爬虫实例(二)——中国大学排名爬虫
本文是官途爬取 2016 年中国大学排名的,要爬取的网址:
http://www.zuihaodaxue.cn/zuihaodaxuepaiming2016.html


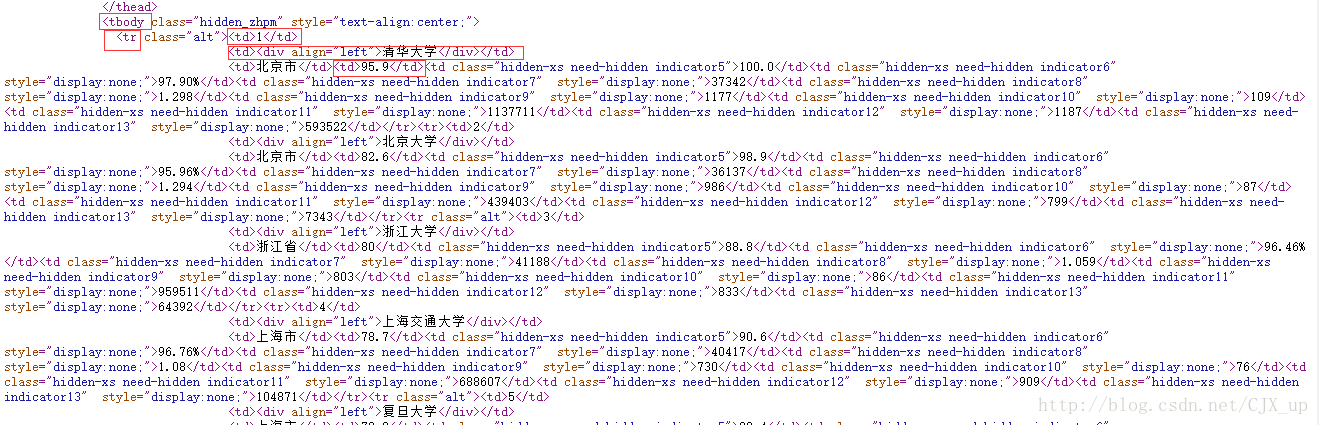
假如我们要爬取的信息是前 20 名大学的大学名称、排名及得分,查看源代码,如下图,可以发现排名的全部相关信息在标签 <tbody> 下的 <tr> 中,而具体的名称、排名、得分等信息则在标签 <td> 中。


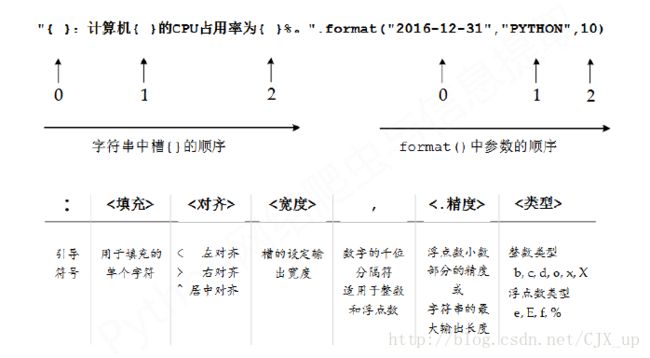
代码中打印信息时会用到 format() 函数,用法见下图:
输出中文时,可能会出现不对齐的问题,原因和解决方法如下:


完整代码:
# -*- coding: utf-8 -*-
""" Created on Sun Aug 20 23:59:48 2017 爬取中国大学2016年排名 @author: ChenJX """
import requests, bs4
from bs4 import BeautifulSoup
url = "http://www.zuihaodaxue.cn/zuihaodaxuepaiming2016.html"
schoolInfro = []
# 利用 requests 库爬取网页内容
def getHTMLText(url):
try:
r = requests.get(url)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
# 利用 BeautifulSoup 库解析提取爬取到的信息
def fillUnivList(html, infro):
soup = BeautifulSoup(html, "html.parser")
for tr in soup.find('tbody').children:
# 下面 if 语句保证了 'tr' 是标签而不是字符串
if isinstance(tr, bs4.element.Tag):
tds = tr.find_all('td')
# 注意添加信息的时候,由于有多个元素,因此要使用 list 的形式
infro.append([tds[0].string, tds[1].string, tds[3].string])
# 将需要的信息打印出来
def printUnivList(infro, num):
# tplt_1, tplt_2 与打印格式相关,使用两个不同的是为了对齐、美观
# chr(12288) 表示采用中文字符的空格填充
tplt_1 = "{0:^10}\t{1:{3}^9}\t{2:^6}"
tplt_2 = "{0:^10}\t{1:{3}^10}\t{2:^10}"
print(tplt_1.format("排名", "学校名称", "总分", chr(12288)))
for i in range(num):
u = infro[i]
print(tplt_2.format(u[0], u[1], u[2], chr(12288)))
def main():
html = getHTMLText(url)
fillUnivList(html, schoolInfro)
printUnivList(schoolInfro, 20)
main()结果如图:

【参考】北京理工大学网络公开课《Python网络爬虫与信息提取》
【注】本文图片均来自北京理工大学网络公开课《Python网络爬虫与信息提取》课件