elasticsearch-5.5.2入门教程
介绍
elasticsearch(以下简称es)是一个基于Lucene的搜索引擎. 它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。
基础概念
es中需要了解的基本概念有:
- 索引:含有相同属性的文档集合(可以用一个索引来代表消费者数据,另一个索引代表产品数据,通过名字来识别,英文字母小写,且不含中划线)
- 类型:索引可以定义一个或多个类型,文档必须属于一个类型(通常定义有相同字段的文档作为一个类型)
- 文档:文档是可以被索引的基本数据单位(一个用户的基本信息,一篇文章的数据等,是整个es最小的存储单位)
- 分片:每个索引都有多个分片,每个分片都是一个Lucene索引(类似数据库分库,化整为零,分散压力、提高效率)
- 备份:拷贝一份分片就完成了分片的备份,提高可用性、备份的分片可以执行搜索操作,分摊搜索压力,默认五个分片(创建索引时指定,后期无法修改)、一个备份(可以动态修改)
简单来说,索引可以类比“数据库(database)”,类型可以类比“表(table)”,文档可以类比”记录(record)”。
环境配置
- VMware
- Centos 7.5(CentOS-7-x86_64-Minimal-1804)
- Oracle jdk 1.8(必须1.8或以上)
- Node 8.2.1(必须6.0以上)
- MySQL 5.6.40
- Elastic Search 5.5.2
安装
单实例安装
centos中es不能以root用户启动,需要新建用户并授权去运行es
- 安装好jdk并配置环境变量(既然都学到es了,jdk安装配置应该没什么障碍)
- 运行
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-5.5.2.tar.gz下载tar包,tar –zxvf elasticsearch-5.5.2.tar.gz解压,cd elasticsearch-5.5.2/config进入config目录,会看到三个文件:elasticsearch.yml、jvm.options、log4j2.properties,编辑jvm.options文件,参考配置如下:
-Xms200m#默认2G过大,可能导致es无法启动
-Xmx200m#同上
保存退出。 sh ./bin/elasticsearch [-d],运行,-d表示后台启动。sh ./bin/elasticsearch [-d],运行,-d表示后台启动。- 启动完成后运行
curl localhost:9200,返回如下字符串表示安装成功。

安装插件
为了更直观的使用es,我们可以下载一个可视化head插件
在安装插件之前,需要安装6.0以上的node环境,下载地址: https://nodejs.org/download/release/v8.2.1/node-v8.2.1-linux-x64.tar.gz
安装好了node之后,再去下载head插件。
wget https://github.com/mobz/elasticsearch-head/archive/master.zip下载
unzip master.zip解压
cd **/elasticsearch-head-master进入目录
npm install 仅第一次需要安装,npm慢的话可以换成cnpm
npm run start 运行head插件
插件会在9100端口启动,因为es和head访问有跨域问题,所以需要改下配置:
cd **/elasticsearch-5.5.2/config进入es的config目录,编辑elasticsearch.yml文件,参考配置如下:
network.host: 172.16.24.100 #和其他结点通信的地址,此处是我虚拟机中centos的静态ip
http.cors.enabled: true
http.cors.allow-origin: “*”
保存退出。
cd **/elasticsearch-5.5.2切换到es,sh ./bin/elasticsearch –d,后台启动es
cd **/elasticsearch-head-master,切换到head目录,npm run start,插件会在9100端口启动(记得开放虚拟机中centos的端口),在浏览器中查看,效果如下:

