Yolo算法--从原理到实现(一)
YOLO算法:从v1到v3
yolo是目前比较流行的目标检测算法,速度快结构简单。其他的目标检测算法也有RCNN,faster-RCNN, SSD等。
近几年来,目标检测算法取得了很大的突破。比较流行的算法可以分为两类,一类是基于Region Proposal的R-CNN系算法(R-CNN,Fast R-CNN, Faster R-CNN),它们是two-stage的,需要先使用启发式方法(selective search)或者CNN网络(RPN)产生Region Proposal,然后再在Region Proposal上做分类与回归。而另一类是Yolo,SSD这类one-stage算法,其仅仅使用一个CNN网络直接预测不同目标的类别与位置。第一类方法是准确度高一些,但是速度慢,但是第二类算法是速度快,但是准确性要低一些。本文首先介绍的是Yolo1算法,其全称是You Only Look Once: Unified, Real-Time Object Detection,题目基本上把Yolo算法的特点概括全了:You Only Look Once说的是只需要一次CNN运算,Unified指的是这是一个统一的框架,提供end-to-end的预测,而Real-Time体现是Yolo算法速度快,达到实时。这个题目是Yolo-v1论文的,其性能是差于后来的SSD算法的,但是Yolo后来也继续进行改进,产生了Yolo9000算法,和Yolov3。
检测对于计算机视觉中就是检测到目标物的位置,而识别则是说,对检测到的这个东西,你告诉我这是属于哪一类,比如说检测到一只狗,你要告诉我这只狗是京巴还是藏獒。那么目标检测到底有什么用途呢?举个例子:比如在无人车上安装一个障碍物检测系统,那么无人车的摄像头就相当于人的眼睛,当捕捉到画面前方有障碍物时,要得到障碍物的具体位置和类别,以便及时作出决策。
为了理解yolo,首先先介绍一下滑动窗口技术。采用滑动窗口的目标检测算法思路非常简单,它将检测问题转化为了图像分类问题。其基本原理就是采用不同大小和比例(宽高比)的窗口在整张图片上以一定的步长进行滑动,然后对这些窗口对应的区域做图像分类(应该是在学习这个东西是目标物还是背景)如下图所示。但是你并不知道要检测的目标大小是什么规模,所以你要设置不同大小和比例的窗口去滑动,而且还要选取合适的步长,这样会产生很多的子区域,并且都要经过分类器去做预测,这需要很大的计算量,所以你的分类器不能太复杂,因为要保证速度。解决思路之一就是减少要分类的子区域,这就是R-CNN(基于区域提名的CNN)的一个改进策略,其采用了selective search方法来找到最有可能包含目标的子区域(Region Proposal),其实可以看成采用启发式方法过滤掉很多子区域,这会提升效率。

yolo设计理念
整体来看,Yolo算法采用一个单独的CNN模型实现end-to-end的目标检测,首先将输入图片resize到448x448,然后送入CNN网络,最后处理网络预测结果得到检测的目标。其速度更快,而且Yolo的训练过程也是端到端的。与滑动窗口不同的是,yolo先将图片分成S*S个块。每个单元格会预测B个边界框(bounding box)以及边界框的置信度(confidence score)。所谓置信度其实包含两个方面,一是这个框中目标存在的可能性大小,二是这个边界框的位置准确度。前者我们把它记做Pr(obj),若框中没有目标物,则Pr(obj)=0,若含有目标物则Pr(obj)=1 。那么边界框的位置的准确度怎么去判断呢?我们使用了一种叫做IOU(交并比)的方法,意思就是说我预测的框与你真实的框相交的面积,和预测的框与真实框合并的面积的比例。我们可以记做IOU(pred),那么置信度就可以定义为这两项相乘。so,现在有了另一个问题,我每个格子预测的边界框应该怎么表示呢? 边界框的大小和位置可以用四个值来表示,(x,y,w,h)注意,不要凭空想象是一个矩形对角两个点的位置坐标,这里面的x,y是指预测出的边界框的中心位置相对于这个格子的左上角位置的偏移量,而且这个偏移量不是以像素为单位,而是以这个格子的大小为一个单位。