白铁时代 —— (监督学习)原理推导
来自李航《统计学习方法》
文章目录
- -1 指标
-
- 相似度
- 0 概论
- 1 优化类
-
- 1.1 朴素贝叶斯
- 1.2 k近邻 - kNN
- 1.3 线性判别分析
-
- 二分类LDA
- 多分类LDA
- 流程
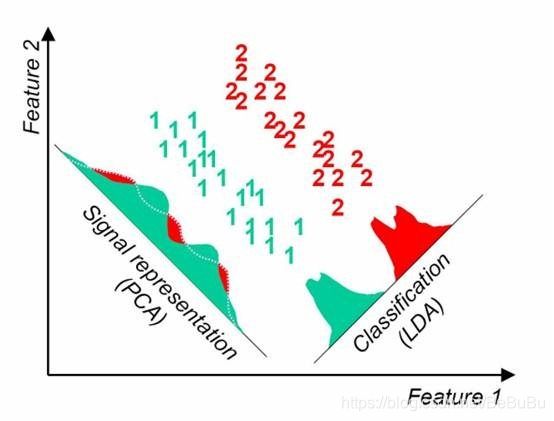
- LDA和PCA的区别和联系
- 1.4 逻辑回归模型 & 最大熵模型
-
- 逻辑回归
- 最大熵模型
- 最优化
- 1.5 感知机 & SVM
-
- 感知机
- SVM
-
- 线性可分SVM
- 线性不可分SVM
- 对偶优化问题 & 非线性SVM
- 序列最小优化算法 SMO
- 1.7 概率图模型
- EM算法
-
- EM算法的导出和流程
- 应用举例:高斯混合模型(GMM)参数求解
- `HMM` - 概率有向图生成模型
-
- 概率计算算法
- 学习算法
- 预测算法
- `CRF` - 概率无向图判别模型
-
- 概率无向图模型 PUGM
- 条件随机场模型(参数化)
- 概率计算模型
- 学习模型
- 预测模型
- 2 集成类
-
- 2.0 简介
-
- Bogging和Boosting
- 集成学习合并基分类器的方法
- 最常用的的基分类器为决策树
- 偏差和方差(过拟合和欠拟合)
- bagging是减少variance,而boosting是减少bias?
- 2.1 Bagging
-
- 决策树 if-then规则
-
- 特征选择
- 决策树生成
- 决策树修剪
- 分类回归树 CART
-
- CART生成
-
- 回归树生成
- 分类树生成
- CART剪枝
- 随机森林
-
- 流程
- 优缺点
- 和SVM比较
- 随机森林不会发生过拟合的原因
- 随机森林和GBDT
- 2.2 Boosting
-
- Adaboost
- Boost Tree & GBDT
-
- Boost Tree
- GBDT
-
- GBDT的梯度提升和梯度下降算法有什么联系:
- GBDT优点和局限性
- XGBoost
-
- 和GBDT的联系
- XGBoost和GBDT的区别
- LightGBM
- 3 采样
-
- 采样在ML中的作用
- 均匀分布随机数
- 常见采样方法
-
- 逆变换采样
- 拒绝采样
- 重要性采样
-
- 流程
- 对高斯分布进行采样
- 马尔可夫蒙特卡洛采样
- 贝叶斯网络采样
- 不均衡样本集的重采样
-
- 基于数据的方法
-
- 随机采样
- 过采样改进 — SMOTE算法
- 欠采样改进 — Informed Undersampling
- 泛化扩展
- 基于算法的方法
-1 指标
相似度
- L2归一化后欧拉距离的平方和cosine相似度等价
d 2 ( X , Y ) = ∑ i = 1 n ( X n − Y n ) 2 = ∑ i = 1 n X i 2 − 2 ∑ i = 1 n X i Y i + ∑ i = 1 n Y i 2 = 2 − 2 ∑ i = 1 n X i Y i = 2 ( 1 − ∑ i = 1 n X i Y i ) = 2 ( 1 − ∑ i = 1 n X i Y i 1 ⋅ 1 ) = 2 ( 1 − ∑ i = 1 n X i Y i ∑ i = 1 n X i 2 ⋅ ∑ i = 1 n X i 2 ) = 2 ( 1 − cos ( X , Y ) ) \begin{aligned} &d^{2}(X, Y)=\sum_{i=1}^{n}\left(X_{n}-Y_{n}\right)^{2}\\ &=\sum_{i=1}^{n} X_{i}^{2}-2 \sum_{i=1}^{n} X_{i} Y_{i}+\sum_{i=1}^{n} Y_{i}^{2}\\ &=2-2 \sum_{i=1}^{n} X_{i} Y_{i}\\ &=2\left(1-\sum_{i=1}^{n} X_{i} Y_{i}\right)\\ &=2\left(1-\frac{\sum_{i=1}^{n} X_{i} Y_{i}}{\sqrt{1} \cdot \sqrt{1}}\right)\\ &=2\left(1-\frac{\sum_{i=1}^{n} X_{i} Y_{i}}{\sqrt{\sum_{i=1}^{n} X_{i}^{2}} \cdot \sqrt{\sum_{i=1}^{n} X_{i}^{2}}}\right)\\ &=2(1-\cos (X, Y)) \end{aligned} d2(X,Y)=i=1∑n(Xn−Yn)2=i=1∑nXi2−2i=1∑nXiYi+i=1∑nYi2=2−2i=1∑nXiYi=2(1−i=1∑nXiYi)=2(1−1⋅1∑i=1nXiYi)=2(1−∑i=1nXi2⋅∑i=1nXi2∑i=1nXiYi)=2(1−cos(X,Y))
0 概论
0 模型: 函数族或者条件概率分布集合 / 策略:选出最优模型 / 算法:最优化
1 监督学习/无监督学习/强化学习:
- 监督学习学的是输入和输出(标签)的映射统计规律
- 非监督学习学的是数据中的统计规律和潜在结构,聚类/降维/概率估计
- 强化学习
2 概率模型/非概率模型:P(y|x);y=f(x)
3 线性模型/非线性模型:函数的线性
4 参数化模型/非参数模型:分类标准,问题是否可以进行数量固定的参数化?在统计学中: 参数模型通常假设总体服从某个分布,这个分布可以由一些参数确定,如正态分布由均值和标准差确定,在此基础上构建的模型称为参数模型; 非参数模型对于总体的分布不做任何假设或者说是数据分布假设自由,只知道其分布是存在的,所以就无法得到其分布的相关参数,只能通过非参数统计的方法进行推断。
5 在线学习/批量学习
6 贝叶斯估计/极大似然估计:
- 贝叶斯估计 > P(模型参数)P(数据|模型参数)/P(数据);
- 极大似然 > argmax(P(数据|参数)) > 参数;
- 转换:贝叶斯估计设先验概率P(模型参数)为均匀分布再取最大即可!
7 交叉验证: 0.3划分验证(Holdout 检验)/S-fold交叉验证/留1交叉验证(S=1)/自助法(有放回的随机抽样)
7.1 在自助法的采样过程中, 对 n 个样本进行 n 次有放回的采样, 当 n 趋于无穷大时, 最终有多少数据从未被选择过? 答: 36.8%. (1+1/n)^n ≈ e,则(1-1/n)^n≈1/e=0.368
8 生成模型和判别模型:P(X,Y)和P(Y|X)的差异,生成模型侧重P(X|Y),给出标签生成特征;判别型侧重P(Y|X),给出特征判断所属标签Y
9 分类问题
- 指标: Precision = TP/(TP+FP); Recall = TP/(TP+FN); 2/F1 = 1/Precision+1/Recall
10 标注问题:是分类问题的进阶,输入的是一个观测序列,序列之间不一定是相互独立的!而要预测进行新数据的标注!常用算法是一些概率图模型,HMM和CRF等!
11 回归问题:函数拟合问题
1 优化类
1.1 朴素贝叶斯
- 假设:数据独立同分布,且具有条件独立性
- 如何使用EM算法求解无监督的朴素贝叶斯模型??TODO … …

