1. 模型定义
逻辑回归属于基于概率分类的学习法. 基于概率的模式识别是指对模式x所对应的类别y的后验概率禁行学习.
其所属类别为后验概率最大时的类别:
预测类别的后验概率, 可理解为模式x所属类别y的可信度.
逻辑回归(logistic), 使用线性对数函数对分类后验概率进行模型化:
上式, 分母是满足概率总和为1的约束条件的正则化项, 参数向量维数为:
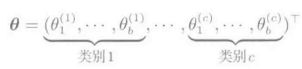
考虑二分类问题:
使用上述关系式, logistic模型的参数个数从2b降为b个, 模型简化为:
补充知识 -对数似然:
似然函数:
对数似然:
似然是n次相乘的结果, 一个非常小的值, 经常发生计算丢位现象, 因此, 一般用对数来解决, 即将乘法变换为加法防止丢位现象发生.
二分类逻辑回归模型改写为对数自然最大化:
已知关于参数的线性模型:
的间隔和逻辑回归的损失是等价的.

2. 从最大似然估计 (MLE)理解
1. 决策函数
一个机器学习的模型,实际上是把决策函数限定在某一组条件下,这组限定条件就决定了模型的假设空间。当然,我们还希望这组限定条件简单而合理。而逻辑回归模型所做的假设是:
这里的 g(h) 是sigmoid 函数,相应的决策函数为:
选择0.5作为阈值是一个一般的做法,实际应用时特定的情况可以选择不同阈值,如果对正例的判别准确性要求高,可以选择阈值大一些,对正例的召回要求高,则可以选择阈值小一些。
选择0.5作为阈值是一个一般的做法,实际应用时特定的情况可以选择不同阈值,如果对正例的判别准确性要求高,可以选择阈值大一些,对正例的召回要求高,则可以选择阈值小一些。
2. 参数求解
对数似然最大化
在逻辑回归模型中,令, 则
故似然度可表示为:
对数似然:
逻辑回归模型中,我们最大化似然函数和最小化交叉熵损失函数实际上是等价的。对于该优化问题,存在多种求解方法,这里以梯度下降的为例说明。梯度下降(Gradient Descent)又叫作最速梯度下降,是一种迭代求解的方法,通过在每一步选取使目标函数变化最快的一个方向调整参数的值来逼近最优值。
对于该优化问题,存在多种求解方法,这里以梯度下降求解为例说明。
- 给以初始值
- 随机选择一个训练样本
- 对于选定的训练样本, 已梯度上升方向对参数进行更新:
其中:
故:
L2约束的逻辑回归:
参数更新(梯度下降):
此处的, 在这里λ称作正则化参数,它通过平衡拟合训练的目标和保持参数值较小的目标。从而来保持假设的形式相对简单,来避免过度的拟合。
3. 从最小化Logstic损失来理解
回顾逻辑回归模型, 并考虑二分类:
逻辑斯蒂回归二分类模型的基本假设是输出Y=1的对数几率是输入x的线性函数,换句话说
对于二分类问题, 有:
令, , 结合(1)(2)式:
故:
这里得到了的决策函数, 综合(3)(4)得:
在 training data 上进行 maximum log-likelihood 参数估计:
等价于:
令, 此时目标函数是 strongly convex 的。接下来我们考虑用 gradient descent 来对目标函数进行优化。首先其 Gradient 是:
L2正则化: