Nearest Neighbor算法对Cifar-10数据集进行分类
1.preliminary
Nearest Neighbor 算法的思想是同一类型的东西总是有一些相似点,在某个空间里是聚集在一起的。比如说对于一直狗和鸡,属于两个不同的物种,鸡有两条腿而都狗有四条腿,狗的叫声是“汪汪”而鸡的叫声是“咯咯”。所以不同的特诊会使鸡和狗聚集在两块不同的区域。
一般在现实应用中是不会用1NN的,我们用的更多KNN,至于k的大小是多少,针对不同的问题答案是不一样的,这需要我们不断训练去调整参数,去测试模型是不是有过拟合。

边界线
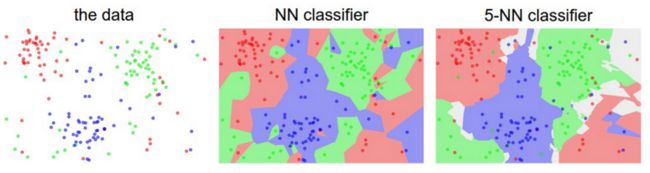
那问题来了,我们怎么来计算最近的k个点是哪几个点呢?
我们首先来了解一个定义,欧式距离(Euclidean distance)也称为欧几里得度量,通常采用的距离定义,它在m维空间中两个点之间的真实距离。在二维和三维空间中的欧式距离就是两点之间的距离。
二维的公式
ρ = sqrt( (x1-x2)^2+(y1-y2)^2 )三维的公式
ρ = sqrt( (x1-x2)^2+(y1-y2)^2+(z1-z2)^2 )
L1 norm,也就是我们经常听到的L1范数,指的是绝对值想加,又被称为曼哈顿距离。
L2 norm就是欧几里得距离。
Cifar-10数据集:http://www.cs.toronto.edu/~kriz/cifar.html

这个数据集总共有60000张图片,10个类,50000张图片作为训练集,10000张作为测试集,每个图片的大小是32*32
了解这些之后,我们再回到NN分类的问题上,放到这个问题上,我们知道图片是由像素组成的,每个像素有三个通道,分别是RGB,所以每张图片可以用32*32*3=3072个数组(0~255)的数字来表示,我们可以大致估算一下这60000图片都放到内存大概需要多少空间(假定整数占用4个字节),60000*3072*4=703M,有一个比较直观的了解,对后面计算时间就可以理解了。
从网站下好数据集之后,我们把这把训练数据变成50000*3072的二维数组,每一行数据表示一张训练图片,然后是label和测试数据数组。然后写好NN算法这个类,写起来很简单(采用L1距离),比如我们有两张图片I1和I2,他们的L1距离定义为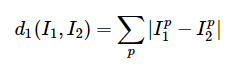
举个简单的例子,其中一个通道的计算为
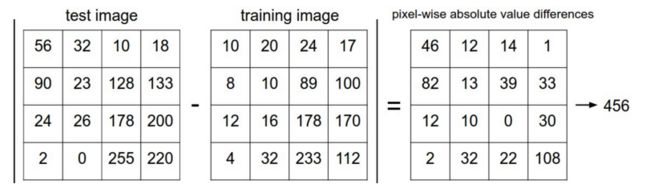
最后三个通道想加就能够算出这两个图片的曼哈顿距离了。
2.代码展示
NN
import numpy as np
class NearestNeighbor(object):
def __init__(self):
pass
def train(self, X, y):
""" X is N x D where each row is an example. Y is 1-dimension of size N """
# the nearest neighbor classifier simply remembers all the training data
self.Xtr = X
self.ytr = y
def predict(self, X):
""" X is N x D where each row is an example we wish to predict label for """
num_test = X.shape[0]
# lets make sure that the output type matches the input type
Ypred = np.zeros(num_test, dtype = self.ytr.dtype)
# loop over all test rows
for i in xrange(num_test):
# find the nearest training image to the i'th test image
# using the L1 distance (sum of absolute value differences)
distances = np.sum(np.abs(self.Xtr - X[i,:]), axis = 1)
min_index = np.argmin(distances) # get the index with smallest distance
Ypred[i] = self.ytr[min_index] # predict the label of the nearest example
return Ypred数据预处理以及调用
import numpy as np
from NearestNeighbor import NearestNeighbor
def unpickle(file):
import cPickle
fo = open(file, 'rb')
dict = cPickle.load(fo)
fo.close()
return dict
#get the training data
dataTrain = []
labelTrain = []
for i in range(1,6):
dic = unpickle("E:\python\cifar-10-batches-py\data_batch_"+str(i))
for item in dic["data"]:
dataTrain.append(item)
for item in dic["labels"]:
labelTrain.append(item)
#get test data
dataTest = []
labelTest = []
#do not know why the path is not just right as above,add a extra\
dic = unpickle("E:\python\cifar-10-batches-py\\test_batch")
for item in dic["data"]:
dataTest.append(item)
for item in dic["labels"]:
labelTest.append(item)
#print "dataTest:%d" %(len(dataTest))
#print "labelTest:%d" %(len(labelTest))
dataTr = np.asarray(dataTrain)
dataTs = np.asarray(dataTest)
labelTr = np.asarray(labelTrain)
labelTs = np.asarray(labelTest)
print dataTr.shape
nn = NearestNeighbor() # create a Nearest Neighbor classifier class
nn.train(dataTr, labelTr) # train the classifier on the training images and labels
Yte_predict = nn.predict(dataTs) # predict labels on the test images
# and now print the classification accuracy, which is the average number
# of examples that are correctly predicted (i.e. label matches)
print 'accuracy: %f' % ( np.mean(Yte_predict == labelTs) )最后来张截图, i7四代运行了大概 1h...

分类的准确率并不高,也就是猜概率的两倍多,就当拿来练练手好了,后面还能进行优化,比如改变K,改变判定相似性判定的公式。一句题外话,现在这个数据集用深度学习识别率已经达到95%,超过人类识别94%,看识别率排名。