python_KNN_sklearn包实现
之前说了KNN的算法解读,这次说一下代码的实践
本人不是专业的python使用者,所以就不按照KNN的算法写推到代码了,直接运用机器学历里面运用得比较多,而且比较简单的sklearn包
scikit-learn(简称sklearn)是目前最受欢迎,也是功能最强大的一个用于机器学习的Python库件。它广泛地支持各种分类、聚类以及回归分析方法比如支持向量机、随机森林、DBSCAN等等,由于其强大的功能、优异的拓展性以及易用性,目前受到了很多数据科学从业者的欢迎,也是业界相当著名的一个开源项目之一。
1、sklearn的安装
使用pip安装
sklearn:pip install -U scikit-learn
使用conda安装
sklearn:conda install scikit-learn
2、sklearn内置数据集
from sklearn import datasets
#导入内置数据集模块
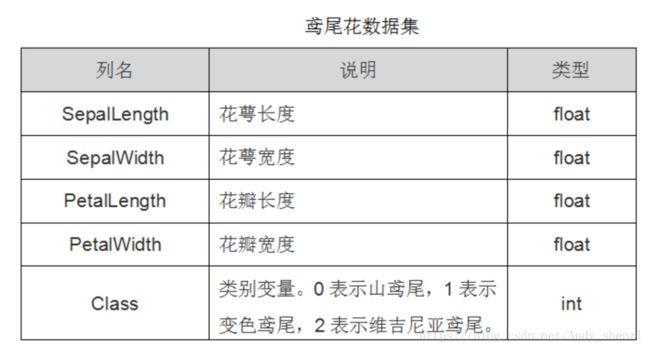
3、模型准备
#导入sklearn.neighbors模块中KNN类
from sklearn.neighbors import KNeighborsClassifier
#设置随机种子,不设置的话默认是按系统时间作为参数,因此每次调用随机模块时产生的随机数都不一样设置后每次产生的一样
import numpy as np
np.random.seed(0)
4、数据处理
iris=datasets.load_iris()
#导入鸢尾花的数据集,iris是一个类似于结构体的东西,内部有样本数据,如果是监督学习还有标签数据
iris_x=iris.data
#样本数据150*4二维数据,代表150个样本,每个样本4个属性分别为花瓣和花萼的长、宽
iris_y=iris.target
#长150的以为数组,样本数据的标签
indices = np.random.permutation(len(iris_x))
#permutation接收一个数作为参数(150),产生一个0-149一维数组,只不过是随机打乱的,当然她也可以接收一个一维数组作为参数,结果是直接对这个数组打乱
5、设置训练集和测试集
iris_x_train = iris_x[indices[:-10]]
#随机选取140个样本作为训练数据集
iris_y_train = iris_y[indices[:-10]]
#并且选取这140个样本的标签作为训练数据集的标签
iris_x_test = iris_x[indices[-10:]]
#剩下的10个样本作为测试数据集
iris_y_test = iris_y[indices[-10:]]
#并且把剩下10个样本对应标签作为测试数据及的标签
因为数据比较简单我们可以这样简单的设置,如果是比较复杂的模型的话还是建议用train_test_split来进行建模。
6、模型训练
knn = KNeighborsClassifier()
#定义一个knn分类器对象
knn.fit(iris_x_train, iris_y_train)
#调用该对象的训练方法,主要接收两个参数:训练数据集及其样本标签
7、模型预测
iris_y_predict = knn.predict(iris_x_test)
#调用该对象的测试方法,主要接收一个参数:测试数据集
probility=knn.predict_proba(iris_x_test)
#计算各测试样本基于概率的预测
neighborpoint=knn.kneighbors(iris_x_test[-1:],5,False)
#计算与最后一个测试样本距离在最近的5个点,返回的是这些样本的序号组成的数组
score=knn.score(iris_x_test,iris_y_test,sample_weight=None)
#调用该对象的打分方法,计算出准确率
8、打印结果
print('iris_y_predict = ')
print(iris_y_predict)
#输出测试的结果
print('iris_y_test = ')
print(iris_y_test)
#输出原始测试数据集的正确标签,以方便对比
print ('Accuracy:',score )
#输出准确率计算结果
print ('neighborpoint of last test sample:',neighborpoint)
print ('probility:',probility)

9、参数详解
初始化函数(构造函数) 它主要有一下几个参数:
n_neighbors=5
int 型参数:knn算法中指定以最近的几个最近邻样本具有投票权,默认参数为5
weights='uniform'
str参数: 即每个拥有投票权的样本是按什么比重投票,'uniform'表示等比重投票,'distance'表示按距离反比投票,[callable]表示自己定义的一个函数,这个函数接收一个距离数组,返回一个权值数组。默认参数为‘uniform’
algrithm='auto'
str参数:即内部采用什么算法实现。有以下几种选择参数:'ball_tree':球树、'kd_tree':kd树、'brute':暴力搜索、'auto':自动根据数据的类型和结构选择合适的算法。默认情况下是‘auto’。暴力搜索就不用说了大家都知道。具体前两种树型数据结构哪种好视情况而定。KD树是对依次对K维坐标轴,以中值切分构造的树,每一个节点是一个超矩形,在维数小于20时效率最高--可以参看《统计学习方法》第二章。ball tree 是为了克服KD树高维失效而发明的,其构造过程是以质心C和半径r分割样本空间,每一个节点是一个超球体。一般低维数据用kd_tree速度快,用ball_tree相对较慢。超过20维之后的高维数据用kd_tree效果反而不佳,而ball_tree效果要好,具体构造过程及优劣势的理论大家有兴趣可以去具体学习。
leaf_size=30
int参数 :基于以上介绍的算法,此参数给出了kd_tree或者ball_tree叶节点规模,叶节点的不同规模会影响数的构造和搜索速度,同样会影响储树的内存的大小。具体最优规模是多少视情况而定。
matric='minkowski'
str或者距离度量对象:即怎样度量距离。关于距离的介绍可以参考KNN算法解读里面的介绍,也可以参考这里。
metric_params=None
距离度量函数的额外关键字参数,一般不用管,默认为None
n_jobs=1
int参数 :指并行计算的线程数量,默认为1表示一个线程,为-1的话表示为CPU的内核数,也可以指定为其他数量的线程,这里不是很追求速度的话不用管,需要用到的话去看看多线程。
fit()
训练函数,它是最主要的函数。接收参数只有1个,就是训练数据集,每一行是一个样本,每一列是一个属性。它返回对象本身,即只是修改对象内部属性,因此直接调用就可以了,后面用该对象的预测函数取预测自然及用到了这个训练的结果。其实该函数并不是KNeighborsClassifier这个类的方法,而是它的父类SupervisedIntegerMixin继承下来的方法。
predict()
预测函数 接收输入的数组类型测试样本,一般是二维数组,每一行是一个样本,每一列是一个属性返回数组类型的预测结果,如果每个样本只有一个输出,则输出为一个一维数组。如果每个样本的输出是多维的,则输出二维数组,每一行是一个样本,每一列是一维输出。
predict_prob()
基于概率的软判决,也是预测函数,只是并不是给出某一个样本的输出是哪一个值,而是给出该输出是各种可能值的概率各是多少接收参数和上面一样返回参数和上面类似,只是上面该是值的地方全部替换成概率,比如说输出结果又两种选择0或者1,上面的预测函数给出的是长为n的一维数组,代表各样本一次的输出是0还是1.而如果用概率预测函数的话,返回的是n*2的二维数组,每一行代表一个样本,每一行有两个数,分别是该样本输出为0的概率为多少,输出1的概率为多少。而各种可能的顺序是按字典顺序排列,比如先0后1,或者其他情况等等都是按字典顺序排列。
score()
计算准确率的函数,接受参数有3个。 X:接收输入的数组类型测试样本,一般是二维数组,每一行是一个样本,每一列是一个属性。y:X这些预测样本的真实标签,一维数组或者二维数组。sample_weight=None,是一个和X第一位一样长的各样本对准确率影响的权重,一般默认为None.输出为一个float型数,表示准确率。内部计算是按照predict()函数计算的结果记性计算的。其实该函数并不是KNeighborsClassifier这个类的方法,而是它的父类KNeighborsMixin继承下来的方法。
kneighbors()
计算某些测试样本的最近的几个近邻训练样本。接收3个参数。X=None:需要寻找最近邻的目标样本。n_neighbors=None,表示需要寻找目标样本最近的几个最近邻样本,默认为None,需要调用时给出。return_distance=True:是否需要同时返回具体的距离值。返回最近邻的样本在训练样本中的序号。其实该函数并不是KNeighborsClassifier这个类的方法,而是它的父类KNeighborsMixin