多实例安装
以同一台服务器为例,分别在三个端口运行三个实例:
主结点放在elatsicsearch-5.5.2目录,两个从结点分别放在es_slave/es_slave1和es_slave/es_slave2下,首先编辑主结点config目录下的elasticsearch.yml文件,添加如下配置:
cluster.name: ibest #集群名称
node.name: master #结点名称
node.master: true #指定为主结点
保存退出,配置slave1结点config目录下的elasticsearch.yml文件:
cluster.name: ibest #集群名称,必须和主结点一致,否则无法加入集群
node.name: slave1 #结点名称
network.host: 172.16.24.100 #和其他结点通信的地址
http.port: 8200 #9200已经被主结点占用
discovery.zen.ping.unicast.hosts: [“172.16.24.100”] #发现主结点
保存退出,编辑config目录下的jvm.options文件,参考配置如下:
-Xms200m
-Xmx200m
保存退出,配置slave2结点config目录下的elasticsearch.yml文件,基本和slave一致:
cluster.name: ibest
node.name: slave2
network.host: 172.16.24.100
http.port: 8000
discovery.zen.ping.unicast.hosts: [“172.16.24.100”]
保存退出,编辑config目录下的jvm.options文件,参考配置如下:
-Xms200m
-Xmx200m
保存退出,依次启动三个结点和head插件,在head插件中查看效果如下:
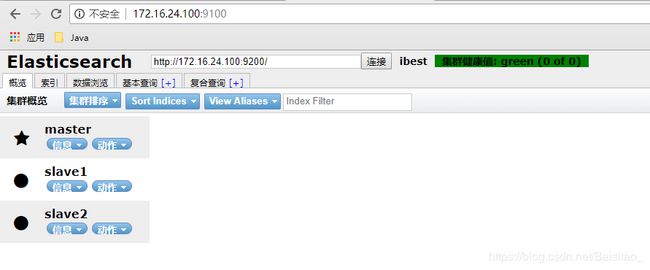
使用
创建索引
如果与已有的知识联系起来,创建索引相当于在MySQL中创建数据库(database),而不是MySQL中的索引(index)。es是基于Restful API的,所以我们通过restful API来创建索引。
API基本格式 http://。请求方式:Get、Post、Put、Delete。
es索引分为结构化索引和非结构化索引。结构化索引:类似MySQL,我们会对索引结构做预定义,包括字段名,字段类型等;非结构化索引:就类似Mongo,索引结构未知,根据具体的数据来update索引的mapping,我们此处创建结构化索引。
利用一些工具来模拟http请求,我是用的是Restlet Client (chrome插件),使用postman也一样,事实上与es配套的工具是Kibana,但是本质是一样,所以先从大家熟悉的工具入手。创建一个people索引,操作如下:
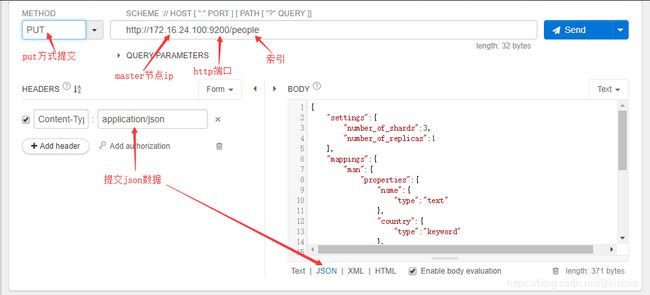
提交的json数据如下:
{
"settings":{
"number_of_shards":5,
"number_of_replicas":1
},
"mappings":{
"man":{
"properties":{
"name":{
"type":"text"
},
"country":{
"type":"keyword"
},
"age":{
"type":"integer"
},
"date":{
"type":"date",
"format":"yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
}
}
},
"woman":{
}
}
}
创建成功后,在head插件中查看,效果如下(我创建了people和book两个索引):
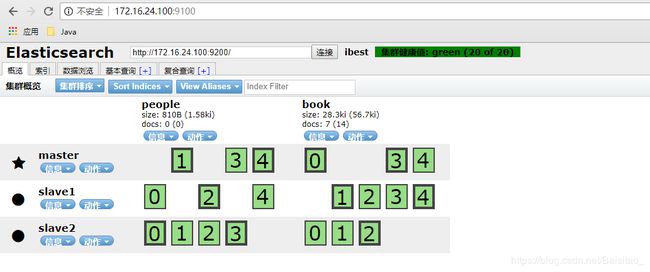
上图中,每个带数字方框都是es索引分片,纵看每一列,细线框是粗线框的备份。查看索引信息,可以看到索引结构和我们定义的一致。
至此,索引创建成功,people索引包含了两个类型:woman和man类似我们在MySQL中创建了people库,在people中创建了两个表: womam和man。
插入数据
数据插入分为指定ID插入和自动产生文档ID插入。
指定ID插入如下:

自动产生文档ID插入如下:

数据插入成功后,在head插件中查看数据:
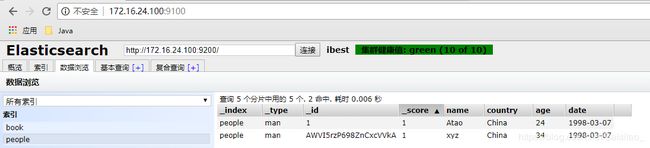
很容易看到指定id插入和自动生成id的区别。
更新数据
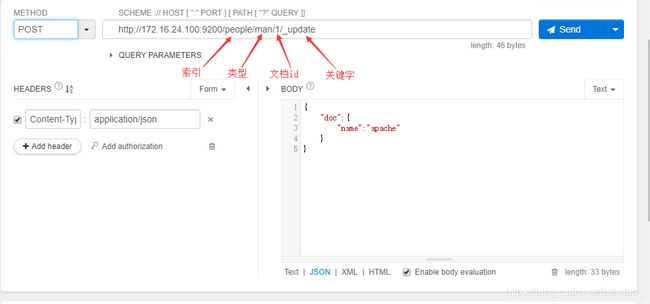
修改之后的数据如下:

删除
删除分为删除文档和删除索引,删除文档操作如下:
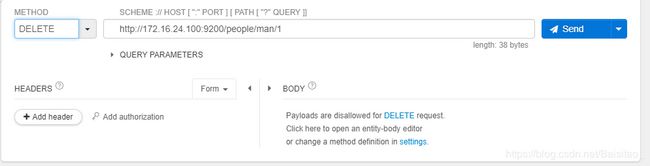
删除索引操作如下:

查询
查询是es核心功能,非常强大。由于篇幅有限,只简单介绍下,以后有时间再专门讲讲查询。查询分为简单查询,条件查询,聚合查询。先创建book索引,并添加一些数据。
{
"settings":{
"number_of_shards":5,
"number_of_replicas":1
},
"mappings":{
"novel":{
"properties":{
"word_count":{
"type":"integer"
},
"author":{
"type":"keyword"
},
"title":{
"type":"text"
},
"public_date":{
"format":"yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis",
"type":"date"
}
}
}
}
}
效果如下:
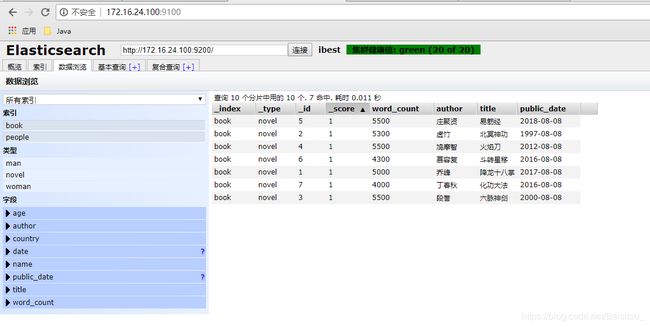
简单查询
查询id为1的文档,简单查询如下:

条件查询
查询全部数据,from和size是可选参数,默认是0和10。

条件查询并指定排序:

查询条件如下:
{
"query":{
"match":{
"title":"神功"
}
},
"sort":[
{
"public_date":{
"order":"desc"
}
}
]
}
如果不指定排序,则会按照返回结果的_score字段逆序排序。_score代表了搜索结果与搜索关键字的匹配度,值越大代表匹配度越高。不指定排序时,搜索title中含有“神功”关键字的文档,操作如下:
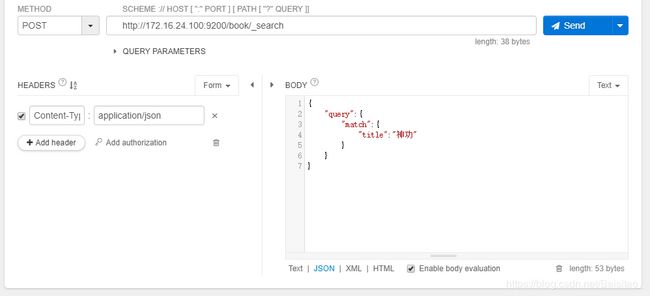
返回的结果如下:

