基于深度学习的目标检测综述
最近在学习目标检测,发现这一块有很多内容要学,就先记录一下,不定时更新吧,看完哪篇论文就更一下。
一、综述
主要就是那几篇论文的演进,
RCNN系列:RCNN –> SSPNet –> Fast RCNN –> Faster RCNN –> Mask RCNN
其他:YOLO-> YOLO2、SSD
其他相关:DPM、Selective Search
对于目标检测来说,传统方法是DPM,后来出了基于深度学习的RCNN,然后根据SPPNet对其进行了改进出了Fast RCNN,再后来利用RPN提出了Faster RCNN(RBG大神确实厉害啊),去年何恺明又提出Mask RCNN。
除了这条主线,还有YOLO、YOLO2以及SSD。
当然还要一步步梳清这些脉络。
还有VOC比赛、各种VOC数据集、各项评价指标等。这个单独开一篇博客总结吧。
这篇就主要介绍目标检测算法。
| 算法 | 提出时间 | 作者 | MAP | 速度 | 其他 |
|---|---|---|---|---|---|
| DPM | 2010年 | Ross B. Girshick | |||
| RCNN | 2014年 | Ross B. Girshick | |||
| Fast RCNN | 2015年 | Ross B. Girshick | |||
| Faster RCNN | 2016年 | Kaiming He, Ross B. Girshick | |||
| MaskRCNN | 2017年 | Kaiming He, Ross B. Girshick | |||
| YOLO | 2016年 | Ross B. Girshick | |||
| YOLO2 | 2016年 | Joseph Redmon, Ali Farhadi | |||
| SSD | 2016年 | Wei Liu1, Dragomir Anguelov |
二、任务与难点
2.1 任务
主要是两方面,首先要对目标进行检测,框出位置,然后进行识别。主要是用回归和分类来做。
2.2 难点
1、图像中出现的目标数量不稳定
2、图像中的目标大小不一
3、图像中的目标种类多样
三、算法演进
一共两条大的主线,首先,在深度学习之前,目标检测上传统的方法是2010年提出的DPM,然后随着12年AlexNet在ImageNet上名声大噪后,目标检测方面也出了很多深度学习的算法。
从14年开始,RBG大神开始提出一系列的RCNN系列。
中间又出过YOLO、SSD等算法。
当然还有一些其他算法,比如OverFeat,SPPNET等。
下面一一介绍这些算法。
如果你想对目标检测有个初步了解,建议看一下这篇博客。
3.0 DPM
暂时先不做介绍,因为后面也不会用到,传统方法,虽然RBG也说DMP也是CNNs。
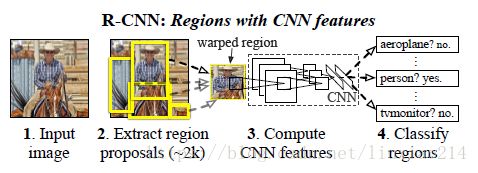
3.1 RCNN
14年,Ross Girshick(一作)和他的小伙伴们提出。
- 使用候选区域方法(’Selective Search’选择性搜索)提取物体可能存在的候选框。
- 然后使用CNN从每一个区域提取特征
- 对每一个类别都训练一个SVM进行二分类,然后使用SVM分类每一个区域。
- 对选出来的框,使用回归器修正位置。
3.2 SPPNet
15年,Kaiming He和他的小伙伴提出。
一共两个特点:
1.结合空间金字塔方法实现CNNs的对尺度输入。
一般CNN后接全连接层或者分类器,他们都需要固定的输入尺寸,因此不得不对输入数据进行crop或者warp,这些预处理会造成数据的丢失或几何的失真。SPP Net的第一个贡献就是将金字塔思想加入到CNN,实现了数据的多尺度输入。

2.只对原图提取一次卷积特征
在R-CNN中,每个候选框先resize到统一大小,然后分别作为CNN的输入,这样是很低效的。所以SPP Net根据这个缺点做了优化:只对原图进行一次卷积得到整张图的feature map,然后找到每个候选框zaifeature map上的映射patch,将此patch作为每个候选框的卷积特征输入到SPP layer和之后的层。节省了大量的计算时间,比R-CNN有一百倍左右的提速。

3.3 Fast RCNN
RCNN速度太慢了,即使用selective search等预处理步骤来提取潜在的bounding box作为输入,但RCNN仍会对所有region输入到CNN,进行特征提取时会有重复计算,Fast-RCNN正是为了解决这个问题诞生的。
15年,Ross Girshick独自提出Fast RCNN。主要采用了SPPNET的思想。
RBG大神提出了一个可以看做单层sppnet的网络层,叫做ROI Pooling,这个网络层可以把不同大小的输入映射到一个固定尺度的特征向量,对每个region都提取一个固定维度的特征表示,再通过正常的softmax进行类型识别。即不像RCNN把每个候选区域给深度网络提特征,而是整张图提一次特征,再把候选框映射到conv5上,而SPP只需要计算一次特征,剩下的只需要在conv5层上操作就可以了。

3.4 Faster RCNN
16年,Kaiming He(二作)和Ross Girshick(三作)合作,提出RCNN系列的第三版,Faster RCNN。
Fast RCNN虽然不存在对候选框进行特征提取的重复操作了,但仍然需要使用SR等算法提取候选框,那如何用一种更高效的方式提取候选框呢?
加入一个提取边缘的神经网络,用神经网络自己找候选框,即Region Proposal Network(RPN)。
具体是,将RPN放在最后一个卷积层的后面,然后对RPN直接训练得到候选区域。
Faster RCNN网络,共有四个损失函数;
• RPN calssification(anchor good.bad)
• RPN regression(anchor->propoasal)
• Fast R-CNN classification(over classes)
• Fast R-CNN regression(proposal ->box)
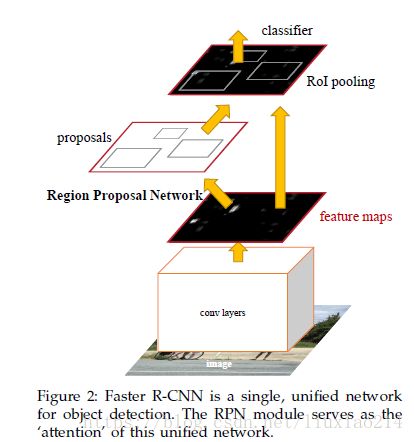
关于RPN的简介(对RPN还不太清楚)
- 在feature map上滑动窗口
- 建一个神经网络用于物体分类+框位置的回归
- 滑动窗口的位置提供了物体的大体位置信息
- 框的回归提供了框更精确的位置

3.5 YOLO
16年,Joseph Redmon(一作)和 Ross Girshick(三作)合作,对Fast RCNN的改进,提出YOLO。
YOLO提出了一个兼具准确性和速度性的简单的卷积神经网络,首次实现了实时物体检测。使用了回归的方法。

3.6 YOLO2与YOLO9000
16年,Joseph Redmon(一作)和Ali Farhadi(二作)合作,提出YOLO9000,即YOLO2。
使用一系列的方法对YOLO进行了改进,在保持原有速度的同时提升精度得到YOLO2。提出了一种目标分类与检测的联合训练方法,同时在COCO和ImageNet数据集中进行训练得到YOLO9000,实现9000多种物体的实时检测。
YOLO 2相比YOLO,提高了速度和准确率,基于darknet-19模型,除去完全连接层,用了边框聚类,两层组合,采用图像多分辨率的训练。
YOLO 9000可以利用无边框的数据和有边框的数据一起来实现9418类的监测。采用wordTree层次分类的办法。
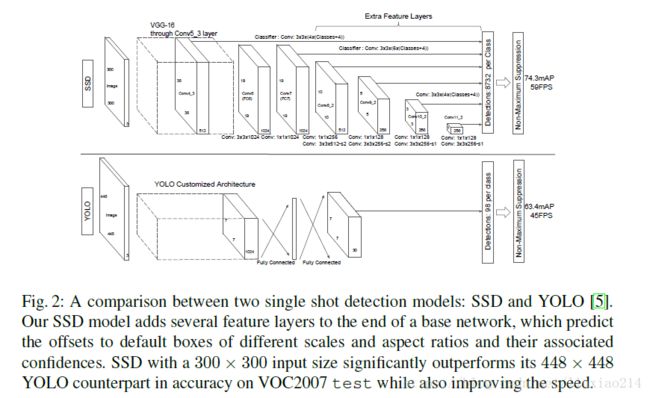
3.7 SSD
16年,Wei Liu(一作)和他的小伙伴提出SSD,是对YOLO的改进。
在YOLO的基础上使用多尺寸的卷积特征图,使得在结果和速度上都有提升。
3.8 Mask RCNN
17年,Kaiming He(一作)提出Mask RCNN。(Ross Girshick是四作)

三、总结
先放一张别人画的总结图。

后面自己也会再画一个,以后再放上来,也会再更新一下篇博客,更注重在算法角度写出每个算法的改进。
四、参考文献
4.1 参考论文
1、Sande K E A V D, Uijlings J R R, Gevers T, et al. Segmentation as selective search for object recognition[C]// International Conference on Computer Vision. IEEE Computer Society, 2011:1879-1886.
2、Girshick R, Iandola F, Darrell T, et al. Deformable part models are convolutional neural networks[C]// Computer Vision and Pattern Recognition. IEEE, 2015:437-446.
3、Girshick R, Donahue J, Darrell T, et al. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation[C]// IEEE Conference on Computer Vision and Pattern Recognition. IEEE Computer Society, 2014:580-587.
4、He K, Zhang X, Ren S, et al. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition[J]. IEEE Trans Pattern Anal Mach Intell, 2014, 37(9):1904-1916.
5、Girshick R. Fast R-CNN[J]. Computer Science, 2015.
6、Ren S, He K, Girshick R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[C]// International Conference on Neural Information Processing Systems. MIT Press, 2015:91-99.
7、He K, Gkioxari G, Dollár P, et al. Mask R-CNN[J]. 2017.
8、Redmon J, Divvala S, Girshick R, et al. You Only Look Once: Unified, Real-Time Object Detection[C]// Computer Vision and Pattern Recognition. IEEE, 2016:779-788.
9、Redmon J, Farhadi A. YOLO9000: Better, Faster, Stronger[J]. 2016:6517-6525.
10、Liu W, Anguelov D, Erhan D, et al. SSD: Single Shot MultiBox Detector[J]. 2015:21-37.
11、Felzenszwalb P F, Girshick R B, Mcallester D, et al. Object Detection with Discriminatively Trained Part-Based Models[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2010, 47(2):6-7.
4.2 其他参考链接
1、http://www.rossgirshick.info/
2、https://www.zhihu.com/question/35887527
3、https://www.cnblogs.com/skyfsm/p/6806246.html
4、https://blog.csdn.net/hjimce/article/details/50187029
5、https://yq.aliyun.com/articles/222583#
6、https://www.leiphone.com/news/201708/7pRPkwvzEG1jgimW.html7
7、https://zhuanlan.zhihu.com/p/25167153
8、https://blog.csdn.net/ikerpeng/article/details/54316814
9、https://blog.csdn.net/linolzhang/article/details/71774168