统计学习方法笔记1——感知机(perceptron)的Python实现
感知机(perceptron)是二分分类的线性分类模型,其输入为实例的特征向量,输出为实例的类别,取+1和-1二值,感知机对应于输入空间(特征空间)中将实例划分为正负两类的分离超平面,为此,导入基于误分类的损失函数,利用梯度下降法对损失函数进行极小化,求得感知机模型,感知机学习算法具有简单而易于实现的优点,分为原始形式和对偶形式,感知机预测是用学习得到的感知机模型对新的输入实例进行分类,感知机1957年由Rosenblatt提出,是神经网络与支持向量机的基础。
感知机学习算法分为原始形式和对偶形式的原因是对偶形式的感知机学习算法样本点的特征向量以内积的形式存在,如果事先计算好所有的内积,也就是Gram矩阵,就可以大大加快计算速度。
对偶的定义:通俗讲,就是从一个不同的角度去解答相似问题,但是问题的解是相通的,甚至是一样的。
原始形式:
算法推导:公式太多,看书就好了嘛~
算法步骤:
输入:训练数据集T={(x1,y1),(x2,y2),…,(xN,yN)},其中,xi ∈ X=Rn,yi ∈ Y={+1,-1},i=1,2,…,N,学习率 η (0< η <=1);
输出:w,b;感知机模型f(x)=sign(w ⋅ x+b).
1.选取初值w0,b0
2.在训练集中任意选取点(xi,yi)
3.如果yi(w⋅xi+b)<=0
w ← w+ η yixi
b ← b+ η yi
4.重复2,直到训练集中没有被误分类点
以上是感知机算法的原始形式,下面给出其的Python实现。
import numpy as np
import random
import matplotlib.pyplot as plt
def sign(v):
if v>=0:
return 1
else:
return -1
def perceptron(train_num,train_datas,lr):
w=[0,0]
b=0
for i in range(train_num):
x=random.choice(train_datas)
x1,x2,y=x
if(y*sign(w[0]*x1+w[1]*x2+b)<=0):
w[0]+=lr*y*x1
w[1]+=lr*y*x2
b+=lr*y
return w,b
def plot(train_datas,w,b):
plt.figure('perceptron')
x1=np.linspace(0,8,100)
x2=(-w[0]*x1-b)/w[1]
plt.plot(x1,x2,color='r',label='y1 data')
datas_len=len(train_datas)
for i in range(datas_len):
if(train_datas[i][2]==1):
plt.scatter(train_datas[i][0],train_datas[i][1],s=50)
else:
plt.scatter(train_datas[i][0],train_datas[i][1],marker='x',s=50)
plt.show()
if __name__=='__main__':
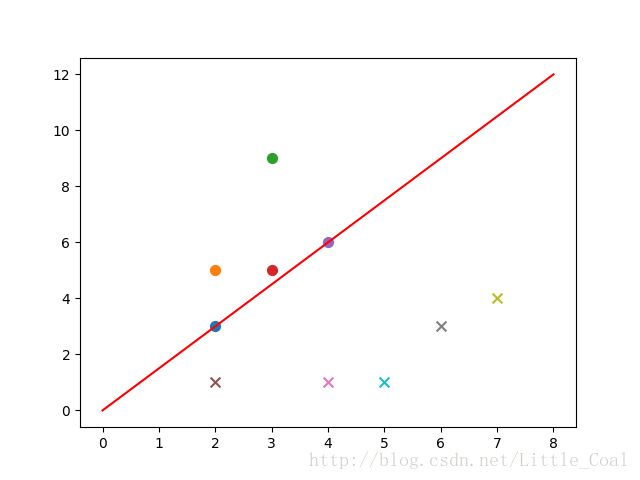
train_data1=[[2, 3, 1], [2, 5, 1], [3, 9, 1], [3, 5, 1],[4, 6, 1]]
train_data2=[[2, 1, -1], [4, 1, -1], [6, 3, -1], [7, 4, -1],[5, 1, -1]]
train_datas=train_data1+train_data2
w,b=perceptron(train_num=100,train_datas=train_datas,lr=0.01)
plot(train_datas,w,b)结果:

对偶形式:
算法推导:公式太多,看书就好了嘛~
算法步骤:
输入:线性可分的数据集T={(x1,y1),(x2,y2),…,(xN,yN)},其中,xi ∈ X=Rn,yi ∈ Y={+1,-1},i=1,2,…,N,学习率 η (0< η <=1);
输出: α ,b;感知机模型f(x)=sign( ∑ Nj=1 α iyixi⋅x+b).其中 α =( α 1, α 2,…, α N)T
1. α ← 0,b ← 0
2.在训练集中选取数据(xi,yi)
3.如果yi( ∑ Nj=1 α iyixi⋅x+b)<=0
α i ← α i+ η
b ← b+ η yi
4.重复2,直到训练集中没有被误分类点
以上是感知机算法的对偶形式,下面给出其的Python实现。
import numpy as np
import random
import matplotlib.pyplot as plt
def sign(v):
if v>=0:
return 1
else:
return -1
def perceptron_duiou(train_num,train_datas,lr):
w=0.0
b=0
datas_len=len(train_datas)
alpha=[0 for i in range(datas_len)]
train_array=np.array(train_datas)
gram=np.matmul(train_array[:,0:-1],train_array[:,0:-1].T)
for idx in xrange(train_num):
tmp=0
i=random.randint(0,datas_len-1)
yi=train_array[i,-1]
for j in range(datas_len):
tmp+=alpha[j]*train_array[j,-1]*gram[i,j]
tmp+=b
if(yi*tmp<=0):
alpha[i]=alpha[i]+lr
b+=lr*yi
for i in range(datas_len):
w+=alpha[i]*train_array[i,0:-1]*train_array[i,-1]
return w,b,alpha,gram
def plot(train_datas,w,b):
plt.figure('perceptron_duiou')
x1=np.linspace(0,8,100)
x2=(-w[0]*x1-b)/w[1]
plt.plot(x1,x2,color='r',label='y1 data')
datas_len=len(train_datas)
for i in range(datas_len):
if(train_datas[i][2]==1):
plt.scatter(train_datas[i][0],train_datas[i][1],s=50)
else:
plt.scatter(train_datas[i][0],train_datas[i][1],marker='x',s=50)
plt.show()
if __name__=='__main__':
train_data1=[[2, 3, 1], [2, 5, 1], [3, 9, 1], [3, 5, 1],[4, 6, 1]]
train_data2=[[2, 1, -1], [4, 1, -1], [6, 3, -1], [7, 4, -1],[5, 1, -1]]
train_datas=train_data1+train_data2
w,b,alpha,gram=perceptron_duiou(train_num=300,train_datas=train_datas,lr=0.1)
plot(train_datas,w,b)结果: