Barrier 性能如何?
在处理容器的多线程问题, 难免会用到加锁的方式来处理, iOS开发中, 锁有以下几种:
(1) 自旋锁 OSSpinLock
(2) 互斥锁 pthread_mutex, NSLock, @synchronized
(3) 读写锁 pthread_rwlock
(5) 递归锁 NSRecursiveLock, pthread_mutex(recursive)
(6) 信号量 dispatch_semaphore
(7) 分布锁 NSDistributedLock
(8) 条件变量 NSConditionLock
(9) 栅栏 GCD Barrier
单独加锁的性能,可以参考 不在安全的OSSpinLock 这篇文章的demo测试, 结果如下:
 其中并没有比较 Lock 和 GCD Barrier 的性能
其中并没有比较 Lock 和 GCD Barrier 的性能
在 queue+barrier性能真的很好吗?中作者比较了对于属性加锁和GCD Barrier的性能, 结果显示
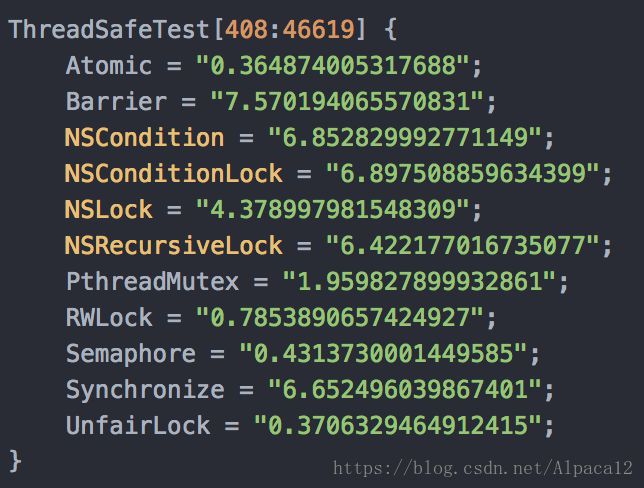
atomic加锁方式的效率最高的,并发队列+barrier方式竟然是最慢的,比atomic慢了20倍。这个结果令人大跌眼镜, 我不禁问自己为什么Barrier的方式如此之慢, Matt Galloway 在 《Effective Objective-C 2.0》 书中41条推荐派发队列, 而非锁方式对容器进行保护呢? 而且书中作者也提到了@synchronized 和 递归锁 NSRecursiveLock 的方式, 并指出GCD的方案更加简单和高效, 这与我们的测试结论大相径庭, 因此设计另一种测试方案, 不仅仅是对属性加锁, 而是用dispatch_semaphore, pthread_mutex(recursive), NSRecursiveLock 和 Barrier 对数组加锁, 然后对改数组做读写操作, 测试性能

数据加锁方式, 可以参考 YYThreadSafeArray 的做法, 核心代码
dispatch_semaphore 加锁方式
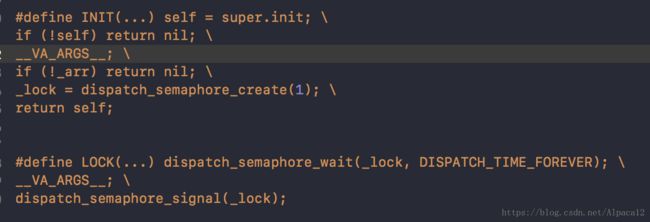
pthread_mutex(recursive) 加锁方式
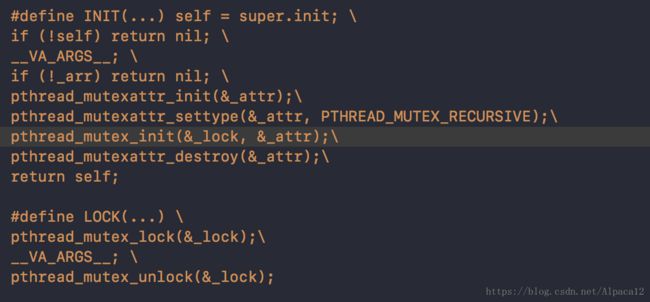
pthread_mutex 加锁方式
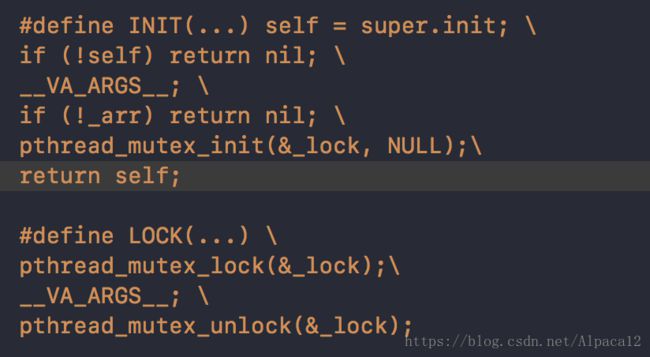
Barrier 方式

测试核心代码
iPhone 8 模拟器,11.4系统,ARC内存管理模式,dispatch_apply + 并发 queue 执行 10w 次,属性的读写操作比例为5:1,测试并发queue+barrier, pthread_mutex, pthread_mutex(recursive), dispatch_semaphore, NSRecursiveLock等5种方案的效率,连续测试50次

结果:

耗时: Barrier < Semaphore < pthread_mutex < pthread_mutex(recursive) < NSRecursiveLock
同时 dispatch_semaphore 和 pthread_mutex 等非递归锁存在死锁问题:
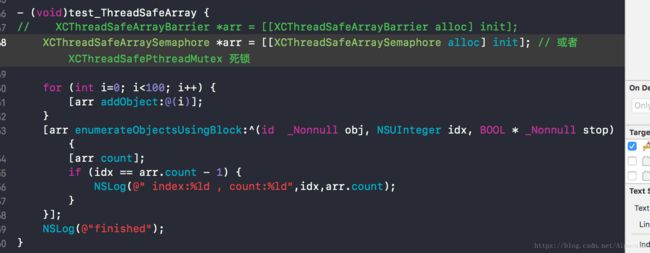
在枚举的时候加锁了, 如果再调用其count方法, 就造成了死锁问题, 这就需要可重入的锁来解决, 及递归锁. 同时Barrier也可以解决这个问题.
因此, 结合性能和锁的问题, 对于容器类的多线程问题推荐使用Barrier实现.
因水平有限, 如有错误, 欢迎拍砖.
Demo