1.2 k近邻 - kNN
- 一种基本分类和回归的方法
- 算法流程(分类):① 对于测试集合某个样本,找到训练集中和其相邻(最相似)k个点 ② 使用这k个邻居的多数表决确定类别!
- 没有显示的学习,只是一种利用训练集对特征空间进行划分
- 模型:空间划分,三大要点:① 距离度量(特征向量的范数问题)② K值选取:k小学习误差小估计误差大,模型复杂易过拟合;k大学习误差大估计误差小,模型简单,忽略了很多有效信息。一般使用 交叉验证法确定 K这个超参数 ③ 分类决策规则:多数表决,即这K个邻居的0-1损失函数最小化
- 算法的数据结构优化:KD树 TODO…
1.3 线性判别分析
- 思路:进行数据降维,投影之后,类内距离尽可能小,类间距离尽可能大
二分类LDA
- 定义
arg max ⏟ w J ( w ) = ∥ w T μ 0 − w T μ 1 ∥ 2 2 w T Σ 0 w + w T Σ 1 w = w T ( μ 0 − μ 1 ) ( μ 0 − μ 1 ) T w w T ( Σ 0 + Σ 1 ) w \underbrace{\arg \max }_{w} J(w)=\frac{\left\|w^{T} \mu_{0}-w^{T} \mu_{1}\right\|_{2}^{2}}{w^{T} \Sigma_{0} w+w^{T} \Sigma_{1} w}= \\ \frac{w^{T}\left(\mu_{0}-\mu_{1}\right)\left(\mu_{0}-\mu_{1}\right)^{T} w}{w^{T}\left(\Sigma_{0}+\Sigma_{1}\right) w} w argmaxJ(w)=wTΣ0w+wTΣ1w∥∥wTμ0−wTμ1∥∥22=wT(Σ0+Σ1)wwT(μ0−μ1)(μ0−μ1)Tw- 类内散度矩阵
S w = Σ 0 + Σ 1 = ∑ x ∈ X 0 ( x − μ 0 ) ( x − μ 0 ) T + ∑ x ∈ X 1 ( x − μ 1 ) ( x − μ 1 ) T S_{w}=\Sigma_{0}+\Sigma_{1}=\\ \sum_{x \in X_{0}}\left(x-\mu_{0}\right)\left(x-\mu_{0}\right)^{T}+\sum_{x \in X_{1}}\left(x-\mu_{1}\right)\left(x-\mu_{1}\right)^{T} Sw=Σ0+Σ1=x∈X0∑(x−μ0)(x−μ0)T+x∈X1∑(x−μ1)(x−μ1)T - 类间散度矩阵
S b = ( μ 0 − μ 1 ) ( μ 0 − μ 1 ) T S_{b}=\left(\mu_{0}-\mu_{1}\right)\left(\mu_{0}-\mu_{1}\right)^{T} Sb=(μ0−μ1)(μ0−μ1)T
- 类内散度矩阵
- 求解
- 思路1,直接求导:
∂ J ( ω ) ∂ ω = ( ∂ ω ⊤ S B ω ∂ ω ω ⊤ S m ω − O ^ ω T S w ω ∂ ω ω ⊤ S B ω ) ( ω ⊤ S v p ω ) 2 = 0 ( ω T S w ω ) S B ω = ( ω T S B ω ) S w ω λ = J ( ω ) = ω T S B ω ω T S w ω S w − 1 S B ω = λ ω \frac{\partial J(\omega)}{\partial \omega}=\frac{\left(\frac{\partial \omega^{\top} S_{B} \omega}{\partial \omega} \omega^{\top} S_{m} \omega-\frac{\hat{O} \omega^{T} S_{w} \omega}{\partial \omega} \omega^{\top} S_{B} \omega\right)}{\left(\omega^{\top} S_{v_{p}} \omega\right)^{2}}=0 \\ \left(\omega^{\mathrm{T}} \boldsymbol{S}_{w} \boldsymbol{\omega}\right) \boldsymbol{S}_{B} \boldsymbol{\omega}=\left(\boldsymbol{\omega}^{\mathrm{T}} \boldsymbol{S}_{B} \boldsymbol{\omega}\right) \boldsymbol{S}_{\mathrm{w}} \boldsymbol{\omega} \\ \lambda=J(\omega)=\frac{\omega^{\mathrm{T}} S_{B} \omega}{\omega^{\mathrm{T}} S_{w} \omega} \\ \boldsymbol{S}_{w}^{-1} \boldsymbol{S}_{B} \boldsymbol{\omega}=\lambda \boldsymbol{\omega} ∂ω∂J(ω)=(ω⊤Svpω)2(∂ω∂ω⊤SBωω⊤Smω−∂ωO^ωTSwωω⊤SBω)=0(ωTSwω)SBω=(ωTSBω)Swωλ=J(ω)=ωTSwωωTSBωSw−1SBω=λω - J ( ω ) J(\omega) J(ω)就对应了矩阵 S w − 1 S B \boldsymbol{S}_{w}^{-1} \boldsymbol{S}_{B} Sw−1SB 最大的特征值,而投影方向就是 这个特征值对应的特征向量
- 思路2,广义瑞利熵:
λ min ≤ x H A x x H x ≤ λ max R ( A , x ) = x H A x x H B x x H B x = x ′ H ( B − 1 / 2 ) H B B − 1 / 2 x ′ = x ′ H B − 1 / 2 B B − 1 / 2 x ′ = x ′ H x ′ x H A x = x ′ H B − 1 / 2 A B − 1 / 2 x ′ R ( A , B , x ′ ) = x ′ H B − 1 / 2 A B − 1 / 2 x ′ x ′ H x ′ \lambda_{\min } \leq \frac{x^{H} A x}{x^{H} x} \leq \lambda_{\max } \\ R(A, x)=\frac{x^{H} A x}{x^{H} B x}\\ x^{H} B x=x^{\prime H}\left(B^{-1 / 2}\right)^{H} B B^{-1 / 2} x^{\prime}= \\ x^{\prime H} B^{-1 / 2} B B^{-1 / 2} x^{\prime}= x^{\prime H} x^{\prime} \\ x^{H} A x=x^{\prime H} B^{-1 / 2} A B^{-1 / 2} x^{\prime} \\ R\left(A, B, x^{\prime}\right)=\frac{x^{\prime H} B^{-1 / 2} A B^{-1 / 2} x^{\prime}}{x^{\prime H} x^{\prime}} λmin≤xHxxHAx≤λmaxR(A,x)=xHBxxHAxxHBx=x′H(B−1/2)HBB−1/2x′=x′HB−1/2BB−1/2x′=x′Hx′xHAx=x′HB−1/2AB−1/2x′R(A,B,x′)=x′Hx′x′HB−1/2AB−1/2x′ - 则 R ( A , B , x ′ ) R\left(A, B, x^{\prime}\right) R(A,B,x′) 的最大值为矩阵 B − 1 / 2 A B − 1 / 2 B^{-1 / 2} A B^{-1 / 2} B−1/2AB−1/2 的最大特征值,或者说矩阵 B − 1 A B^{-1} A B−1A 的最大特征值(两者是相似矩阵,相似矩阵的特征值相同)
- 思路1,直接求导:
多分类LDA
W T S b W W T S w W \frac{W^{T} S_{b} W}{W^{T} S_{w} W} WTSwWWTSbW
- 其中 S b = ∑ j = 1 k N j ( μ j − μ ) ( μ j − μ ) T S_{b}=\sum_{j=1}^{k} N_{j}\left(\mu_{j}-\mu\right)\left(\mu_{j}-\mu\right)^{T} Sb=∑j=1kNj(μj−μ)(μj−μ)T, μ \mu μ为所有样木均值向量(全局散度矩阵)
- 其中 S w = ∑ j = 1 k S w j = ∑ j = 1 k ∑ x ∈ X j ( x − μ j ) ( x − μ j ) T S_{w}=\sum_{j=1}^{k} S_{w j}=\sum_{j=1}^{k} \sum_{x \in X_{j}}\left(x-\mu_{j}\right)\left(x-\mu_{j}\right)^{T} Sw=∑j=1kSwj=∑j=1k∑x∈Xj(x−μj)(x−μj)T
- 其中 N j ( j = 1 , 2 … k ) N_{j}(j=1,2 \ldots k) Nj(j=1,2…k) 为第 j j j类样本的个数
- X j ( j = 1 , 2 … k ) X_{j}(j=1,2 \ldots k) Xj(j=1,2…k) 为第 j j j类样本的集合 , , , 而 μ j ( j = 1 , 2 … k ) \mu_{j}(j=1,2 \ldots k) μj(j=1,2…k) 为第 j j j类样本的均值向量,
- 直接优化走不通,转换为替代函数优化:
arg max W ⏟ J ( W ) = ∏ diag W T S b W ∏ diag W T S w W \underbrace{\arg \max _{W}} J(W)=\frac{\prod_{\text {diag }} W^{T} S_{b} W}{\prod_{\text {diag }} W^{T} S_{w} W} argWmaxJ(W)=∏diag WTSwW∏diag WTSbW - 其中 ∏ diag A \prod_{\text {diag }} A ∏diag A 为 A A A的主对角线元素乘积, W W W 为 n × d n \times d n×d 的矩阵
J ( W ) J(W) J(W) 优化过程如下:
J ( W ) = ∏ i = 1 d w i T S b w i ∏ i = 1 d w i T S w w i = ∏ i = 1 d w i T S b w i w i T S w w i J(W)=\frac{\prod_{i=1}^{d} w_{i}^{T} S_{b} w_{i}}{\prod_{i=1}^{d} w_{i}^{T} S_{w} w_{i}}=\prod_{i=1}^{d} \frac{w_{i}^{T} S_{b} w_{i}}{w_{i}^{T} S_{w} w_{i}} J(W)=∏i=1dwiTSwwi∏i=1dwiTSbwi=i=1∏dwiTSwwiwiTSbwi - 仔细观察上式最右边,这不就是广义瑞利商嘛! 最大值是矩阵 S w − 1 S b S_{w}^{-1} S_{b} Sw−1Sb 的是大特征值, 最大的 d d d 个值的乘积就是矩阵 S w − 1 S b S_{w}^{-1} S_{b} Sw−1Sb 的最大的d个特征值的乘积,此时对应的矩阵W 为这最大的d个特征值对应的特征向量张成的矩阵
流程
输入:数据集 D = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , … , ( ( x m , y m ) ) } D=\left\{\left(x_{1}, y_{1}\right),\left(x_{2}, y_{2}\right), \ldots,\left(\left(x_{m}, y_{m}\right)\right)\right\} D={(x1,y1),(x2,y2),…,((xm,ym))},其中任意样本 x i x_{i} xi 为n维向量, y i ∈ { C 1 , C 2 , … , C k } , y_{i} \in\left\{C_{1}, C_{2}, \ldots, C_{k}\right\}, yi∈{C1,C2,…,Ck}, 降维到的维度d。
输出:降维历的样本集 D D D
- 计算类内敬度矩阵 S w S_{w} Sw
- 计算类间散度矩阵 S b S_{b} Sb
- 计算矩阵 S w − 1 S b S_{w}^{-1} S_{b} Sw−1Sb
- 计算 S w − 1 S b S_{w}^{-1} S_{b} Sw−1Sb 的最大的d个特征值和对应的d个(≤ k)特征向量 ( w 1 , w 2 , … w d ) \left(w_{1}, w_{2}, \ldots w_{d}\right) (w1,w2,…wd),得到投影矩阵W W W W
- 对样本集中的每一个样本特征 x i x_{i} xi,转化为新的样本 z i = W T x i z_{i}=W^{T} x_{i} zi=WTxi
- 得到输出样本集 D ′ = { ( z 1 , y 1 ) , ( z 2 , y 2 ) , … , ( ( z m , y m ) ) } D^{\prime}=\left\{\left(z_{1}, y_{1}\right),\left(z_{2}, y_{2}\right), \ldots,\left(\left(z_{m}, y_{m}\right)\right)\right\} D′={(z1,y1),(z2,y2),…,((zm,ym))}
LDA和PCA的区别和联系
- 相同点
- 两者均可以对数据进行降维。
- 两者在降维时均使用了矩阵特征分解的思想。
- 两者都假设数据符合高斯分布。
- 不同点:
- LDA是有监督的降维方法,而PCA是无监督的降维方法
- LDA降维最多降到类别数k-1的维数(意思是降维和类别数相关),而PCA没有这个限制。
- LDA除了可以用于降维,还可以用于分类。
- LDA选择分类性能最好的投影方向,而PCA选择样本点投影具有最大方差的方向

1.4 逻辑回归模型 & 最大熵模型
都属于对数线性模型!
逻辑回归
- 对数线性分类模型!
- 逻辑分布属于指数分布族 TODO
- 学习算法:改进的迭代尺度法和拟牛顿法 TODO

最大熵模型
- 最大熵原理是一种思想,是统计学的一般性原理,认为在所有满足约束条件的概率模型中,熵最大的模型最优! 等可能 = 熵最大
- 特征函数 f ( x , y ) f(x, y) f(x,y) 关于经验分布 P ~ ( X , Y ) \tilde{P}(X, Y) P~(X,Y) 的期望值,用 E P ~ ( f ) E_{\tilde{P}}(f) EP~(f) 表示
- 特征函数 f ( x , y ) f(x, y) f(x,y) 关于模型 P ( Y ∣ X ) P(Y | X) P(Y∣X) 与经验分布 P ~ ( X ) \tilde{P}(X) P~(X) 的期望值,用 E P ( f ) E_{P}(f) EP(f) 表示


最优化
- 改进的迭代尺度法 Page104
- 拟牛顿法 Page107
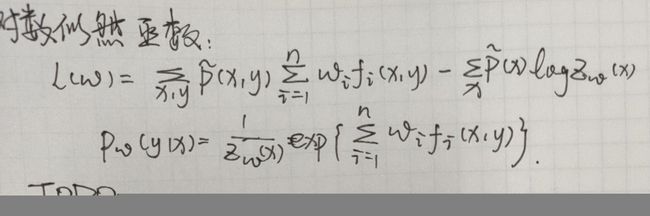
1.5 感知机 & SVM
感知机
二分类线性模型,旨在求出将训练数据划分为正负两类的分离超平面!
- 模型:f(x) = sign(wx+b)
- 学习前提:数据集的线性可分性
- 策略:基于误分类点的损失函数,定义为误分类点的个数是不可导不易优化!
-
- 基于此,选择误分类点到超平面的距离,设误分类点集合为M,定义损失函数为所有误分类点到超平面的距离和: − 1 ∥ w ∥ ∑ x i ∈ H y i ( w x i + b ) -\frac{1}{\|w\|} \sum_{x_{i} \in \mathcal{H}} y_{i}\left(w x_{i}+b\right) −∥w∥1∑xi∈Hyi(wxi+b),可以忽视掉||w||
- 学习,可以算法的原始形式和对偶形式

- 算法的收敛性,TODO
SVM
- 感知机算法是基于分类超平面算法的雏形,如SVM和NN都是对其的完善和改进,那究竟是完善了什么呢?感知机算法的解不是最优的,因为只要正确分类所有样本,就停止了迭代,但是不同的迭代步长可能会导致不同的解,而SVM就是提出“分类间隔最大化” 以优化分类超平面的选择!
- 按照理论的复杂程度,分为线性可分SVM(硬间隔),线性SVM(软间隔)和非线性SVM(核技巧),再加上一个有效的优化方法SMO 序列最小算法!
线性可分SVM
- 若数据线性可分,则将训练数据完全正确分开的最大间隔分类超平面存在且唯一!证明:有可行解且为凸优化问题,所以局部最小解即全局最小解。
线性不可分SVM
- 线性不可分意义是 某些Outiers不能满足函数间隔大于1的约束条件!
- 即软间隔最大化,引入松弛变量,使得函数间隔+松弛变量 >= 1
- 软间隔SVM的支持向量可以在边界上,边界之间或者边界之外!
- SVM的损失函数为合页损失函数hinge loss,因为优化问题等价于:
- ∑ i = 1 N max ( 0 , 1 − y i ( w x i + b ) ) + λ ∥ w ∥ 2 \sum_{i=1}^{N} \max \left(0,1-y_{i}\left(w x_{i}+b\right)\right)+\lambda\|w\|^{2} ∑i=1Nmax(0,1−yi(wxi+b))+λ∥w∥2
- 二分类问题的实际损失函数是01损失函数,而max(1-yf(x))是01损失函数的上界,而且01损失函数还不可导,所以最小化hinge损失函数是可以的:从下图可知,合页损失函数要求更高,要求间隔足够大,损失才为0。


对偶优化问题 & 非线性SVM
- 对偶问题优点:更易求解,对偶问题只需优化一个变量 α \alpha α且约束条件更简单;能更加自然地引入核函数,进而推广到非线性问题。


- 核技巧:① 使用变换将原空间数据映射到新空间 ② 使用线性方法求解
- 核技巧不显式求解变换函数,而是直接使用核函数 Φ ( x ) ⋅ Φ ( z ) = K ( x , z ) \Phi(x) \cdot \Phi(z)=K(x, z) Φ(x)⋅Φ(z)=K(x,z) 原因:映射函数通常是高维不好求,而且给定核函数其变换是不唯一的!
- 那什么样的函数才能叫核函数?通常是指正定核函数,什么希尔伯特空间内积空间什么的 … …
- 正定核的充要条件:K(x,z)是正定核函数 <=> 其Gram矩阵是半正定矩阵。证明 TODO …
- 常用核函数:多项式核函数(xz+1)^p + 高斯核函数
序列最小优化算法 SMO
- 基本思路:所有变量都满足KKT条件,则就找到了最优解!
- 思路:选择两个变量alpha, 一个是违反KKT条件最严重的,另一个自动确定,构成二次规划问题。
- 内容:二次规划问题求解的解析方法 + 选择变量的启发式方法
- 二次规划问题求解方法


- 启发式变量选择方法
-
- 为了节省计算时间,将E保存在一个列表!

- 为了节省计算时间,将E保存在一个列表!
- 更新参数,阈值 b b b和差值 E i E_i Ei

1.7 概率图模型
EM算法
- 一种用于含有隐变量的概率模型参数的 极大似然 (极大后验概率) 估计方法 expectation + maximization
- 理解EM算法 “三硬币模型”

EM算法的导出和流程
- 隐变量的存在,导致① 存在不能观测的变量(即没有数据) ② 对数中出现了和式,不便于求导!
- 所以EM本质就是使用前一次估计的参数,进行逐步近似极大化似然函数!
- EM通过不断求解下界逼近求解对数似然函数的极大化
- 前提,隐变量取值范围已知,观测数据集Y已知,提供上次估计的参数
- EM算法也可用于无监督学习,将输入变量缺失的输出变量看作不能观测的隐变量!
- EM算法的收敛性 TODO
- EM算法只能保证参数估计序列收敛到对数似然函数的稳定点,但是不能保证收敛到极大值点
- EM算法对参数初始化值敏感,建议多试几次!
- 流程:E:计算Q函数;M:极大化Q函数求当前迭代次数下的参数!
- EM的推广 - GEM TODO … …

应用举例:高斯混合模型(GMM)参数求解
- 高斯混合模型:使用加权的多个高斯函数和来拟合 某未知数据分布!
- 分为 ① 确定模型;② 明确隐变量;③ E步:确定Q函数;④ M步:极大化Q函数,迭代求解参数!
- ①②③

- ④ + 算法流程

HMM - 概率有向图生成模型
- 用于标注问题的统计学习模型
- 隐藏的马尔科夫链随机生成观测序列,生成模型
- 基本假设:①齐次马尔可夫假设(当前时刻状态只依赖上一个时刻的状态)②观测独立性假设(当前观测只依赖该时刻状态)
- HMM三要素 和 研究的三大问题:

概率计算算法
- 直接计算复杂度太高,O(TN^T), 是因为状态序列的选取是重叠的,直接计算没有考虑他们直接的动态联系,导致重复计算!
- 前后向计算方法,基于路径序列的路径结构 递推求解P(O| λ \lambda λ),引用了前时刻的结果!
- 前向后向区别就是一个从前往后迭代,一个从后往前迭代,同一种动态规划的不同遍历方向!

学习算法
- 按训练数据的不同:观测数据+状态>监督学习;观测数据>无监督学习
- 监督学习,直接使用频率替代概率!
- 无监督学习:Baum-Welch算法 (EM的变种)
- HMM实际上就是含有隐变量I的概率问题

预测算法
- 由观测和参数进行预测
- 两个思路,贪婪和动规,分别是近似算法和维特比算法,后者最优,前者局部最优!

CRF - 概率无向图判别模型
- 马尔可夫随机场,无向图表示的概率分布模型!
- 关注于线性链条件随机场,对数线性模型,(带正则化)极大似然估计
概率无向图模型 PUGM
- PUGM的三大性质:成对马尔可夫性 & 局部马尔可夫性 & 全局马尔科夫性
- PUGM易于分解因子,所以方便求解联合概率
- 团和最大团:团是内部所有点都互相直接相连!

条件随机场模型(参数化)
- 给定随机变量X条件下的马尔可夫随机场
- 定义:状态y1的概率只和条件变量X以及和y1相连的变量y2决定!
- 即: P ( Y v ∣ X , Y w , w ≠ v ) = P ( Y v ∣ X , Y w , w ∼ v ) P\left(Y_{v} | X, Y_{w}, w \neq v\right)=P\left(Y_{v} | X, Y_{w}, w \sim v\right) P(Yv∣X,Yw,w=v)=P(Yv∣X,Yw,w∼v)
- 对数线性模型

概率计算模型
- 前向-后向算法 TODO(是在矩阵形式基础上推的!)
学习模型
- 不含隐变量,所以不用EM算法求解,而是采用梯度下降法
- 改进尺度梯度下降法 + 拟牛顿法 TODO(也是采用矩阵形式)
预测模型
- 使用维特比算法求解最优路径问题
- TODO
2 集成类
2.0 简介
Bogging和Boosting
- 一个是集体投票思想,各个基分类器之间要去强依赖性,保持多样性(并行);一个是从错误中学习,保持基分类器之间的依赖性(串行)
- 从偏差和方差的角度来理解Bagging和Boosting:
- 基分类器又叫弱分类器,是偏差和方差的总和。偏差: 由于分类器的表达能力有限导致的系统性错误, 表现在训练误差不收 方差: 由于分类器对于样本分布过于敏感, 导致在训练样本数较少时, 产生过拟合!
- Boosting方法是通过逐步聚焦于基分类器分错的样本, 减小集成分类器的偏差
- Bagging方法则是采取分而治之的策略, 通过对训练样本多次采样, 并分别训练出多个不同模型, 然后做综合, 来减小集成分类器的方差,平滑决策边界:
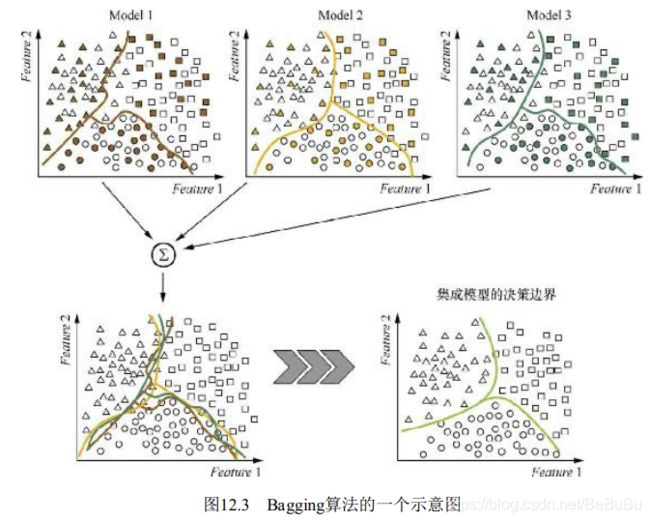
集成学习合并基分类器的方法
- Voting 或者 Stacking,前者即取众数,后者将上一个决策结果输入到下一个分类器,在取所有分类器的均值(或对所有分类器结果进一步综合决策,如再采用一个逻辑回归)
最常用的的基分类器为决策树
- ① 决策树可以较为方便地将样本的权重整合到训练过程中(特征选择生成子节点的时候,涉及到权重), 而不需要使用过采样的方法来调整样本权重
- ② 决策树的表达能力和泛化能力可以通过调节树的层数来做折中
- ③ 数据样本的扰动对于决策树的影响较大, 因此不同子样本集合生成的决策树基分类器随机性较大, 这样的 “不稳定学习器”(多样性) 更适合作为基分类器。 此外, 在决策树节点分裂的时候, 随机地选择一个特征子集, 从中找出最优分裂属性, 很好地引入了随机性!
- 同理神经网络模型也适合做基分类器,不稳定且超参多(调整神经元数量、 连接方式、 网络层数、 初始权值等方式),容易引入随机性!
- 线性分类器或者K-近邻 都是较为稳定的分类器, 本身方差就不大, 所以以它们为基分类器使用Bagging并不能在原有基分类器的基础上获得更好的表现, 甚至可能因为Bagging的采样, 而导致他们在训练中更难收敛, 从而增大了集成分类器的偏差
偏差和方差(过拟合和欠拟合)
- 偏差 指的是由所有采样得到的大小为m的训练数据集训练出的所有模型的输出平均值 和 真实模型输出 之间的偏差。 偏差通常是由于我们对学习算法做了错误的假设所导致的, 比如真实模型是某个二次函数, 但我们假设模型是一次函数。 由偏差带来的误差通常在训练误差上就能体现出来。
- 方差 指的是由所有采样得到的大小为m的训练数据集训练出的所有模型的输出的方差。方差通常是由于模型的复杂度相对于训练样本数m过高导致的, 比如一共有100个训练样本,而我们假设模型是阶数不大于200的多项式函数。 由方差通常体现在测试误差相对于训练误差的增量上。
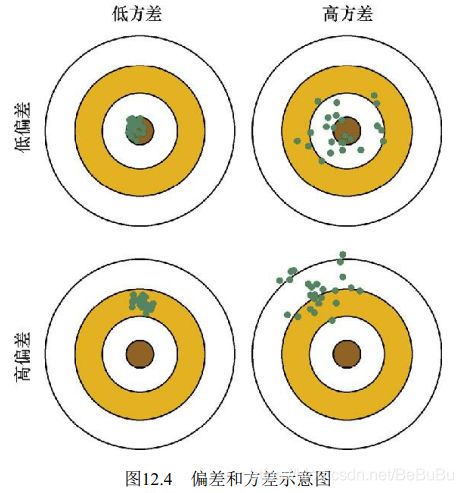
- 方差 — 偏差分解
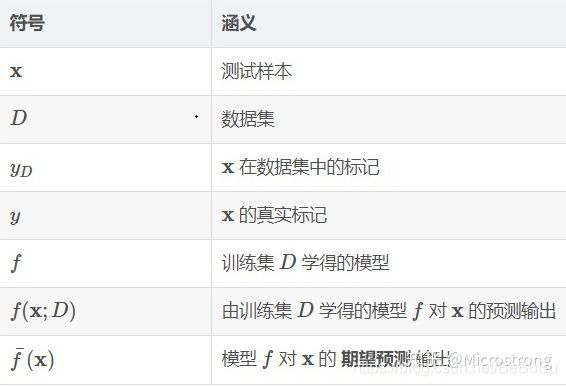
E ( f ; D ) = E D [ ( f ( x ; D ) − y D ) 2 ] = E D [ ( f ( x ; D ) − f ˉ ( x ) + f ˉ ( x ) − y D ) 2 ] = E D [ ( f ( x ; D ) − f ˉ ( x ) ) 2 ] + E D [ ( f ˉ ( x ) − y D ) 2 ] + E D [ 2 ( f ( x ; D ) − f ˉ ( x ) ) ( f ˉ ( x ) − y D ) ] = E D [ ( f ( x ; D ) − f ˉ ( x ) ) 2 ] + E D [ ( f ˉ ( x ) − y D ) 2 ] = E D [ ( f ( x ; D ) − f ˉ ( x ) ) 2 ] + E D [ ( f ˉ ( x ) − y + y − y D ) 2 ] = E D [ ( f ( x ; D ) − f ˉ ( x ) ) 2 ] + E D [ ( f ˉ ( x ) − y ) 2 ] + E D [ ( y − y D ) 2 ] + 2 E D [ ( f ˉ ( x ) − y ) ( y − y D ) ] P S : E D [ y D − y ] = 0 噪 声 期 望 为 0 = E D [ ( f ( x ; D ) − f ˉ ( x ) ) 2 ] + ( f ˉ ( x ) − y ) 2 + E D [ ( y D − y ) 2 ] \begin{aligned} E(f ; D)=& \mathbb{E}_{D}\left[\left(f(\boldsymbol{x} ; D)-y_{D}\right)^{2}\right] \\ =& \mathbb{E}_{D}\left[\left(f(\boldsymbol{x} ; D)-\bar{f}(\boldsymbol{x})+\bar{f}(\boldsymbol{x})-y_{D}\right)^{2}\right] \\ =& \mathbb{E}_{D}\left[(f(\boldsymbol{x} ; D)-\bar{f}(\boldsymbol{x}))^{2}\right]+\mathbb{E}_{D}\left[\left(\bar{f}(\boldsymbol{x})-y_{D}\right)^{2}\right] \\ &+\mathbb{E}_{D}\left[2(f(\boldsymbol{x} ; D)-\bar{f}(\boldsymbol{x}))\left(\bar{f}(\boldsymbol{x})-y_{D}\right)\right] \\ =& \mathbb{E}_{D}\left[(f(\boldsymbol{x} ; D)-\bar{f}(\boldsymbol{x}))^{2}\right]+\mathbb{E}_{D}\left[\left(\bar{f}(\boldsymbol{x})-y_{D}\right)^{2}\right] \\ =& \mathbb{E}_{D}\left[(f(\boldsymbol{x} ; D)-\bar{f}(\boldsymbol{x}))^{2}\right]+\mathbb{E}_{D}\left[\left(\bar{f}(\boldsymbol{x})-y+y-y_{D}\right)^{2}\right] \\ =& \mathbb{E}_{D}\left[(f(\boldsymbol{x} ; D)-\bar{f}(\boldsymbol{x}))^{2}\right]+\mathbb{E}_{D}\left[(\bar{f}(\boldsymbol{x})-y)^{2}\right]+\mathbb{E}_{D}\left[\left(y-y_{D}\right)^{2}\right] \\ &+2 \mathbb{E}_{D}\left[(\bar{f}(\boldsymbol{x})-y)\left(y-y_{D}\right)\right] PS: E_{D}\left[y_{D}-y\right]=0 噪声期望为0\\ =& \mathbb{E}_{D}\left[(f(\boldsymbol{x} ; D)-\bar{f}(\boldsymbol{x}))^{2}\right]+(\bar{f}(\boldsymbol{x})-y)^{2} + \mathbb{E}_{D}\left[(y_D-y)^{2}\right] \end{aligned} E(f;D)=======ED[(f(x;D)−yD)2]ED[(f(x;D)−fˉ(x)+fˉ(x)−yD)2]ED[(f(x;D)−fˉ(x))2]+ED[(fˉ(x)−yD)2]+ED[2(f(x;D)−fˉ(x))(fˉ(x)−yD)]ED[(f(x;D)−fˉ(x))2]+ED[(fˉ(x)−yD)2]ED[(f(x;D)−fˉ(x))2]+ED[(fˉ(x)−y+y−yD)2]ED[(f(x;D)−fˉ(x))2]+ED[(fˉ(x)−y)2]+ED[(y−yD)2]+2ED[(fˉ(x)−y)(y−yD)]PS:ED[yD−y]=0噪声期望为0ED[(f(x;D)−fˉ(x))2]+(fˉ(x)−y)2+ED[(yD−y)2]- E ( f ; D ) = bias 2 ( x ) + var ( x ) + ε 2 E(f ; D)=\operatorname{bias}^{2}(\boldsymbol{x})+\operatorname{var}(\boldsymbol{x})+\varepsilon^{2} E(f;D)=bias2(x)+var(x)+ε2
- 方差 — 偏差窘境:

