ConcurrentHashMap代码片段
ConcurrentHashMap代码片段
ConcurrentHashMap中,写操作的方法需要加锁(如put、remove、replace),读操作通常不需要加锁(个别情况下也需要加锁,如下面将介绍的containsValue方法)。
Map级方法
containsValue()、size()、isEmpty()三个方法中都利用了modCount,即修改记录。各个Segment的modCount将组成整个map的快照,通过两次扫描的快照比对,避免ABA问题。
containsValue 方法
public boolean containsValue(Object value) {
if (value == null)
throw new NullPointerException();
// See explanation of modCount use above
final Segment[] segments = this.segments;
int[] mc = new int[segments.length];
// Try a few times without locking
for (int k = 0; k < RETRIES_BEFORE_LOCK; ++k) {
int sum = 0;
int mcsum = 0;
for (int i = 0; i < segments.length; ++i) {
int c = segments[i].count;
mcsum += mc[i] = segments[i].modCount;
if (segments[i].containsValue(value))
return true;
}
boolean cleanSweep = true;
if (mcsum != 0) {
for (int i = 0; i < segments.length; ++i) {
int c = segments[i].count;
if (mc[i] != segments[i].modCount) {
cleanSweep = false;
break;
}
}
}
if (cleanSweep)
return false;
}
// Resort to locking all segments
for (int i = 0; i < segments.length; ++i)
segments[i].lock();
boolean found = false;
try {
for (int i = 0; i < segments.length; ++i) {
if (segments[i].containsValue(value)) {
found = true;
break;
}
}
} finally {
for (int i = 0; i < segments.length; ++i)
segments[i].unlock();
}
return found;
} - 首次遍历Segment并判断是否有目标value,同时创建Segments的modCount快照
- 如果在遍历过程中已经找到value,则返回true;否则再遍历一次
- 第二次遍历无需再判断是否有value,只需要判断各个Segment是否在这个间隔内发生过修改。如果发生过修改,则认为是“不干净”的扫描。
- 如果是“干净”的扫描,也就是在两次扫描间隔未发生变化,而在第一次扫描没有value,则返回false;否则,重复上述步骤,尝试再次判定
- 如果在限定的次数内始终无法准确判定出是否有value,则加锁后再判定
默认的判定次数内是不加锁的,这是为了尽量避免因所操作造成的性能下降。但如果因为map的数据变更太频繁,始终得不到精确的结果(即不干净的扫描),则只能加锁
containsValue需要全局扫描,而containsKey只需要局部扫描。因为根据key值能将范围精确到某个Segment,而value不行
size方法
public int size() {
final Segment[] segments = this.segments;
long sum = 0;
long check = 0;
int[] mc = new int[segments.length];
// Try a few times to get accurate count. On failure due to
// continuous async changes in table, resort to locking.
for (int k = 0; k < RETRIES_BEFORE_LOCK; ++k) {
check = 0;
sum = 0;
int mcsum = 0;
for (int i = 0; i < segments.length; ++i) {
sum += segments[i].count;
mcsum += mc[i] = segments[i].modCount;
}
if (mcsum != 0) {
for (int i = 0; i < segments.length; ++i) {
check += segments[i].count;
if (mc[i] != segments[i].modCount) {
check = -1; // force retry
break;
}
}
}
if (check == sum)
break;
}
if (check != sum) { // Resort to locking all segments
sum = 0;
for (int i = 0; i < segments.length; ++i)
segments[i].lock();
for (int i = 0; i < segments.length; ++i)
sum += segments[i].count;
for (int i = 0; i < segments.length; ++i)
segments[i].unlock();
}
if (sum > Integer.MAX_VALUE)
return Integer.MAX_VALUE;
else
return (int)sum;
} - 首次遍历Segment并累加count,同时创建Segments的modCount快照
- 再次遍历,维护另一份累加值check,同时比对快照,如果发生过修改,check置-1
- 两次遍历结果不同,则重复上面过程;如果相同,则返回累加值(注意对MAX_VALUE的判断和操作)。
- 如果在限定的次数内始终无法准确判定出是否有value,则加锁后再判定
isEmpty方法
public boolean isEmpty() {
final Segment[] segments = this.segments;
int[] mc = new int[segments.length];
int mcsum = 0;
for (int i = 0; i < segments.length; ++i) {
if (segments[i].count != 0)
return false;
else
mcsum += mc[i] = segments[i].modCount;
}
if (mcsum != 0) {
for (int i = 0; i < segments.length; ++i) {
if (segments[i].count != 0 ||
mc[i] != segments[i].modCount)
return false;
}
}
return true;
} 同样两次遍历,通过快照判断这个时间间隔内是否发生过修改。如果两次扫描中任一次发现count值不为0,则返回false。关键在于,即使第二次扫描发现count为0,但只要两次扫描间发生过修改,就返回false。
put、get、remove等map常用方法
利用hash值定位到某一个Segment,再调用Segment的对应方法
int hash = hash(key.hashCode());
return segmentFor(hash).xxx()Segment级方法
get方法
V get(Object key, int hash) {
if (count != 0) { // read-volatile
HashEntry e = getFirst(hash);
while (e != null) {
if (e.hash == hash && key.equals(e.key)) {
V v = e.value;
if (v != null)
return v;
return readValueUnderLock(e); // recheck
}
e = e.next;
}
}
return null;
} - 按hash值定位到hash桶,得到链表头结点。
- 按key在链表中寻找目标
- 如果目标的value不为空,返回其值;如果value值为空,则在加锁条件下返回值
插入操作时是不允许value为空的,因此value为空将发生在编译器对HashEntry的初始化过程进行重排序时
rehash方法
void rehash() {
HashEntry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity >= MAXIMUM_CAPACITY)
return;
HashEntry[] newTable = HashEntry.newArray(oldCapacity<<1);
threshold = (int)(newTable.length * loadFactor);
int sizeMask = newTable.length - 1;
for (int i = 0; i < oldCapacity ; i++) {
HashEntry e = oldTable[i];
if (e != null) {
HashEntry next = e.next;
int idx = e.hash & sizeMask;
// Single node on list
if (next == null)
newTable[idx] = e;
else {
HashEntry lastRun = e;
int lastIdx = idx;
for (HashEntry last = next;
last != null;
last = last.next) {
int k = last.hash & sizeMask;
if (k != lastIdx) {
lastIdx = k;
lastRun = last;
}
}
newTable[lastIdx] = lastRun;
// Clone all remaining nodes
for (HashEntry p = e; p != lastRun; p = p.next) {
int k = p.hash & sizeMask;
HashEntry n = newTable[k];
newTable[k] = new HashEntry(p.key, p.hash,
n, p.value);
}
}
}
}
table = newTable;
} - 定义2倍于原数组的新数组
- 遍历原数组中的每个桶
- 对链表头结点计算新位置,如果链表上只有一个节点,直接将其放入新数组中的新位置
- 如果链表内有多个结点,这时并不是直接逐个创建新结点并重定位,而是考察是否有可重用的老结点。在链表中向后扫描,定位到某一个结点lastRun,从lastRun向后,所有结点在新数组中仍然在同一个桶中。链表中从头结点到lastRun前一个节点都需要创建新节点并放入新Map中,而lastRun开始的子链(为更形象一些,姑且称为尾链)直接一起放入新Map中,无需创建新节点。
- 更新table引用,指向新map
扩容(创建新数组)过程中,并不能把处理完的结点赋为null,因为可能还有线程在读旧map
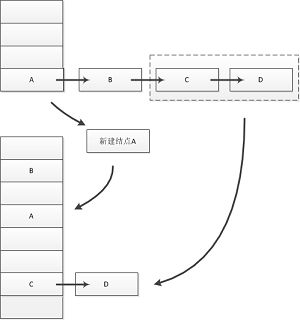
remove方法
V remove(Object key, int hash, Object value) {
lock();
try {
int c = count - 1;
HashEntry[] tab = table;
int index = hash & (tab.length - 1);
HashEntry first = tab[index];
HashEntry e = first;
while (e != null && (e.hash != hash || !key.equals(e.key)))
e = e.next;
V oldValue = null;
if (e != null) {
V v = e.value;
if (value == null || value.equals(v)) {
oldValue = v;
// All entries following removed node can stay
// in list, but all preceding ones need to be
// cloned.
++modCount;
HashEntry newFirst = e.next;
for (HashEntry p = first; p != e; p = p.next)
newFirst = new HashEntry(p.key, p.hash,newFirst,p.value);
tab[index] = newFirst;
count = c; // write-volatile
}
}
return oldValue;
} finally {
unlock();
}
} 定位到节点后,链表中该结点的后部不用变化,但从头结点开始,需要逐个拷贝为新节点并插入
