Python 爬虫案例(二)--附件下载
Python 爬虫案例(二)
此篇文章将爬取的网站是:http://www.warrensburg-mo.com/Bids.aspx (有时候打开不一定会有标书,因为标书实时更新) 类型跟上一篇相似,用google浏览器,但在这篇中会讲如何下载附件,Scrapy框架中提供了FilesPipeline专门用于下载文件。另外以后发布的爬虫博客也会循序渐进:
爬取目标:下载附件,自己命名附件名称,解决下载链接的重定向问题
我们还是在csdn项目中操作(案例一中有创建过),小编比较懒:
首先在 items.py 中添加几项,因为我们这次多了download的步骤:
import scrapy
class CsdnItem(scrapy.Item):
title = scrapy.Field()
expiredate = scrapy.Field()
issuedate = scrapy.Field()
web_url = scrapy.Field()
bid_url = scrapy.Field() #这5个在上一篇讲过了
file_urls = scrapy.Field() # 附件链接接下来我们在左侧栏的spiders文件下面创建一个Python File,取名为warrensburg,系统会自动生成一个warrensburg.py的爬虫文件:
import scrapy
import datetime
from scrapy.http import Request
from CSDN.items import CsdnItem
class WarrensburgSpider(scrapy.Spider):
name = 'warrensburg'
start_urls = ['http://www.warrensburg-mo.com/Bids.aspx']
domain = 'http://www.warrensburg-mo.com/'
def parse(self, response):
#xpath定位找出bid所在的区域
result_list = response.xpath("//*[@id='BidsLeftMargin']/..//div[5]//tr")
for result in result_list:
item = CsdnItem()
title1 = result.xpath("./td[2]/span[1]/a/text()").extract_first()
if title1:
item["title"] = title1
item["web_url"] = self.start_urls[0]
#每一条bid的URL
urls = self.domain + result.xpath("./td[2]/span[1]/a/@href").extract_first()
item['bid_url'] = urls
#将每条URL交给下一个函数进行页面解析
yield Request(urls, callback=self.parse_content, meta={'item': item})
def parse_content(self, response):
item = response.meta['item']
#这些都和案例一中的类似
issuedate = response.xpath("//span[(text()='Publication Date/Time:')]/following::span[1]/text()").extract_first()
item['issuedate'] = issuedate
expireDate = response.xpath("//span[(text()='Closing Date/Time:')]/following::span[1]/text()").extract_first()
#之所以在截至日期这里多写一个if判断,是因为小编发现有些bids里面的截止日期是open util contracted
#所以我们遇到这种情况就设置截止日期为明天
if 'Open Until Contracted' in expireDate:
#就是那系统现在的时间 + 一天 = 明天
expiredate1 = (datetime.datetime.now() + datetime.timedelta(days=1)).strftime('%m/%d/%Y')
else:
expiredate1 = expireDate
item['expiredate'] = expiredate1
#我们将要下载的附件放入一个列表里面
file_list = []
file_list1 = response.xpath("//div[@class='relatedDocuments']/a/@href").extract()
if file_list1:
#有的标书会有不止一个附件,所以这里用for循环
for listurl in file_list1:
file_list.append(self.domain + listurl)
item['file_urls'] = file_list
yield item接下来是setting.py文件:
# Obey robots.txt rules
ROBOTSTXT_OBEY = False #将这行改为False
ITEM_PIPELINES = {
'scrapy.pipelines.files.MyFilesPipeline':1 #调用scrapy自带的pipelines用于下载文件
}
FILES_STORE = '/Users/agnes/Downloads' #这是下载的文件的存储路径在terminal中运行代码:
scrapy crawl warrensburg
运行完后发现,文件根本没被下载下来,然后发现warning中显示301,那么这是什么问题呢??
因为 MEDIA_ALLOW_REDIRECTS 这个问题,在自带的FilesPipeline中这项默认是False的,那么要将这项改为True就可以啦。。。修正后的setting.py代码:
# Obey robots.txt rules
ROBOTSTXT_OBEY = False #将这行改为False
ITEM_PIPELINES = {
'scrapy.pipelines.files.MyFilesPipeline':1 #调用scrapy自带的pipelines用于下载文件
}
FILES_STORE = '/Users/agnes/Downloads' #这是下载的文件的存储路径
MEDIA_ALLOW_REDIRECTS = True运行后又发现,下载下来的文件名称是一串‘乱码’,而且没有文件后缀,那么我们现在来解决这个问题,我们先来看一下scrapy自带的FilesPipeline的源码:

其中的file_download函数调用了file_path函数,给出了文件的path,那么我们现在将这个file_download函数重写,让它可以获取文件类型并给出新的path,我们打开pipelines.py这个文件:
from scrapy.pipelines.files import FilesPipeline,BytesIO,md5sum #这些都要导入
from urllib import parse
import re
class MyFilesPipeline(FilesPipeline): #在FilesPipeline的基础上创建了自己的pipeline
def file_downloaded(self, response, request, info): #函数名称和原FilesPipeline中的一样
pattern = re.compile(r'filename=(.*)') #文件名就是filename后面的字符串
#利用Content-Disposition获取文件类型,
containFileName = response.headers.get('Content-Disposition').decode('utf-8')
if not containFileName:
containFileName = response.headers.get('content-disposition').decode('utf-8')
#根据pattern在containFileName中找对应的字符串
file_name1 = pattern.search(containFileName).group(1)
#解码,例如文件名里边带有的%20,通过解码可以转换成空格,如果没有这步,生成的文件名称则带有%20,这行可以删掉自己试试
file_name2 = parse.unquote(file_name1)
path = 'full/%s' % (file_name2) #新的path在full文件夹中
buf = BytesIO(response.body) #以下这些照写
checksum = md5sum(buf)
buf.seek(0)
self.store.persist_file(path, buf, info)
return checksum然后改下setting.py:
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
ITEM_PIPELINES = {
'CSDN.pipelines.MyFilesPipeline':1
}
FILES_STORE = '/Users/agnes/Downloads'
MEDIA_ALLOW_REDIRECTS = True在terminal中运行代码:
scrapy crawl warrensburg
我们找到文件存储的路径,打开full文件夹,结果如图:
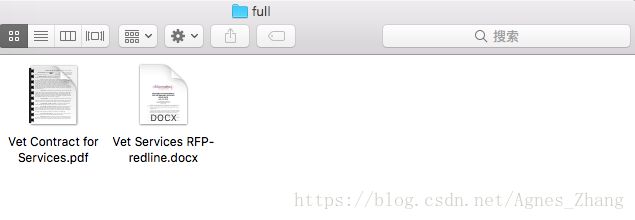
名称是根据path生成的,大家的结果可能跟我不一样,因为标书会实时更新,你们爬取下来的文件也会和我的不一样。