仔细观察结果,搜索的时title含有“神功”的文档,结果出现了“北冥神功”、“化功大法”和”六脉神剑”。_score字段的值分别为1.8913201、0.7261542、0.2876821。为什么会出现这样的结果?需要知道一个概念叫“分词器”,分词器的作用就是分词。
“中文分词”指的是将一个汉字序列切分成一个个单独的词。分词就是将连续的字序列按照一定的规范重新组合成词序列的过程。我们知道,在英文的行文中,单词之间是以空格作为自然分界符的,而中文只是字、句和段能通过明显的分界符来简单划界,唯独词没有一个形式上的分界符。
Elasticsearch默认的分词器对中文的支持不是很好。所以需要单独安装插件来支持(以后讲查询的时候再讲),分词器根据自己的需求选取。回到上面的结果,es默认分词器会把搜索关键字“神功”分成“神”和”功”单独查询,所以会出现以上结果,由此可知,es并非关系数据库的替代品,而是作为补充,解决了关系数据库在搜索方面的不足。如果需要高亮显示,可以把查询参数改成
{
"query":{
"match":{
"title":"神功"
}
},
"highlight":{
"fields":{
"title":{}
}
}
}
聚合查询

查询条件如下(查询时去掉注释):
{
"aggs":{ //聚合关键字
"group_by_word_count":{ //名称,自定义
"terms":{
"field":"word_count" //要统计的列
}
},
"group_by_public_date":{ //名称,自定义
"terms":{
"field":"public_date" //要统计的列
}
}
}
}
与MySQL同步
目前mysql与elasticsearch常用的同步机制大多是基于插件实现的,常用的插件包括:elasticsearch-jdbc、elasticsearch-river-MySQL 、go-mysql-elasticsearch、 logstash-input-jdbc
其中最简单易用、性能稳定的插件为logstash-input-jdbc,本文也是基于logstash-input-jdbc实现实时同步。elasticsearch 5.x版本已经集成了logstash-input-jdbc插件,接下来是安装步骤:
- 下载公共秘钥:
rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch - 添加yum源:
vim /etc/yum.repos.d/logstash.repo,在文件中写入:[logstash-5.x] name=Elastic repository for 5.x packages baseurl=https://artifacts.elastic.co/packages/5.x/yum gpgcheck=1 gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch enabled=1 autorefresh=1 type=rpm-md - 安装logstash:
yum install logstash - 切换到logstash目录:
cd /usr/share/logstash,运行如下命令:
bin/logstash -e 'input { stdin { } } output { stdout {} }'
等待几秒钟,出现如下信息表示安装成功
The stdin plugin is now waiting for input: - 安装logstash-input-jdbc插件:
yum install gem
替换镜像:gem sources --add https://gems.ruby-china.org/ --remove https://rubygems.org/
验证是否成功:gem sources -l
如果出现https://gems.ruby-china.org/表示成功 - 修改Gemfile的数据源地址
cd /usr/share/logstash
vim Gemfile
修改source的值为https://gems.ruby-china.org/
vim Gemfile.jruby-1.9.lock
找到remote后面的链接,修改为https://gems.ruby-china.org/
保存退出,然后开始安装:./bin/logstash-plugin install logstash-input-jdbc - 创建一个文件夹,里面创建两个文件
mkdir etc
cd etc
touch wp.conf#文件名随意
touch wp.sql#文件名随意 - 配置wp.sql,就是需要同步的数据,例如:
SELECT id, title, author, word_count FROM novel - 配置wp.conf
vim wp.conf
输入以下内容(需要提前准备mysql的jar包,我放在目录/usr/share/logstash/mysql-connector-java-5.1.46/):
input {
jdbc {
# 数据库地址 端口 数据库名
jdbc_connection_string => "jdbc:mysql://172.16.24.101:3306/book"
# 数据库用户名
jdbc_user => "root"
# 数据库密码
jdbc_password => "root"
# mysql java驱动地址
jdbc_driver_library => "/usr/share/logstash/mysql-connector-java-5.1.46/mysql-connector-java-5.1.46-bin.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_paging_enabled => "true"
jdbc_page_size => "50000"
