K-均值聚类学习思考
简述:
k-means算法是最为经典的基于划分的聚类方法,是十大经典数据挖掘算法之一。K-means算法的基本思想是:以空间中k个点为中心进行聚类,对最靠近他们的对象归类。通过迭代的方法,逐次更新各聚类中心的值,直至得到最好的聚类结果。

算法描述:
假设要把样本集分为c个类别,算法描述如下:
(1)适当选择c个类的初始中心;(也可以随机选择)
(2)在第k次迭代中,对任意一个样本,求其到c个中心的距离,将该样本归到距离最短的中心所在的类;
(3)利用均值等方法更新该类的中心值;
(4)对于所有的c个聚类中心,如果利用(2)(3)的迭代法更新后,值保持不变,则迭代结束,否则继续迭代。
例子:
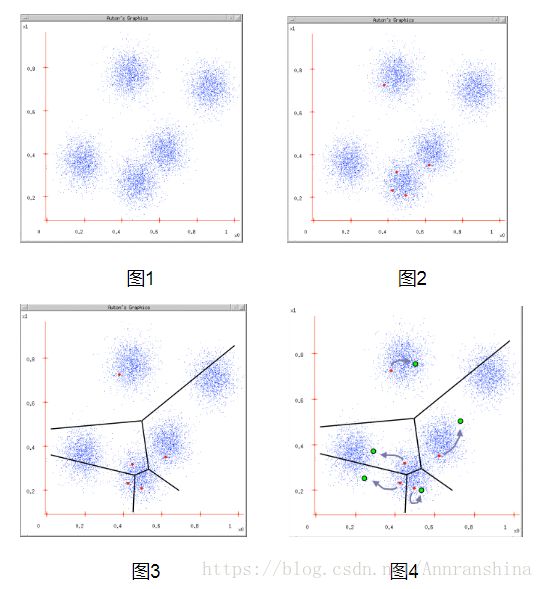
图1:给定一个数据集;
图2:根据K= 5初始化聚类中心,保证 聚类中心处于数据空间内;
图3:根据计算类内对象和聚类中心之间的相似度指标,将数据进行划分;
图4:将类内之间数据的均值作为聚类中心,更新聚类中心。
最后判断算法结束与否即可,目的是为了保证算法的收敛。
该算法的最大优势在于简洁和快速。算法的关键在于初始中心的选择和距离公式。
注意:
K-means++ 算法在初始点选择上遵循一个基本原则: 初始聚类中心点相互之间的距离应该尽可能的远。
基本步骤如下:
第一步,从数据集 X 中随机选择一个点作为第一个初始点。
第二步,计算数据集中所有点与最新选择的中心点的距离 D(x)。
第三步,选择下一个中心点,使得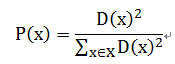 最大。
最大。
第四步,重复 (二),(三) 步过程,直到 K 个初始点选择完成。
如何选择K
K 的选择是 K-means 算法的关键,computeCost 方法,该方法通过计算所有数据点到其最近的中心点的平方和来评估聚类的效果。一般来说,同样的迭代次数和算法跑的次数,这个值越小代表聚类的效果越好。但是在实际情况下,我们还要考虑到聚类结果的可解释性,不能一味的选择使 computeCost 结果值最小的那个 K。
KMeans优缺点
优点:原理比较容易理解,容易实现,并且聚类效果良好,有着广泛的使用
缺点:(1)K-means算法不适用于非球形簇的聚类,而且不同尺寸和密度的类型的簇,也不太适合。
(2)可能收敛到局部值。
存在问题
K均值聚类
存在的问题
K-means 算法的特点——采用两阶段反复循环过程算法,结束的条件是不再有数据元素被重新分配:
指定聚类
即指定数据到某一个聚类,使得它与这个聚类中心的距离比它到其它聚类中心的距离要近。
修改聚类中心
优点:本算法确定的K 个划分到达平方误差最小。当聚类是密集的,且类与类之间区别明显时,效果较好。对于处理大数据集,这个算法是相对可伸缩和高效的,计算的复杂度为O(NKt),其中N是数据对象的数目,t是迭代的次数。一般来说,K< 用后处理来提高聚类性能 下面将使用上述技术得到更好的聚类结果方法。 二分K-均值算法 将所有点看成一个簇 当簇数目小于k时 对于每一个簇: 计算总误差 在给定的簇上面进行K-均值聚类(k=2) 计算将该簇一分为二后的总误差 选择使得误差最小的那个簇进行划分操作 函数biKmeans是上面二分K-均值聚类算法的实现,首先创建clusterAssment储存数据集中每个点的分类结果和平方误差,用centList保存所有已经划分的簇,初始状态为整个数据集。while循环不停对簇进行划分,寻找使得SSE值最大程度减小的簇并更新,添加新的簇到centList中。 实例——对地图上的点进行聚类 简述:一晚上需要去70个目的地,你需要确定一个将这些地方聚类的最佳策略,然后安排交通工具去这些簇的中心。 辅助工具: 1.Yahoo!PlaceFinder API:免费的地址转换API,该API对给定地址返回其经纬度。 2.经纬度计算:地球是球体,不能简单地进行两点之间直线距离公式。而应该求其测地线距离。 注意:弧度制角度制换算。 球面余弦定理: 点A:纬度β1 ,经度α1 ; 点B :纬度β2 ,经度α2。R:球半径 则距离 运行结果: 分为5个簇 【详细见附录】 [[-122.68111442 45.43248857] [-122.74038611 45.47046774]] [[-122.64921011 45.45681567] [-122.7055405 45.4645215 ]] [[-122.63869656 45.47002711] [-122.729196 45.43479575]] sseSplit,and notSplit: 195.09086134986362 1460.9594095632215 thebestCentToSplit is: 1 thelen of bestClustAss is: 30 小结: 1 聚类是一种无监督的学习方法。聚类区别于分类,即事先不知道要寻找的内容,没有预先设定好的目标变量。 2 聚类将数据点归到多个簇中,其中相似的数据点归为同一簇,而不相似的点归为不同的簇。相似度的计算方法有很多,具体的应用选择合适的相似度计算方法 3 K-means聚类算法,是一种广泛使用的聚类算法,其中k是需要指定的参数,即需要创建的簇的数目,K-means算法中的k个簇的质心可以通过随机的方式获得,但是这些点需要位于数据范围内。在算法中,计算每个点到质心得距离,选择距离最小的质心对应的簇作为该数据点的划分,然后再基于该分配过程后更新簇的质心。重复上述过程,直至各个簇的质心不再变化为止。 4 K-means算法虽然有效,但是容易受到初始簇质心的情况而影响,有可能陷入局部最优解。为了解决这个问题,可以使用另外一种称为二分K-means的聚类算法。二分K-means算法首先将所有数据点分为一个簇;然后使用K-means(k=2)对其进行划分;下一次迭代时,选择使得SSE下降程度最大的簇进行划分;重复该过程,直至簇的个数达到指定的数目为止。实验表明,二分K-means算法的聚类效果要好于普通的K-means聚类算法。 参考文献: 附录:
一种降低SSE的方法是增加簇的个数,即提高k值,但是违背了聚类的目标,聚类的目标是在不改变簇数目的前提下提高簇的质量。可选的改进的方法是对生成的簇进行后处理,将最大SSE值的簇划分成两个(K=2的K-均值算法),然后再进行相邻的簇合并。具体方法有两种:1、合并最近的两个质心(合并使得SSE增幅最小的两个质心)2、遍历簇 合并两个然后计算SSE的值,找到使得SSE最小的情况。
二分K-均值类似后处理的切分思想,初始状态所有数据点属于一个大簇,之后每次选择一个簇切分成两个簇,这个切分满足使SSE值最大程度降低,直到簇数目达到k。另一种思路是每次选择SSE值最大的一个簇进行切分。
满足使SSE值最大程度降低伪代码如下:![]()

def distSLC(vecA, vecB):#Spherical Law of Cosines
a = sin(vecA[0,1]*pi/180) * sin(vecB[0,1]*pi/180)
b = cos(vecA[0,1]*pi/180) * cos(vecB[0,1]*pi/180) * \
cos(pi * (vecB[0,0]-vecA[0,0]) /180)
return arccos(a + b)*6371.0 #pi is imported with numpy


"""
调用函数
Created on Tue Jun 5 13:49:39 2018
@author: Administrator
"""
from kMeans import *
clusterClubs(5)
'''
kMeans.py
来源:机器学习实战
且作者改写为适用于python3.0及以上版本
'''
from numpy import *
def loadDataSet(fileName): #general function to parse tab -delimited floats
dataMat = [] #assume last column is target value
fr = open(fileName)
for line in fr.readlines():
curLine = line.strip().split('\t')
fltLine = map(float,curLine) #map all elements to float()
dataMat.append(fltLine)
return dataMat
def distEclud(vecA, vecB):
return sqrt(sum(power(vecA - vecB, 2))) #la.norm(vecA-vecB)
def randCent(dataSet, k):
n = shape(dataSet)[1]
centroids = mat(zeros((k,n)))#create centroid mat
for j in range(n):#create random cluster centers, within bounds of each dimension
minJ = min(dataSet[:,j])
rangeJ = float(max(dataSet[:,j]) - minJ)
centroids[:,j] = mat(minJ + rangeJ * random.rand(k,1))
return centroids
def kMeans(dataSet, k, distMeas=distEclud, createCent=randCent):
m = shape(dataSet)[0]
clusterAssment = mat(zeros((m,2)))#create mat to assign data points
#to a centroid, also holds SE of each point
centroids = createCent(dataSet, k)
clusterChanged = True
while clusterChanged:
clusterChanged = False
for i in range(m):#for each data point assign it to the closest centroid
minDist = inf; minIndex = -1
for j in range(k):
distJI = distMeas(centroids[j,:],dataSet[i,:])
if distJI < minDist:
minDist = distJI; minIndex = j
if clusterAssment[i,0] != minIndex: clusterChanged = True
clusterAssment[i,:] = minIndex,minDist**2
print (centroids)
for cent in range(k):#recalculate centroids
ptsInClust = dataSet[nonzero(clusterAssment[:,0].A==cent)[0]]#get all the point in this cluster
centroids[cent,:] = mean(ptsInClust, axis=0) #assign centroid to mean
return centroids, clusterAssment
def biKmeans(dataSet, k, distMeas=distEclud):
m = shape(dataSet)[0]
clusterAssment = mat(zeros((m,2)))
centroid0 = mean(dataSet, axis=0).tolist()[0]
centList =[centroid0] #create a list with one centroid
for j in range(m):#calc initial Error
clusterAssment[j,1] = distMeas(mat(centroid0), dataSet[j,:])**2
while (len(centList) < k):
lowestSSE = inf
for i in range(len(centList)):
ptsInCurrCluster = dataSet[nonzero(clusterAssment[:,0].A==i)[0],:]#get the data points currently in cluster i
centroidMat, splitClustAss = kMeans(ptsInCurrCluster, 2, distMeas)
sseSplit = sum(splitClustAss[:,1])#compare the SSE to the currrent minimum
sseNotSplit = sum(clusterAssment[nonzero(clusterAssment[:,0].A!=i)[0],1])
print ("sseSplit, and notSplit: ",sseSplit,sseNotSplit)
if (sseSplit + sseNotSplit) < lowestSSE:
bestCentToSplit = i
bestNewCents = centroidMat
bestClustAss = splitClustAss.copy()
lowestSSE = sseSplit + sseNotSplit
bestClustAss[nonzero(bestClustAss[:,0].A == 1)[0],0] = len(centList) #change 1 to 3,4, or whatever
bestClustAss[nonzero(bestClustAss[:,0].A == 0)[0],0] = bestCentToSplit
print ('the bestCentToSplit is: ',bestCentToSplit)
print ('the len of bestClustAss is: ', len(bestClustAss))
centList[bestCentToSplit] = bestNewCents[0,:].tolist()[0]#replace a centroid with two best centroids
centList.append(bestNewCents[1,:].tolist()[0])
clusterAssment[nonzero(clusterAssment[:,0].A == bestCentToSplit)[0],:]= bestClustAss#reassign new clusters, and SSE
return mat(centList), clusterAssment
import urllib
import json
def geoGrab(stAddress, city):
apiStem = 'http://where.yahooapis.com/geocode?' #create a dict and constants for the goecoder
params = {}
params['flags'] = 'J'#JSON return type
params['appid'] = 'aaa0VN6k'
params['location'] = '%s %s' % (stAddress, city)
url_params = urllib.urlencode(params)
yahooApi = apiStem + url_params #print url_params
print (yahooApi)
c=urllib.urlopen(yahooApi)
return json.loads(c.read())
from time import sleep
def massPlaceFind(fileName):
fw = open('places.txt', 'w')
for line in open(fileName).readlines():
line = line.strip()
lineArr = line.split('\t')
retDict = geoGrab(lineArr[1], lineArr[2])
if retDict['ResultSet']['Error'] == 0:
lat = float(retDict['ResultSet']['Results'][0]['latitude'])
lng = float(retDict['ResultSet']['Results'][0]['longitude'])
print ("%s\t%f\t%f" % (lineArr[0], lat, lng))
fw.write('%s\t%f\t%f\n' % (line, lat, lng))
else: print( "error fetching")
sleep(1)
fw.close()
def distSLC(vecA, vecB):#Spherical Law of Cosines
a = sin(vecA[0,1]*pi/180) * sin(vecB[0,1]*pi/180)
b = cos(vecA[0,1]*pi/180) * cos(vecB[0,1]*pi/180) * \
cos(pi * (vecB[0,0]-vecA[0,0]) /180)
return arccos(a + b)*6371.0 #pi is imported with numpy
import matplotlib
import matplotlib.pyplot as plt
def clusterClubs(numClust=5):
datList = []
for line in open('places.txt').readlines():
lineArr = line.split('\t')
datList.append([float(lineArr[4]), float(lineArr[3])])
datMat = mat(datList)
myCentroids, clustAssing = biKmeans(datMat, numClust, distMeas=distSLC)
fig = plt.figure()
rect=[0.1,0.1,0.8,0.8]
scatterMarkers=['s', 'o', '^', '8', 'p', \
'd', 'v', 'h', '>', '<']
axprops = dict(xticks=[], yticks=[])
ax0=fig.add_axes(rect, label='ax0', **axprops)
imgP = plt.imread('Portland.png')
ax0.imshow(imgP)
ax1=fig.add_axes(rect, label='ax1', frameon=False)
for i in range(numClust):
ptsInCurrCluster = datMat[nonzero(clustAssing[:,0].A==i)[0],:]
markerStyle = scatterMarkers[i % len(scatterMarkers)]
ax1.scatter(ptsInCurrCluster[:,0].flatten().A[0], ptsInCurrCluster[:,1].flatten().A[0], marker=markerStyle, s=90)
ax1.scatter(myCentroids[:,0].flatten().A[0], myCentroids[:,1].flatten().A[0], marker='+', s=300)