- 需尽量选择正确的模型;还要慎重选择数据集的大;选择合适的模型复杂度
bagging是减少variance,而boosting是减少bias?
- Bagging:
- 模型相互独立时, E [ ∑ X i n ] = E [ X i ] E\left[\frac{\sum X_{i}}{n}\right]=E\left[X_{i}\right] E[n∑Xi]=E[Xi], Var ( ∑ X i n ) = Var ( X i ) n \operatorname{Var}\left(\frac{\sum X_{i}}{n}\right)=\frac{\operatorname{Var}\left(X_{i}\right)}{n} Var(n∑Xi)=nVar(Xi),而当各个模型相等时, Var ( ∑ X i n ) = Var ( X i ) \operatorname{Var}\left(\frac{\sum X_{i}}{n}\right)=\operatorname{Var}\left(X_{i}\right) Var(n∑Xi)=Var(Xi)
- 当bagging模型间有相关性, ∑ X i n 的方差为 ρ × σ 2 + ( 1 − ρ ) × σ 2 / n \frac{\sum X_{i}}{n} \text { 的方差为 } \rho × \sigma^{2}+(1-\rho) × \sigma^{2} / n n∑Xi 的方差为 ρ×σ2+(1−ρ)×σ2/n,相关系数 ρ \rho ρ
- bagging降低的是第二项,random forest是同时降低两项,详见ESL p588公式15.1)
- Boosting:
- 优化算法是前向分布算法(forward-stagewise),损失函数 L ( y , ∑ i a i f i ( x ) ) L\left(y, \sum_{i} a_{i} f_{i}(x)\right) L(y,∑iaifi(x)),就是在迭代的第 n n n步,求解新的子模型 f ( x ) f(x) f(x)及步长 a a a(或者叫组合系数),来最小化 L ( y , f n − 1 ( x ) + a f ( x ) ) L\left(y, f_{n-1}(x)+a f(x)\right) L(y,fn−1(x)+af(x))
- 因此boosting是在sequential地最小化损失函数,其bias自然逐步下降。但由于是采取这种sequential、adaptive的策略,但是各子模型之间是强相关的,于是子模型之和并不能显著降低variance
2.1 Bagging
- Bagging与Boosting的串行训练方式不同, Bagging方法在训练过程中, 各基分类器之间无强依赖, 可以进行并行训练,要保证基分类器的多样性!即 集体投票决策!
决策树 if-then规则
- 可以实现分类和回归,该书关注于分类
- 节点+有向边 = 有向树
- 树的每条路径的性质:互斥且完备
- 树的节点划分和条件概率息息相关 决策树表示一个条件概率
- 包含特征选择+决策树生成+决策树修建;决策树生成寻找局部最优 而 决策树修建寻找模型全局最优
特征选择
- 特征选择是决定用哪个特征来划分特征空间,即如何判定特征的分类能力?
- 信息增益和信息增益比
- 熵>条件熵>(最大熵模型)/信息增益>(互信息)/信息增益比
- 信息增益:得知特征X的信息而使得类Y的信息不确定性减少的程度
- 信息增益方法倾向于选择取值较多的特征,所以采用信息增益比 归一化了取值!
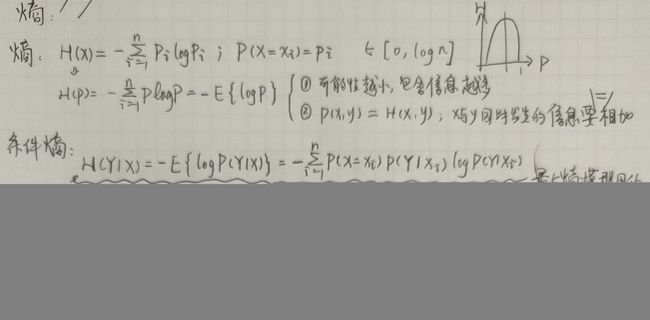
决策树生成
- ID3算法的生成(ID3算法只有生成过程,所以容易过拟合):采用信息增益递归生成树到增益很小或没有特征可选为止。即类似于极大似然估计方法。
- ID3只有针对离散值的分类!
- C4.5算法在ID3基础上将信息增益比作为分类指标;
- 此外C4.5还弥补了ID3中不能处理特征属性值连续的问题。但是,对连续属性值需要扫描排序,会使C4.5性能下降,具体操作是:将特征按值大小排序,遍历所有值之间的中点作为阈值,求最大!
- 此外C4.5对缺失值的处理有三种方法:① 丢弃 ② 赋上常见的值 ③ 按照样本集中各值出现的概率进行随机赋值。
决策树修剪
- 减少过拟合的可能性
- 决策树生成只考虑了通过提高信息增益对训练数据的更好拟合,而决策树剪枝则通过优化损失函数还考虑了如何减少模型复杂度,是正则化的极大似然估计。即生成局部模型,修建全局模型。
- 流程从叶节点向上回缩,当该节点为根节点的子树去掉后,损失函数小于不去掉的值,则剪去该子树,用叶节点替代位置。

分类回归树 CART
- 假设决策树是二叉树
CART生成
回归树生成

分类树生成
- 使用Gini Index选择最优特征
- 选择切分点和切分量的操作也是穷举取最优
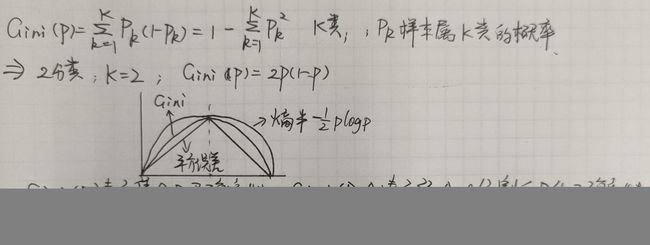
CART剪枝
- 剪枝的损失函数类似
- CART的剪枝流程和C4.5流程不一样,包括①形成子树序列②交叉验证选取最优子树
- CART剪枝的正则项系数 α \alpha α不用设!

