和,而每个位置的打分由两部分得到,一部分是由LSTM输出![]() 决定,另一部分则由CRF的转移矩阵A决定。进而可以利用Softmax得到归一化后的概率:
决定,另一部分则由CRF的转移矩阵A决定。进而可以利用Softmax得到归一化后的概率:
![]()
模型训练时通过最大化对数似然函数,下式给出了对一个训练样本![]() 的对数似然:
的对数似然:
![]()
如果这个算法要式子实现的话,需要注意的是指数的和的对数要转换成![]() (Tensorflow有现成的CRF,PyTorch就要自己写了),在CRF中上式的第二项使用前向后向算法来高效计算。
(Tensorflow有现成的CRF,PyTorch就要自己写了),在CRF中上式的第二项使用前向后向算法来高效计算。
模型在预测过程(解码)时使用动态规划的Viterbi算法来求解最优路径:
![]()
整个模型的结构如下图所示:
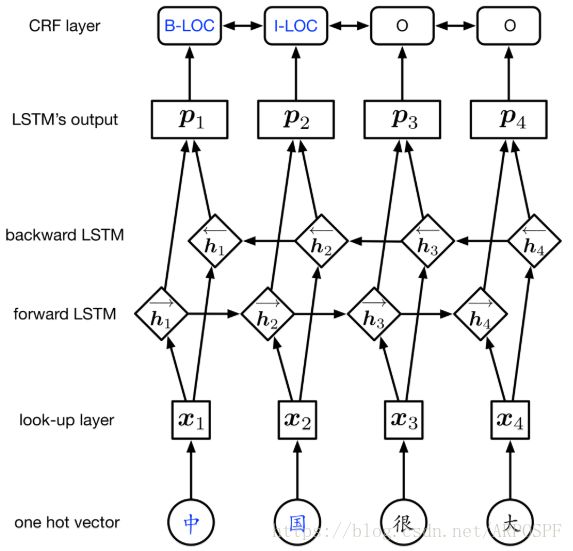
实验结果
关于CRF模型的特征模板是参考文献【3】做的。提取好特征之后使用CRF++工具包即可。
实验结果如下表所示:


参考资料:
[1] 《统计自然语言处理》
[2] 向晓雯. 基于条件随机场的中文命名实体识别[D]. , 2006.
[3] 张祝玉, 任飞亮, 朱靖波. 基于条件随机场的中文命名实体识别特征比较研究[C]//第 4 届全国信息检索与内容安全学术会议论文集. 2008.
[4] Huang Z, Xu W, Yu K. Bidirectional LSTM-CRF models for sequence tagging[J]. arXiv preprint arXiv:1508.01991, 2015.
[5] Lample G, Ballesteros M, Subramanian S, et al. Neural Architectures for Named Entity Recognition[C]//Proceedings of NAACL-HLT. 2016: 260-270.
[6] Collobert R, Weston J, Bottou L, et al. Natural language processing (almost) from scratch[J]. Journal of Machine Learning Research, 2011, 12(Aug): 2493-2537.
[7] Ma X, Hovy E. End-to-end sequence labeling via bi-directional lstm-cnns-crf[J]. arXiv preprint arXiv:1603.01354, 2016.
[8] Dong C, Zhang J, Zong C, et al. Character-Based LSTM-CRF with Radical-Level Features for Chinese Named Entity Recognition[C]//International Conference on Computer Processing of Oriental Languages. Springer International Publishing, 2016: 239-250.
[9] http://www.cnblogs.com/robert-dlut/p/6847401.html
[10]https://www.cnblogs.com/Determined22/p/7238342.html