pandas读取csv文件的一些运算操作
1. 读取csv 文件数据, pandas可以读取的文件的种类非常的多(CSV、SQL、XLS、JSON、HDF5), 支持复杂的IO操作;
使用read_csv 这个方法就可以对csv格式的文件进行读取和修改的操作;
import pandas as pd
import numpy as np
# 读取csv文件 输入我们文件的路径
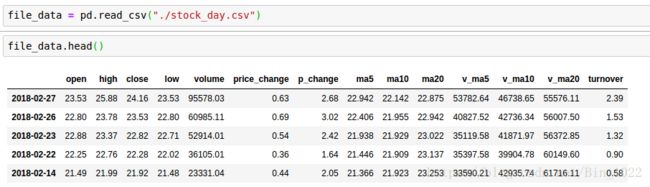
file_data = pd.read_csv('./stock_day.csv')
读取到的文件大致如下, 由于数据太多多以我们只展示部分数据进行演示:
2. 索引的操作
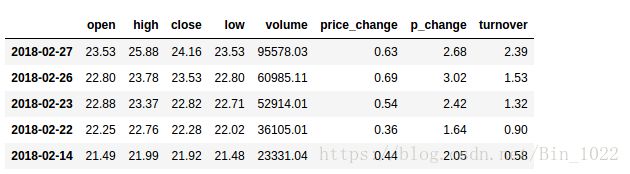
# axis 指定是0 轴还是 1轴 代表行列 使用drop删除我们不想展示的每一列的索引
file_data.drop(['ma5', 'ma10', 'ma20', 'v_ma5', 'v_ma10', 'v_ma20'], axis=1).head()
#通过数值直接切片的方式在pandas中无法使用, numpy可以
# 错误: file_data[:3, :3]
# 在pandas 中我们获取索引的方式 可以根据行列的索引名称来进行获取 或者 使用 loc , iloc 以及 ix 组# 合索引来进行获取
# 1. 根据行列的索引名称来进行获取 先根据<列索引>在根据<行索引>进行索引 不可以进行调换
file_data["open"]["2018-02-27"]
# 2. loc 也是根据行列索引的名称来获取索引 与1正好相反 他是 先行后列
file_data.loc["2018-02-27"]["open"]
# 3. iloc 可以根据行列索引的位置来获取位置 , 它支持切片的操作 先行后列
file_data.iloc[0, 0]
file_data.iloc[:3, :3]
# ix 混合索引 先行后列
file_data.ix[:3, :3]
3. 赋值操作
# 增加一个列索引 下面的值为缺失值
file_data["New_valiue"] = np.nan

处理缺失值的操作方法(删除缺失值):
# 删除缺失值 指定 他的 轴
file_data.dropna(axis=1)
4. 排序操作
# 根据行索引进行排序 由小到大 默认升序
file_data.sort_index().head()
# 添加 ascending=Flase 改为降序
file_data.sort_index(ascending=Flase).head()

根据某一个字段的数值进行排序 也可以传入字段的列表进行排序
# 根据某一个字段的数值进行排序 也可以传入字段的列表进行排序
file_data.sort_values("open")
file_data.sort_values(by="open", ascending=False).head()
Series排序
# Series 取字段索引进行排序
file_data["open"].sort_index().head()
# Series 取字段value进行排序
file_data["open"].sort_values().head()
5. 算数运算
# 对这个字段的所有数据进行统计+1的一个操作
file_data['open'].add(1)
如果想要得到每天的涨跌大小, 收盘价减去开盘价
# 1. 收盘价-开盘价
ret = file_data["close"] - file_data["open"]
# 2. 收盘价-开盘价
close = file_data["close"]
open = file_data["open"]
ret1 = close.sub(open)
6. 逻辑判断
# 去一个字段进行 ><
file_data["open"] <0.5
# 使用query查询
file_data.query(条件是一个字符串)
# 判断字段的值是否在什么数值之间 也可传递列表 返回的是bool 类型
file_data["open"].isin([0, 1]).head()
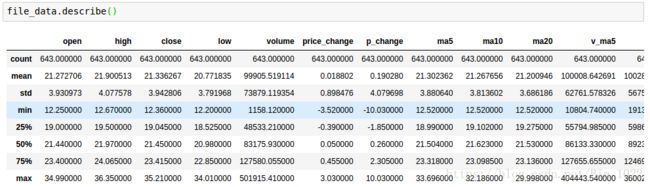
7. 统计运算 求最大值 最小值 标准差 平均值 通过 describe 这个函数进行统计
file_data.describe()
# 按列返回最小值, 返回对应的行索引 idxmax 最大值
file_data.min(axis=1).head()
8. 累积统计函数
累计求和
# cumsum 计算前n个数的和
# 先进行排序在进行累加
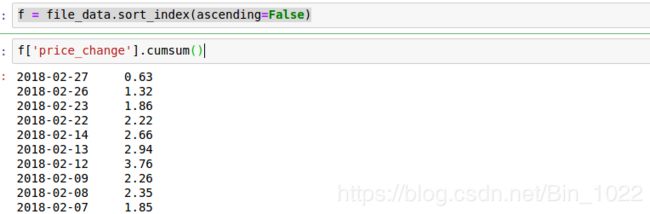
f = file_data.sort_index(ascending=False)
f['price_change'].cumsum()
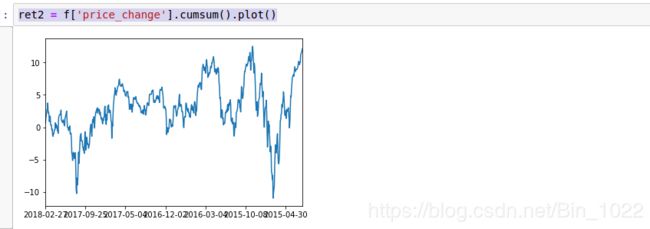
我们将这个连续求和的结果用图形的方式进行展示:
ret2 = f['price_change'].cumsum().plot()
9. 自定义函数(apply)
apply(func, axis=0)
比如可以可以定义一个函数, 使我们这个文件中的两个字段进行一个相减的一个运算
先找出我我们要进经运算的字段我们看一下:
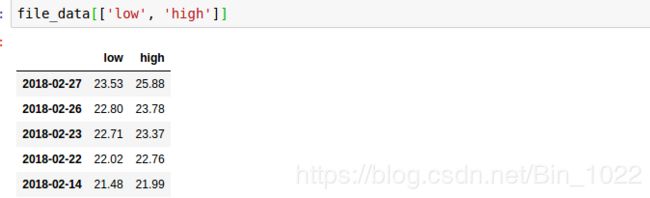
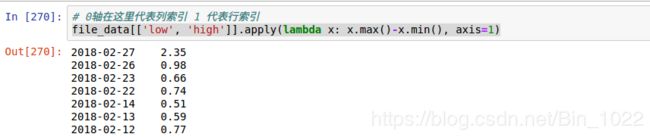
# 0轴在这里代表列索引 1 代表行索引
file_data[['low', 'high']].apply(lambda x: x.max()-x.min(), axis=1)