随机森林
流程
- 从原始训练数据集中,应用bootstrap方法有放回地随机抽取k个新的自助样本集,并由此构建k棵分类回归树,每次未被抽到的样本组成了K个袋外数据(out-of-bag,BBB)
- 计算每个特征蕴含的信息量,特征选择一个最具有分类能力的特征进行节点分裂。
- 每棵树最大限度地生长, 不做任何剪裁
- 将生成的多棵树组成随机森林, 用随机森林对新的数据进行分类, 分类结果按树分类器投票多少而定。
优缺点
- 优点。
- 不必担心过度拟合;
- 适用于数据集中存在大量未知特征;
- 能够估计哪个特征在分类中更重要;
- 具有很好的抗噪声能力;
- 算法容易理解;
- 可以并行处理。
- 缺点。
- 对小量数据集和低维数据集的分类不一定可以得到很好的效果。
- 执行速度虽然比Boosting等快,但是比单个的决策树慢很多。
- 可能会出现一些差异度非常小的树,淹没了一些正确的决策。
- 由于树是随机生成的,结果不稳定(kpi值比较大)
和SVM比较
- 不需要调节过多的参数,因为随机森林只需要调节树的数量,而且树的数量一般是越多越好,而其他机器学习算法,比如SVM,有非常多超参数需要调整,如选择最合适的核函数,正则惩罚等。
- 分类较为简单直接。传统多类分类问题的执行一般是one-vs-all,因此我们还是需要为每个类训练一个支持向量机。相反,决策树与随机深林则可以毫无压力解决多类问题。
- 容易入手实践。随机森林在训练模型上要更为简单。容易可以得到一个又好且具鲁棒性的模型。随机森林模型的复杂度与训练样本和树成正比。支持向量机则需要我们在调参方面做些工作,除此之外,计算成本会随着类增加呈线性增长。
- 小数据上SVM优异,而随机森林对数据需求较大。就经验来说,我更愿意认为支持向量机在存在较少极值的小数据集上具有优势。随机森林则需要更多数据但一般可以得到非常好的且具有鲁棒性的模型。
随机森林不会发生过拟合的原因
- 采样与完全分裂
- ① 两个随机采样的过程,random forest对输入的数据 需要 行和列的采样
- 行采样,采用有放回的方式,也就是在采样得到的样本集合中,可能有重复的样本,使得在训练的时候,每一棵树的输入样本都不是全部的样本,使得相对不容易出现over-fitting
- 列采样,从M 个feature中,选择m个(m << M)
- ② 对采样之后的数据使用完全分裂的方式建立出决策树,这样决策树的某一个叶子节点要么是无法继续分裂的,要么里面的所有样本的都是指向的同一 个分类。
- 一般很多的决策树算法都一个重要的步骤 - 剪枝,但是这里不这样干,由于之前的两个随机采样的过程保证了随机性,所以就算不剪枝,也不会出现over-fitting
随机森林和GBDT
- 随机森林:决策树+bagging=随机森林
- 梯度提升树:决策树+Boosting=GBDT
- 两者区别在于bagging boosting之间的区别
2.2 Boosting
- 强可学习和弱可学习的概念:都要在多项式范围内可学习的,且前者正确率高,而后者只比随机猜测好!两者在PAC学习框架下是充要条件!
- Boosting方法训练基分类器时采用串行的方式, 各个基分类器之间有依赖。
- 它的基本思路是将基分类器层层叠加, 每一层在训练的时候, 对前一层基分类器分错的样本, 给予更高的权重。 测试时, 根据各层分类器的结果的加权得到最终结果。即 Learning from your mistakes!
Adaboost
- Adaboost是 模型为
加法模型,损失函数是指数函数,学习算法为前向分布算法的二分类学习方法 - 前向分步算法思想:学习的是加法模型,就可以一次只学习一个基函数及系数,逐步逼近优化目标!
- Adaboost是前向分步算法的特例,模型是加法模型,损失函数是指数函数
- Adaboost的训练误差上界 TODO …
- 大多数Boost方法都是改变训练数据的概率分布(权值分布),针对不同的数据分布调用不同的弱学习方法!
- 回答Adaboost两个问题:
- ①Adaboost是如何改变数据的权值和概率分布?即: ω m i \omega_{m_{i}} ωmi,提高前一轮错误分类的样本权值,降低正确的
- ②Adaboost是如何组织多个弱分类器的?即: α \alpha α,加大分类误差小的分类器权值,减少分类误差大的分类器权值!
- Adaboost在计算机视觉中的应用,
Viola-Jones人脸检测算法

Boost Tree & GBDT
Boost Tree
- 提升方法:加法模型 + 前向分步算法
- 提升树:提升方法 + 决策树
- 平方损失(回归问题)或指数损失(分类问题)函数或一般损失函数(其他决策问题)
- 对于二类分类问题,将Adaboost中的基本分类器G(x)改成决策树就行了
- 针对回归问题:损失函数采用平方误差损失函数!
- 回归问题实际上就是当前的决策时拟合上个结果的残差!
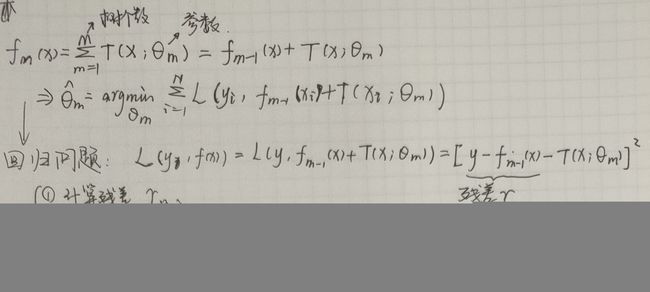
GBDT
- 梯度提升:对提升树在损失函数的泛化,使之不必局限于平方和指数损失函数
- 基本思想是根据当前模型损失函数的负梯度信息来训练新加入的弱分类器, 然后将训练好的弱分类器以累加的形式结合到现有模型中
- 梯度提升是最速下降法的近似方法
- 将基本分类或回归器视作一个变量,对整个的组合加法模型进行梯度下降。
- 即加法模型在函数空间的最速梯度下降法!
- 那这个函数空间的负梯度和最优的步长 C m C_m Cm怎么计算呢?是不是在XGBoost里面有描述?TODO… …
- 流程:

GBDT的梯度提升和梯度下降算法有什么联系:
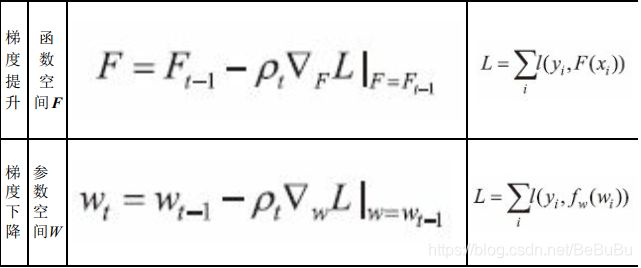
GBDT优点和局限性
- 优点
- 预测速度快, 树与树之间可并行化计算
- 在分布稠密的数据集上, 泛化能力和表达能力都很好, 这使得GBDT在Kaggle的众多竞赛中, 经常名列榜首
- 采用决策树作为弱分类器使得GBDT模型具有较好的解释性和鲁棒性, 能够自动发现特征间的高阶关系, 并且也不需要对数据进行特殊的预处理如归一化等
- 局限性
- GBDT在高维稀疏的数据集上, 表现不如支持向量机或者神经网络
- GBDT在处理文本分类特征问题上, 相对其他模型的优势不如它在处理数值特征时明显
- 训练过程需要串行训练, 只能在决策树内部采用一些局部并行的手段提高训练速度
XGBoost
和GBDT的联系
- XGBoost是陈天奇等人开发的一个开源机器学习项目, 高效地实现了GBDT算法并进行了算法和工程上的许多改进, 被广泛应用在Kaggle竞赛及其他许多机器学习竞赛中并取得了不错的成绩。 我们在使用XGBoost平台的时候, 也需要熟悉XGBoost平台的内部实现和原理, 这样才能够更好地进行模型调参并针对特定业务场景进行模型改进
XGBoost和GBDT的区别
- 加入正则项
- 原始的GBDT算法基于经验损失函数的负梯度来构造新的决策树, 只是在决策树构建完成后再进行剪枝,而XGBoost在决策树构建阶段就加入了正则项, 即:
L t = ∑ i l ( y i , F t − 1 ( x i ) + f t ( x i ) ) + Ω ( f t ) L_{t}=\sum_{i} l\left(y_{i}, F_{t-1}\left(x_{i}\right)+f_{t}\left(x_{i}\right)\right)+\Omega\left(f_{t}\right) Lt=i∑l(yi,Ft−1(xi)+ft(xi))+Ω(ft) - 其中: F t − 1 ( x i ) F_{t-1}\left(x_{i}\right) Ft−1(xi) 表示现有的t-1棵树最优解。关于树结构的正则项定义为:
Ω ( f t ) = γ T + 1 2 λ ∑ j = 1 T w j 2 \Omega\left(f_{t}\right)=\gamma T+\frac{1}{2} \lambda \sum_{j=1}^{T} w_{j}^{2} Ω(ft)=γT+21λj=1∑Twj2 - 其中 T T T为叶子节点个数, w j w_j wj表示第 j j j个叶子节点预测值
- 原始的GBDT算法基于经验损失函数的负梯度来构造新的决策树, 只是在决策树构建完成后再进行剪枝,而XGBoost在决策树构建阶段就加入了正则项, 即:
- 引入二阶导数
- 损失函数在 F t − 1 F_{t-1} Ft−1处二阶泰勒展开:
L t ≈ L ~ t = ∑ j = 1 T [ G j w j + 1 2 ( H j + λ ) w j 2 ] + γ T G j = ∑ i ∈ I j ∇ F i − 1 l ( y i , F t − 1 ( x i ) ) H j = ∑ j ∈ I j ∇ F l − 1 2 l ( y i , F t − 1 ( x i ) ) L_{t} \approx \tilde{L}_{t}=\sum_{j=1}^{T}\left[G_{j} w_{j}+\frac{1}{2}\left(H_{j}+\lambda\right) w_{j}^{2}\right]+\gamma T \\ G_{j}=\sum_{i \in I_{j}} \nabla_{F_{i-1}} l\left(y_{i}, F_{t-1}\left(x_{i}\right)\right) \\ H_{j}=\sum_{j \in I_{j}} \nabla_{F_{l-1}}^{2} l\left(y_{i}, F_{t-1}\left(x_{i}\right)\right) Lt≈L~t=j=1∑T[Gjwj+21(Hj+λ)wj2]+γTGj=i∈Ij∑∇Fi−1l(yi,Ft−1(xi))Hj=j∈Ij∑∇Fl−12l(yi,Ft−1(xi)) - I j I_{j} Ij 表示所有属于叶子节点的样本的索引的结合
- 令损失函数对 w j w_j wj导数为0,计算得到各个叶节点上的预测值:
w j ∗ = − G j H j + λ w_{j}^{*}=-\frac{G_{j}}{H_{j}+\lambda} wj∗=−Hj+λGj
- 损失函数在 F t − 1 F_{t-1} Ft−1处二阶泰勒展开:
- 最优树结构搜索策略
- 从所有的树结构中寻找最优的树结构是一个NP-hard问题, 因此在实际中往往采用贪心法来构建出一个次优的树结构
- 基本思想是从根节点开始, 每次对一个叶子节点进行分裂, 针对每一种可能的分裂, 根据特定的准则选取最优的分裂
- IC3算法采用信息增益, C4.5算法为了克服信息增益中容易偏向取值较多的特征而采用信息增益比, CART算法使用基尼指数和平方误差,XGBoost也有特定的准则来选取最优分裂:
- 通过将预测值代入到损失函数中可求得损失函数的最小值:
L ~ t ∗ = − 1 2 ∑ j = 1 T G j 2 H j + λ + γ T \tilde{L}_{t}^{*}=-\frac{1}{2} \sum_{j=1}^{T} \frac{G_{j}^{2}}{H_{j}+\lambda}+\gamma T L~t∗=−21j=1∑THj+λGj2+γT - 容易计算出分裂前后损失函数的差值为:
Gain = G L 2 H I . + λ + G R 2 H R + λ − ( G L + G R ) 2 H I + H R + λ − γ \operatorname{Gain}=\frac{G_{L}^{2}}{H_{I .}+\lambda}+\frac{G_{R}^{2}}{H_{R}+\lambda}-\frac{\left(G_{L}+G_{R}\right)^{2}}{H_{I}+H_{R}+\lambda}-\gamma Gain=HI.+λGL2+HR+λGR2−HI+HR+λ(GL+GR)2−γ - XGBoost采用最大化这个差值作为准则来进行决策树的构建, 通过遍历所有特征的所有取值, 寻找使得损失函数前后相差最大时对应的分裂方式。 γ \gamma γ起到一定预剪枝的作用!、
- 通过将预测值代入到损失函数中可求得损失函数的最小值:
- 其他优化:
- GBDT是机器学习算法, XGBoost是该算法的工程实现。
- 在使用CART作为基分类器时, XGBoost显式地加入了正则项来控制模型的复杂度, 有利于防止过拟合, 从而提高模型的泛化能力
- GBDT在模型训练时只使用了代价函数的一阶导数信息, XGBoost对代价函数进行二阶泰勒展开, 可以同时使用一阶和二阶导数。
- 传统的GBDT采用CART作为基分类器, XGBoost支持多种类型的基分类器, 比如线性分类器。
- 传统的GBDT在每轮迭代时使用全部的数据, XGBoost则采用了与随机森林相似的策略, 支持对数据进行采样。
- 传统的GBDT没有设计对缺失值进行处理, XGBoost能够自动学习出缺失值的处理策略
LightGBM
- Gradient-based One-Side Sampling (GOSS) 和Exclusive Feature Bundling (EFB)
- 参考 — 链接
3 采样
- 采样, 是从特定的概率分布中抽取相应样本点的过程
- 采样可以将复杂的分布简化为离散的样本点
- 重采样对样本集进行调整以更好地适应后期的模型学习,可以用于随机模拟以进行复杂模型的近似求解或推理
- 采样在数据可视化方面也有很多应用, 可以帮助人们快速、 直观地了解数据的结构和特性
采样在ML中的作用
- 采样本质上是对随机现象的模拟, 根据给定的概率分布, 来模拟产生一个对应的随机事件
- 采样得到的样本集也可以看作是一种非参数模型, 即用较少量的样本点(经验分布) 来近似总体分布(如设定训练集), 并刻画总体分布中的不确定性。 从这个角度来说, 采样其实也是一种信息降维, 可以起到简化问题的作用
- 重采样充分利用已有数据集, 可挖掘更多信息, 如自助法和刀切法, 通过对样本多次重采样来估计统计量的偏差、 方差:
- 样本的刀切法估计量是指将样本去除每个元素后重新计算估计量,再将这些估计量取平均值
- 样本自助法估计是一种从给定训练集中有放回的均匀抽样
- 重采样技术可以在保持特定的信息下(目标信息不丢失) , 有意识地改变样本的分布, 以更适应后续的模型训练和学习, 例如利用重采样来处理分类模型的训练样本不均衡问题
- 可以采用采样方法进行随机模拟,对这些复杂模型进行近似求解或推理。这一般会转化为某些函数在特定分布下的积分或期望, 或者是求某些随机变量或参数在给定数据下的后验分布等
均匀分布随机数
- 计算机程序都是确定的,只能说是伪随机数
- 可采用线性同余法(Linear Congruential Generator) 来生成离散均匀分布伪随机数, 计算公式为:
x t + 1 ≡ ( a ∙ x t + c ) m o d ( m ) x_{t+1} \equiv (a \bullet x_{t}+c)\bmod (m) xt+1≡(a∙xt+c)mod(m) - 根据当前生成的随机数 x t x_t xt来进行适当变换, 进而产生下一次的随机数 x t + 1 x_{t+1} xt+1, x 0 x_0 x0称为随机数种子,得到区间[0,m-1]上的随机整数
- 最多只能产生m个不同的随机数, 实际上对于特定的种子, 很多数无法取到, 循环周期基本达不到m
- , 循环周期基本达不到m。 如果进行多次操作, 得到的随机数序列会进入循环周期。 因此, 一个好的线性同余随机数生成器, 要让其循环周期尽可能接近m, 这就需要精心选择合适的乘法因子a和模数m,需要代数和群理论:
- (1)c与m互素(2)对于整除m的每个素数p, 2 b = a − 1 2^b=a-1 2b=a−1是 p p p的倍数(3)如果m是4的倍数,则b也是4的倍数。
{ m = 2 31 − 1 a = 1103515245 c = 12345 \left\{\begin{array}{l} m=2^{31}-1 \\ a=1103515245 \\ c=12345 \end{array}\right. ⎩⎨⎧m=231−1a=1103515245c=12345 - 为什么线性同余发生器得到的序列可以近似为均匀分布(伪随机数) ?
常见采样方法
- 对于一些简单的分布, 可以直接用均匀采样的一些扩展方法来产生样本点, 比如有限离散分布可以用轮盘赌算法来采样
- 很多分布一般不好直接进行采样, 可以考虑函数变换法 > 如果变换关系 φ ( ⋅ ) φ(·) φ(⋅)是x的累积分布函数的话, 则得到所谓的逆变换采样(Inverse Transform Sampling)
逆变换采样
- 从均匀分布U(0,1)产生一个随机数 u i u_{i} ui
- 计算 x i = Φ − 1 ( u i ) , x_{i}=\Phi^{-1}\left(u_{i}\right), xi=Φ−1(ui), 其中 Φ − 1 ( ∙ ) \Phi^{-1}(\bullet) Φ−1(∙) 是累积分布函数的逆函数