plt.show()
[[-122.4693261 45.47138674]
[-122.38260849 45.44485082]]
[[-122.63543168 45.5135124 ]
[-122.376304 45.430319 ]]
[[-122.63856419 45.51360033]
[-122.4009285 45.46897 ]]
[[-122.64533773 45.51357016]
[-122.4568086 45.4961344 ]]
[[-122.66149437 45.51440946]
[-122.50322869 45.50324862]]
[[-122.67273274 45.51397274]
[-122.52363268 45.50792237]]
[[-122.68917857 45.50793286]
[-122.54222807 45.51911044]]
[[-122.69551477 45.50729503]
[-122.54868607 45.51882187]]
sseSplit,and notSplit: 3043.2633161055337 0.0
thebestCentToSplit is: 0
thelen of bestClustAss is: 69
[[-122.66271847 45.5989936 ]
[-122.75031153 45.44633864]]
[[-122.68405068 45.54862674]
[-122.70640565 45.4680299 ]]
sseSplit,and notSplit: 1379.8222401289108851.4388885817106
[[-122.50822734 45.54632347]
[-122.59885254 45.51279708]]
[[-122.50339758 45.50865767]
[-122.57887839 45.525598 ]]
[[-122.50186825 45.49706533]
[-122.57989794 45.53332622]]
[[-122.49860291 45.49496564]
[-122.57768158 45.53263337]]
sseSplit,and notSplit: 464.72059834529512191.824427523823
thebestCentToSplit is: 0
thelen of bestClustAss is: 39
[[-122.65203517 45.63616677]
[-122.78690864 45.55927426]]
[[-122.6587032 45.5646778 ]
[-122.69310336 45.54289421]]
[[-122.67875743 45.57335714]
[-122.68713842 45.53420067]]
[[-122.72070683 45.59796783]
[-122.66713246 45.52585392]]
sseSplit,and notSplit: 214.884449737288381680.9549600857222
[[-122.48942004 45.48810764]
[-122.60249884 45.55769838]]
[[-122.51686212 45.49922575]
[-122.58505629 45.54121743]]
sseSplit,and notSplit: 477.91688463463291379.8222401289108
[[-122.79866092 45.496745 ]
[-122.69545043 45.3955361 ]]
[[-122.76523086 45.49528114]
[-122.67473054 45.45335615]]
[[-122.78043714 45.484453 ]
[-122.66654254 45.45918669]]
sseSplit,and notSplit: 434.840788678321401.7450572066102
thebestCentToSplit is: 2
thelen of bestClustAss is: 20
[[-122.82866782 45.57344812]
[-122.83042303 45.51450655]]
[[-122.72072414 45.59011757]
[-122.66265783 45.52442375]]
[[-122.72070683 45.59796783]
[-122.66713246 45.52585392]]
sseSplit,and notSplit: 214.884449737288381286.279677260031
[[-122.48141504 45.52471367]
[-122.49251682 45.51358392]]
[[-122.4540165 45.5133815 ]
[-122.55544818 45.51921046]]
[[-122.4568086 45.4961344 ]
[-122.56706156 45.52335936]]
sseSplit,and notSplit: 505.61960820164956985.1469573032196
[[-122.80003038 45.50287617]
[-122.7926128 45.47968729]]
[[-122.774 45.503195 ]
[-122.783012 45.4769562]]
[[-122.77716225 45.4982345 ]
[-122.78480367 45.46607767]]
[[-122.78288433 45.4942305 ]
[-122.765754 45.425788 ]]
sseSplit,and notSplit: 8.038610743803597 1777.371493528319
[[-122.68111442 45.43248857]
[-122.74038611 45.47046774]]
[[-122.64921011 45.45681567]
[-122.7055405 45.4645215 ]]
[[-122.63869656 45.47002711]
[-122.729196 45.43479575]]
sseSplit,and notSplit: 195.09086134986362 1460.9594095632215
thebestCentToSplit is: 1
thelen of bestClustAss is: 30