吴恩达机器学习总结:第十三 推荐系统(大纲摘要及课后作业)
为了更好的学习,充分复习自己学习的知识,总结课内重要知识点,每次完成作业后都会更博。
英文非官方笔记
总结
1.推荐系统-介绍
(1)ML系统的重要应用
a.许多科技公司发现推荐系统很关键(亚马逊,Ebay)
b.推荐系统性能提高能带来更多收入
(2)推荐系统不是一种技术,而是一种想法
(3)例子—预测电影评分
2.基于内容的推荐
(1)问题描述
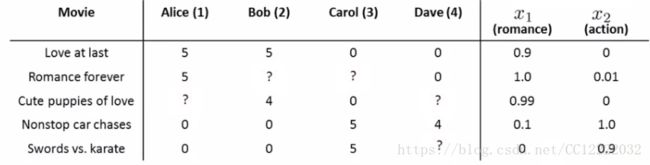
(2)定义
a.电影Love at Last可表示为:
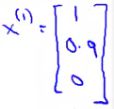
b.同理数据集为{x1, x2, x3, x4, x5}
c.用户j会给电影i的评分为:(θj)T xi = stars
3.如何学习
(1)代价函数

(2)正则化的代价函数
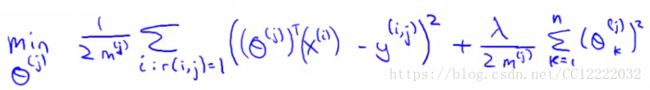
(3)对于每个用户,这个代价函数表示为:
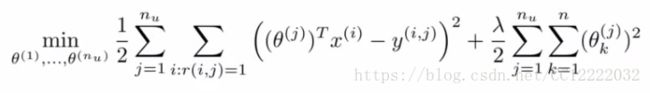
(4)梯度下降

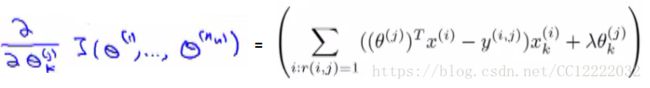
4.协作过滤 - 概述
(1)协作过滤算法有个很有趣的性质-特征学习(学习需要的特征)
(2)协作过滤算法
a.假如我们不知道电影评分系统的特征
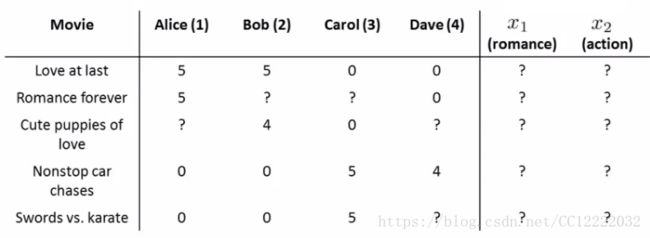
b.参数设置如下:
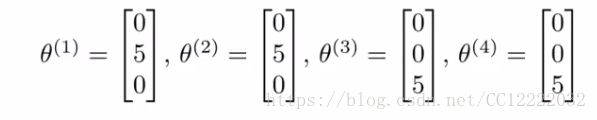
c.特征x1 向量应该为:(θ1)T x1 = 5,(θ2)T x1= 5,(θ3)T x1 = 0,(θ4)T x1 = 0
d.因而可以猜测:
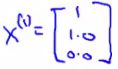
e.应用同样的方法,可以决定其他其他电影特征向量
(3)形式化协同过滤问题

(4)是如何与先前的推荐系统一起工作的
a.基于内容的推荐系统
b.现在,如果你有用户资料,那么你可以决定电影的特征
c.使你的算法收敛于一组合力的参数(这是协作过滤)
d.我们称之为协作过滤,因为在这个例子中,用户正在协作,帮助算法学习更好的功能,并帮助系统和其他用户
5.协作过滤算法
(1)如果有了电影特征,我们就能算出用户评分

(2)如果有了用户评分,我们就能算出电影特征
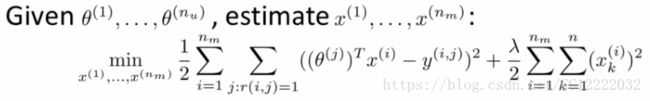
(3)你可以做的事情(随机初始化参数和不断来回前进后退)
(4)定义新的优化对象
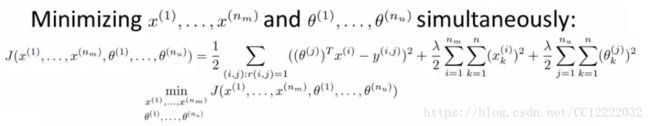
(5)如何理解上述优化对象
a.平方差项和两个独立的对象一样
b.正则项是两个独立项相加
(6)新定义函数的性质
a.给出X,就可以解出θ
b.给出θ,就可以解出X
(7)算法结构
a.初始化θ1, ..., θnu x1, ..., xnm 为小的随机项
b.最小化代价函数
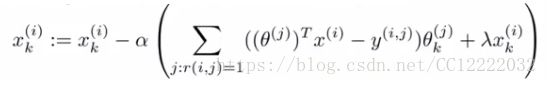

c.已经最小化了这些值,给定具有学习特征x的参数θ和电影(电影i)的用户(用户j),我们预测开始评级为(θj)T xi
6.矢量化:低秩矩阵分解
(1)我们将所有用户的所有评级都集中到一个矩阵Y中

(2)鉴于[Y]还有另外一种写出所有预测评分的方法
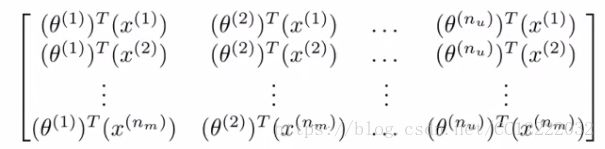
(3)定义矩阵X和Θ
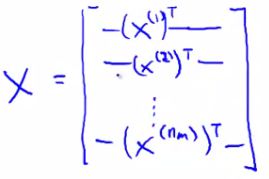
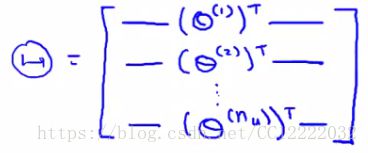
(4)通过计算X * ΘT来预测范围矩阵,这种方法交低秩矩阵分解
7.实现细节:均值标准化
(1)考虑到某个人没有给任何一部电影打分
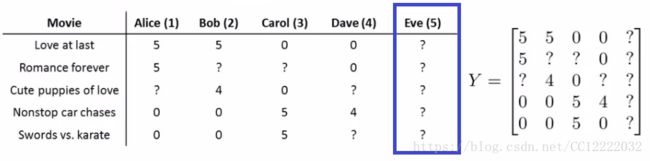
(2)优化对象

