信息熵与贝叶斯网络
一、信息熵
1.相对熵
又称互熵,交叉熵,KL散度。设p(x)、q(x)是X中取值的两个概率分布,则p对q的相对熵是
相对熵可以度量两个随机变量的“距离”
2.互信息
两个随机变量X,Y的互信息,定义为X,Y的联合分布和独立分布乘积的相对熵。

3.信息增益(可用于决策树构建)
信息增益表示得知特征A的信息而使得类X的信息的不确定性减少的程度。
定义:特征A对训练数据集D的信息增益g(D,A),定义为集合D的经验熵H(D)与特征A给定条件下D的经验条件熵H(D|A)之差,即g(D,A)=H(D)-H(D|A),显然,这即为训练数据集D和特征A的互信息。
二、贝叶斯网络
1.贝叶斯公式

给定某些样本D,在这些样本中计算某些结论A1、A2、.........An出现的概率,即P(Ai|D)
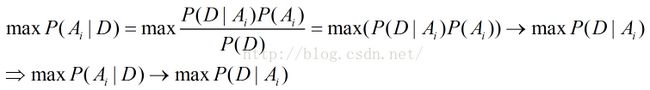
第一个等式:贝叶斯公式;
第二个等式:样本给定,则对于任何Ai,P(D)均为常数,仅为归一化因子;
第三个箭头:若这些结论A1,A2,.....An的先验概率相等(或近似),则得到最后一个等式,即第二行的公式。
2.朴素贝叶斯的假设
一个特征出现的概率,与其他特征(条件)独立(特征独立性),其实是对于给定分类的条件下,特征独立。
p(x1|c1)是指在垃圾邮件c1这个类别中,单词x1出现的概率。
定义符号
n1:在所有垃圾邮件中单词x1出现的次数。如果x1没有出现过,则n1=0;
n:属于c1类的所有文档的出现过的单词总数目。
得到公式: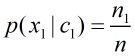
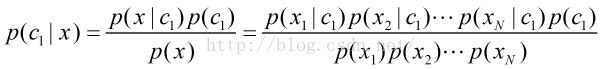
如果n1=0,n1/n为0,此时分子出现为0,不合理,不能只能因为没有单词x1,整体都变成零了。此时引入拉普拉斯平滑。
3.拉普拉斯平滑: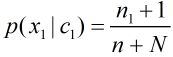 ,加1是为了避免分子为0,分母加N,相当于文档中所有单词出现的次数加1,因此修正分母是为了保证概率和为1。拉普拉斯平滑能够避免0/0带来的算法异常
,加1是为了避免分子为0,分母加N,相当于文档中所有单词出现的次数加1,因此修正分母是为了保证概率和为1。拉普拉斯平滑能够避免0/0带来的算法异常
4.贝叶斯网络
把某个研究系统中涉及的随机变量,根据是否条件独立绘制在一个有向图中,就形成了贝叶斯网络,其又称为有向无环图模型,是一种概率图模型,根据概率图的拓扑结构,考察一组随机变量{X1,X2,...Xn}及其n组条件概率分布。
一般而言,贝叶斯网络的有向无环图中的节点表示随机变量,它们可以是可观察到的变量,或隐变量,未知参数等。连接两个节点的箭头代表此两个随机变量是具有因果关系(或非条件独立)。若两个节点间以一个单箭头连接在一起,表示其中一个节点是“因”,另一个是“果”,两节点就会产生一个条件概率值。
每一节点在给定其直接前驱时,条件独立于其非后继。
举一个例子,如下图所示
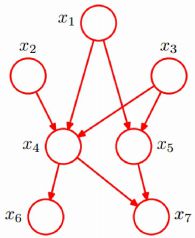
直观上:x1和x2独立;x6和x7在x4给定的条件下独立
x1,x2,...x7的联合分布![]()
5.特殊的贝叶斯网络
 (图像取自七月算法)
(图像取自七月算法)
结点形成一条链式网络,称作马尔科夫模型。A(i+1)只与Ai有关,与A1,...,A(i-1)无关。(属于贝叶斯网络判定条件独立head-to-tail型)
pLSA主题模型。
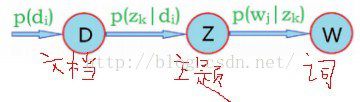
6.贝叶斯网络的建立:(1)领域知识(专家);
(2)无领域知识,则从数据角度,![]()
7.通过贝叶斯网络判定条件独立:
(1)在c给定的条件下,a,b被阻断,是独立的,条件独立tail-to-tail;
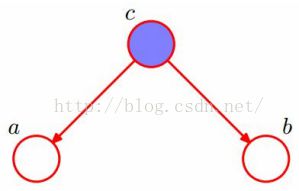 (图像取自七月算法)
(图像取自七月算法)
(2)在c给定的条件下,a,b被阻断,是独立的,条件独立head-to-tail;
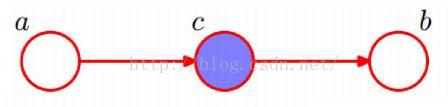 (图像取自七月算法)
(图像取自七月算法)
(3)在c未知的条件下,a,b被阻断,是独立的:head-to-head
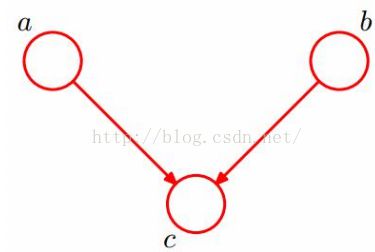 (图像取自七月算法)
(图像取自七月算法)
8.贝叶斯网络的用途
通过给定的样本数据,建立贝叶斯网络的拓扑结构和结点的条件概率分布参数。这往往需要借助先验知识和极大似然估计来完成。
在贝叶斯网络确定的结点拓扑结构和条件概率分布的前提下,可以使用该网络,对未知数据计算条件概率或后验概率,从而达到诊断、预测或者分类的目的。