- 如果待采样的目标分布的累积分布函数的逆函数无法求解或者不容易计算, 则不适用于逆变换采样法。 此时可以构造一个容易采样的参考分布, 先对参考分布进行采样, 然后对得到的样本进行一定的后处理操作, 使得最终的样本服从目标分布。
- 常见的拒绝采样(Rejection Sampling) 、 重要性采样(Importance Sampling) 就是上述的方法!
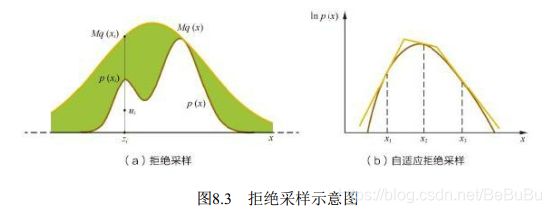
拒绝采样
-
又叫接受/拒绝采样(Accept-Reject Sampling)
-
对于目标分布 p ( x ) p(x) p(x),选取一个容易采样的参考分布 q ( x ) q(x) q(x) 使得对于任意 x x x 都有 p ( x ) ⩽ M ⋅ q ( x ) , p(x) \leqslant M \cdot q(x), p(x)⩽M⋅q(x), 则可以按如下过程进行采样:
-
(1)从参考分布 q ( x ) q(x) q(x) 中随机抽取一个样本 x i x_{i} xi
-
(2)从均勿分布U(0,1)产生一个随机数 u i u_{i} ui
-
(3) u i < p ( x i ) M q ( x i ) u_{i}<\frac{p\left(x_{i}\right)}{M q\left(x_{i}\right)} ui<Mq(xi)p(xi), 则接受样本 x i x_{i} xi否则拒绝,重新进行步骤 ( 1 ) ∼ ( 3 ) , (1) \sim(3), (1)∼(3), 直到新产生的样本 x i x_i xi被接受。
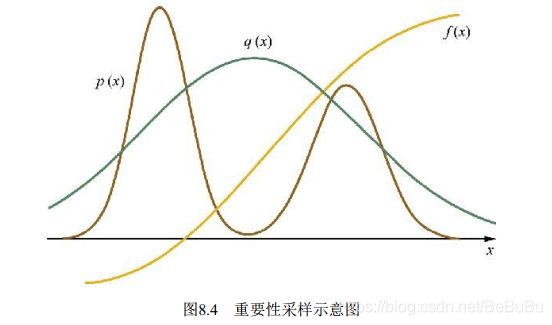
重要性采样
- 很多时候,采样的最终目的并不是为了得到样本,而是为了进行一些后续任务,如预测变量取值,这通常表现为一个求函数期望的形式。
- 重要性采样就是用于计算函数 f ( x ) f(x) f(x) 在目标分布 p ( x ) p(x) p(x)上的积分(函数期望),即:
E [ f ] = ∫ f ( x ) p ( x ) d x E[f]=\int f(x) p(x) \mathrm{d} x E[f]=∫f(x)p(x)dx
流程
- 首先,找一个比较容易抽样的参考分布 q ( x ) q(x) q(x) 并令 w ( x ) = p ( x ) q ( x ) , {w(x)}=\frac{p(x)}{q(x)}, w(x)=q(x)p(x), 则有:
E [ f ] = ∫ f ( x ) w ( x ) q ( x ) d x E[f]=\int f(x) w(x) q(x) \mathrm{d} x E[f]=∫f(x)w(x)q(x)dx
这里 w ( x ) w(x) w(x)可以看成是样本 x x x的重要性权重。 - 由此,可以先从参考分布 q ( x ) q(x) q(x) 中抽取N个样本 { x i } , \left\{x_{i}\right\}, {xi}, 然后利用如下公式来估计 E [ f ] E[f] E[f]
E [ f ] ≈ E ^ N [ f ] = ∑ i = 1 N f ( x i ) w ( x i ) E[f] \approx \hat{E}_{N}[f]=\sum_{i=1}^{N} f\left(x_{i}\right) w\left(x_{i}\right) E[f]≈E^N[f]=i=1∑Nf(xi)w(xi) - 如果不需要计算函数积分, 只想从目标分布 p ( x ) p(x) p(x) 中采样出若干样本, 则可以用重要性重采样(Sampling-Importance Re-sampling, SIR) , 先在从参考分布 q ( x ) q(x) q(x)中抽取 N N N个样本 x i {x_i} xi, 然后按照它们对应的重要性权重 w ( x i ) {w(xi)} w(xi)对这些样本进行重新采样(这是一个简单的针对有限离散分布的采样) , 最终得到的样本服从目标分布 p ( x ) p(x) p(x)
- 在实际应用中, 如果是高维空间的随机向量, 拒绝采样和重要性重采样经常难以寻找合适的参考分布, 采样效率低下(样本的接受概率小或重要性权重低) , 此时可以考虑马尔可夫蒙特卡洛采样法, 常见的有Metropolis-Hastings采样法和吉布斯采样法。 后续会专门介绍马尔可夫蒙特卡洛采样法, 这里不再赘述
对高斯分布进行采样
参考 — 链接
- 逆变换法
- Box-Muller算法
- Marsaglia polar method
- 拒绝采样法
马尔可夫蒙特卡洛采样
- 高维空间,且不需要参考概率!
- 蒙特卡洛法是指基于采样的数值型近似求解方法, 而马尔可夫链则用于进行采样。 MCMC采样法基本思想是: 针对待采样的目标分布, 构造一个马尔可夫链, 使得该马尔可夫链的平稳分布就是目标分布; 然后, 从任何一个初始状态出发, 沿着马尔可夫链进行状态转移, 最终得到的状态转移序列会收敛到目标分布, 由此可以得到目标分布的一系列样本。
- 核心点是如何构造合适的马尔可夫链, 即确定马尔可夫链的状态
转移概率 - 参考 — 链接
- 与一般的蒙特卡洛算法不同, MCMC采样法得到的样本序列中相邻的样本不是独立的,因为后一个样本是由前一个样本根据特定的转移概率得到的, 或者有一定概率就是前一个样本。
- 如果仅仅是采样, 并不需要样本之间相互独立。 如果确实需要产生独立同分布的样本,可以同时运行多条马尔可夫链, 这样不同链上的样本是独立的; 或者在同一条马尔可夫链上每隔若干个样本才选取一个, 这样选取出来的样本也是近似独立的。
贝叶斯网络采样
- 贝叶斯网络, 又称信念网络或有向无环图模型。 它是一种概率图模型, 利用有向无环图来刻画一组随机变量之间的条件概率分布关系
- 参考 — 链接
不均衡样本集的重采样
基于数据的方法
随机采样
- 最简单的处理不均衡样本集的方法是随机采样
- 随机过采样是从少数类样本集 S m i n S_{min} Smin中随机重复抽取样本(有放回) 以得到更多样本
- 随机欠采样则相反, 从多数类样本集 S m a x S_{max} Smax中随机选取较少的样本(有放回或无放回)
- 直接的随机采样虽然可以使样本集变得均衡, 但会带来一些问题, 比如, 过采样对少数类样本进行了多次复制, 扩大了数据规模, 增加了模型训练的复杂度, 同时也容易造成过拟合; 欠采样会丢弃一些样本, 可能会损失部分有用信息, 造成模型只学到了整体模式的一部分!
过采样改进 — SMOTE算法
- SMOTE算法对少数类样本集 S m i n S_{min} Smin中每个样本x, 从它在 S m i n S_{min} Smin的K近邻中随机选一个样本y, 然后在x,y连线上随机选取一点作为新合成的样本(根据需要的过采样倍率重复上述过程若干次)
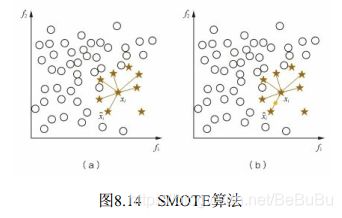
- SMOTE算法为每个少数类样本合成相同数量的新样本, 这可能会增大类间重叠度, 并且会生成一些不能提供有益信息的样本。
- 为此出现Borderline-SMOTE、 ADASYN等改进算法。
- Borderline-SMOTE只给那些处在分类边界上的少数类样本合成新样本
- ADASYN则给不同的少数类样本合成不同个数的新样本
- 还可以采用一些数据清理方法(如基于Tomek Links) 来进一步降低合成样本带来的类间重叠, 以得到更加良定义(well-defined) 的类簇,从而更好地训练分类器
欠采样改进 — Informed Undersampling
- Easy Ensemble算法:每次从多数类 S m a x S_{max} Smax中上随机抽取一个子集 E ( ∣ E ∣ ≈ ∣ S m i n ∣ ) E(|E|≈|S_{min}|) E(∣E∣≈∣Smin∣), 然后用 E + S m i n E+S_{min} E+Smin训练一个分类器; 重复上述过程若干次, 得到多个分类器, 最终的分类结果是这多个分类器结果的融合。
- Balance Cascade算法:级联结构, 在每一级中从多数类 S m a x S_{max} Smax中随机抽取子集 E E E,用 E + S m i n E+S_{min} E+Smin训练该级的分类器; 然后将 S m a x S_{max} Smax中能够被当前分类器正确判别的样本剔除掉, 继续下一级的操作, 重复若干次得到级联结构; 最终的输出结果也是各级分类器结果的融合
- 其他诸如NearMiss(利用K近邻信息挑选具有代表性的样本) 、 One-sided Selection(采用数据清理技术) 等算法
泛化扩展
- 基于聚类的采样方法, 利用数据的类簇信息来指导过采样/欠采样操作;
- 经常用到的数据扩充方法也是一种过采样, 对少数类样本进行一些噪声扰动或变换(如图像数据集中对图片进行裁剪、 翻转、 旋转、 加光照等) 以构造出新的样本;
- Hard Negative Mining则是一种欠采样, 把比较难的样本抽出来用于迭代分类器
基于算法的方法
- 在样本不均衡时, 也可以通过改变模型训练时的目标函数(如代价敏感学习中不同类别有不同的权重) 来矫正这种不平衡性 —— 如Focal Loss
- 当样本数目极其不均衡时, 也可以将问题转化为单类学习(one-class learning) 、 异常检测(anomaly detection)