# sql 语句文件
statement_filepath => "/usr/share/logstash/etc/wp.sql"
schedule => "* * * * *"
type => "jdbc"
}
}
output {
stdout{
codec => json_lines
}
elasticsearch {
hosts => ["172.16.24.100:9200"]
index => "book"
document_type => "novel"
document_id => "%{id}"
}
}
- 启动,sql语句返回的数据会以json数据出现在控制台
./bin/logstash -f ./etc/wp.conf - es与MySQL同步分为:全量同步和增量同步,全量同步就是插件每次都会把es对应索引中的对应数据删掉,再把MySQL中的对应数据全部导入到es,上面的配置明显是全量同步。增量同步就是只同步MySQL中的改变量(新增和修改,至于删除,我们稍后讨论)。增量同步的前提就是MySQL中维护一个updatetime,用来记录每条记录最后修改时间。下面是增量同步的配置,在
/usr/share/logstash/etc目录下新建文件my_info用来记录上次运行相关参数,修改wp.conf文件:
input {
jdbc {
# 数据库地址 端口 数据库名
jdbc_connection_string => "jdbc:mysql://172.16.24.101:3306/book"
# 数据库用户名
jdbc_user => "root"
# 数据库密码
jdbc_password => "root"
# mysql java驱动地址
jdbc_driver_library => "/usr/share/logstash/mysql-connector-java-5.1.46/mysql-connector-java-5.1.46-bin.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_paging_enabled => "true"
jdbc_page_size => "50000"
## 增量同步相关配置
# 是否记录上次执行结果
record_last_run => true
# 是否需要记录某个column的值
use_column_value => true
# 需要记录的column(此处应该是updatetime字段,由于我之前没有维护此字段,所以用自增ID代替)
tracking_column => "id"
# 上次运行相关记录文件
last_run_metadata_path => "/usr/share/logstash/etc/my_info"
# 是否清除 last_run_metadata_path 的记录,如果为真那么每次都相当于从头开始查询所有的数据库记录
clean_run => "false"
# sql 语句文件
statement_filepath => "/usr/share/logstash/etc/wp.sql"
# 也可以直接写sql语句
# statement => "select * from ..."
# cron表达式
schedule => "* * * * *"
type => "jdbc"
# 是否将字段名称转小写
lowercase_column_names => "false"
}
}
filter {}
output {
stdout{
codec => json_lines
}
elasticsearch {
hosts => "172.16.24.100:9200"
index => "book"
document_type => "novel"
document_id => "%{id}"
}
}
保存退出,修改wp.sql文件:
SELECT id, title, author, word_count FROM novel where id >:sql_last_value
sql_last_value会自动取my_info中的值。
因为mysql 用的时区是东八区时间,而经过logstash到es上全部会转成是零时区时间,记录的:sql_last_value时间也可能会产生时间差,造成时间对不上,无法正常增量同步
增量同步时的删除问题
删除分为物理删除和逻辑删除,逻辑删除对数据库而言等同于更新,所以没任何问题。如果是物理删除,数据库中已经没有了这条数据,但是es中还存在。对于物理删除有一款插件可以做到同步,那就是go-mysql-elasticsearch(https://github.com/siddontang/go-mysql-elasticsearch),但是该插件尚处于开发阶段(2018年12月),稳定性不够。所以最佳实践方式还是增加一列来记录每条数据的删除状态。
logstash工作原理
logstash事件处理管道分为三个阶段:inputs → filters → outputs。Inputs开始事件,读取数据,filters修改他们,outputs将他们输出到其他地方。inputs和outputs支持编解码器,使您能够在输入或退出管道时对数据进行编码或解码,而无需使用单独的filter。
inputs将数据读入logstash,常见的数据来源有:文件、redis、数据库等。
filters是逻辑存储管道中的中间处理器。如果满足某些条件,您可以将过滤器与条件语句结合起来,在事件上执行操作。常见的过滤器包括:grok、mutate、drop等。
outputs是logstash管道的最后阶段。一个事件可以通过多个输出,但是一旦所有的输出处理完成,事件就完成了它的执行。常见的输出包括:elasticsearch、文件、graphite等
参考链接:https://www.elastic.co/guide/en/logstash/5.5/pipeline.html