(3)计算电影的平均评分

(4)如果我们查看[Y]中的所有电影评级,我们可以减去平均评分
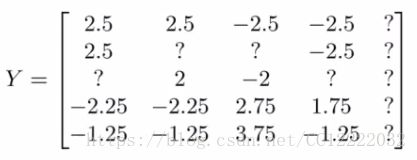
(5)预测(θj)T xi + μi
作业
1.载入并可视化
load ('ex8_movies.mat');
imagesc(Y);
ylabel('Movies');
xlabel('Users');2.协作滤波器代价函数
load ('ex8_movieParams.mat');
num_users = 4; num_movies = 5; num_features = 3;
X = X(1:num_movies, 1:num_features);
Theta = Theta(1:num_users, 1:num_features);
Y = Y(1:num_movies, 1:num_users);
R = R(1:num_movies, 1:num_users);
J = cofiCostFunc([X(:) ; Theta(:)], Y, R, num_users, num_movies, ...
num_features, 0);
%cofiCostFunc函数
X = reshape(params(1:num_movies*num_features), num_movies, num_features);
Theta = reshape(params(num_movies*num_features+1:end), ...
num_users, num_features);
J = 0;
X_grad = zeros(size(X));
Theta_grad = zeros(size(Theta));
J_temp = (X * Theta' - Y).^2;
J = sum(sum(J_temp(R == 1)))/2 + lambda/2 .* sum(sum(Theta.^2)) + lambda/2 .* sum(sum(X.^2));
X_grad = ((X * Theta' - Y) .* R) * Theta + lambda.*X;
Theta_grad = ((X * Theta' - Y) .* R)' * X + lambda.*Theta;
grad = [X_grad(:); Theta_grad(:)];
end3.协作滤波器梯度下降
checkCostFunction;
%checkCostfunction函数
if ~exist('lambda', 'var') || isempty(lambda)
lambda = 0;
end
X_t = rand(4, 3);
Theta_t = rand(5, 3);
Y = X_t * Theta_t';
Y(rand(size(Y)) > 0.5) = 0;
R = zeros(size(Y));
R(Y ~= 0) = 1;
X = randn(size(X_t));
Theta = randn(size(Theta_t));
num_users = size(Y, 2);
num_movies = size(Y, 1);
num_features = size(Theta_t, 2);
numgrad = computeNumericalGradient( ...
@(t) cofiCostFunc(t, Y, R, num_users, num_movies, ...
num_features, lambda), [X(:); Theta(:)]);
[cost, grad] = cofiCostFunc([X(:); Theta(:)], Y, R, num_users, ...
num_movies, num_features, lambda);
disp([numgrad grad]);
fprintf(['The above two columns you get should be very similar.\n' ...
'(Left-Your Numerical Gradient, Right-Analytical Gradient)\n\n']);
diff = norm(numgrad-grad)/norm(numgrad+grad);
fprintf(['If your cost function implementation is correct, then \n' ...
'the relative difference will be small (less than 1e-9). \n' ...
'\nRelative Difference: %g\n'], diff);
end4.协作滤波算法正则化
J = cofiCostFunc([X(:) ; Theta(:)], Y, R, num_users, num_movies, ...
num_features, 1.5);5.协作滤波算法梯度下降正则化
checkCostFunction(1.5);6.输入新用户的评分
movieList = loadMovieList();
my_ratings = zeros(1682, 1);
my_ratings(1) = 4;
my_ratings(98) = 2;
my_ratings(7) = 3;
my_ratings(12)= 5;
my_ratings(54) = 4;
my_ratings(64)= 5;
my_ratings(66)= 3;
my_ratings(69) = 5;
my_ratings(183) = 4;
my_ratings(226) = 5;
my_ratings(355)= 5;
for i = 1:length(my_ratings)
if my_ratings(i) > 0
fprintf('Rated %d for %s\n', my_ratings(i), ...
movieList{i});
end
end
%loadMovieList函数
fid = fopen('movie_ids.txt');
n = 1682; % Total number of movies
movieList = cell(n, 1);
for i = 1:n
% Read line
line = fgets(fid);
% Word Index (can ignore since it will be = i)
[idx, movieName] = strtok(line, ' ');
% Actual Word
movieList{i} = strtrim(movieName);
end
fclose(fid);
end
7.学习电影评分
load('ex8_movies.mat');
Y = [my_ratings Y];
R = [(my_ratings ~= 0) R];
[Ynorm, Ymean] = normalizeRatings(Y, R);
num_users = size(Y, 2);
num_movies = size(Y, 1);
num_features = 10;
X = randn(num_movies, num_features);
Theta = randn(num_users, num_features);
initial_parameters = [X(:); Theta(:)];
options = optimset('GradObj', 'on', 'MaxIter', 100);
lambda = 10;
theta = fmincg (@(t)(cofiCostFunc(t, Ynorm, R, num_users, num_movies, ...
num_features, lambda)), ...
initial_parameters, options);
X = reshape(theta(1:num_movies*num_features), num_movies, num_features);
Theta = reshape(theta(num_movies*num_features+1:end), ...
num_users, num_features);
%normalizeRatings函数
[m, n] = size(Y);
Ymean = zeros(m, 1);
Ynorm = zeros(size(Y));
for i = 1:m
idx = find(R(i, :) == 1);
Ymean(i) = mean(Y(i, idx));
Ynorm(i, idx) = Y(i, idx) - Ymean(i);
end
end
8.推荐
p = X * Theta';
my_predictions = p(:,1) + Ymean;
movieList = loadMovieList();
[r, ix] = sort(my_predictions, 'descend');
fprintf('\nTop recommendations for you:\n');
for i=1:10
j = ix(i);
fprintf('Predicting rating %.1f for movie %s\n', my_predictions(j), ...
movieList{j});
end
fprintf('\n\nOriginal ratings provided:\n');
for i = 1:length(my_ratings)
if my_ratings(i) > 0
fprintf('Rated %d for %s\n', my_ratings(i), ...
movieList{i});
end
end