如果不明白可以用下面这张图去举个例子。下面这个框的中心点所在的位置,相对于中心点所在的这个格子的x,y差不多是0.3, 0.7, (不明白的话就仔细琢磨一下)。而这个w,h指的是这个框的大小,占整张图片大小的宽和高的相对比例,想一下,有了中心点的位置,有了框的大小,画出一个框是很容易的对吧。(x,y,w,h,c)这五个值理论上都应该在[0,1]区间上。最后一个c是置信度的意思。一般一个网格会预测多个框,而置信度是用来评判哪一个框是最准确的,我们最想得到的框。
框预测好了,接下来就是分类的问题,每个单元格预测出(x,y,w,h,c)的值后,还要给出对于C个类别的概率值。现在重新提一下字母的含义,B是边界框的个数,C是我有多少个类别要分类。S是我怎么划分单元格。那么我每个单元格要预测B*5+C个值。如果将输入图片划分为S×S网格,那么最终预测值为S×S×(B∗5+C)大小的张量。
网络模型:

对于卷积层和全连接层,采用Leaky ReLU激活函数:max(x,0.1x)max(x,0.1x)。最后一层采用线性激活函数。
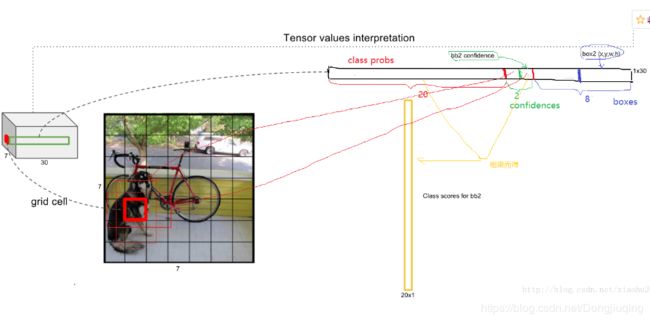
可以看到网络的最后输出为7×7×30大小的张量。这和前面的讨论是一致的。这个张量所代表的具体含义如下图所示。对于每一个单元格,前20个元素是类别概率值,然后2个元素是边界框置信度,两者相乘可以得到类别置信度,最后8个元素是边界框的(x,y,w,h)。大家可能会感到奇怪,对于边界框为什么把置信度c和(x,y,w,h)都分开排列,而不是按照(x,y,w,h,c)这样排列,其实纯粹是为了计算方便,因为实际上这30个元素都是对应一个单元格,其排列是可以任意的。但是分离排布,可以方便地提取每一个部分。这里来解释一下,首先网络的预测值是一个二维张量PP,其shape为[batch,7×7×30]。采用切片,那么![]() 就是类别概率部分,而
就是类别概率部分,而![]() 是置信度部分,最后剩余部分
是置信度部分,最后剩余部分![]() 是边界框的预测结果。这样,提取每个部分是非常方便的,这会方面后面的训练及预测时的计算。
是边界框的预测结果。这样,提取每个部分是非常方便的,这会方面后面的训练及预测时的计算。
下面是训练损失函数的分析,Yolo算法将目标检测看成回归问题,采用的是均方差损失函数。但是对不同的部分造成的误差采用了不同的权重值。还有一点就是较小的边界框的坐标误差应该要比较大的边界框要更敏感。为了保证这一点,将网络的边界框的宽与高预测改为对其平方根的预测,即预测值变为![]() ,为什么呢?因为你想一下比如w和h为0.1或者更小,那么我稍微一点点的幅度,我这个框变化就很明显。比如我从0.1到0.15,这个变化相对于0.1增加很多,但是同样的我预测有误差,而误差是从0.4到0.45,这个增大几乎是看不出来的。因此对于一个小框,如果我偏移大的话,会更加影响框的准确性,有可能因为我这一个小小的偏移,导致我这个物体不再框里面了,所以这就是为什么要让小得边界框的误差比大的边界框误差要更加敏感。通过开根号可以达到这个效果,因为一个小于一的数,开平方会被放大,而且越小,开平方后相比原来的数差别就更大。(如果不理解这一点可以慢慢思考一下,或者跳过也没关系)
,为什么呢?因为你想一下比如w和h为0.1或者更小,那么我稍微一点点的幅度,我这个框变化就很明显。比如我从0.1到0.15,这个变化相对于0.1增加很多,但是同样的我预测有误差,而误差是从0.4到0.45,这个增大几乎是看不出来的。因此对于一个小框,如果我偏移大的话,会更加影响框的准确性,有可能因为我这一个小小的偏移,导致我这个物体不再框里面了,所以这就是为什么要让小得边界框的误差比大的边界框误差要更加敏感。通过开根号可以达到这个效果,因为一个小于一的数,开平方会被放大,而且越小,开平方后相比原来的数差别就更大。(如果不理解这一点可以慢慢思考一下,或者跳过也没关系)
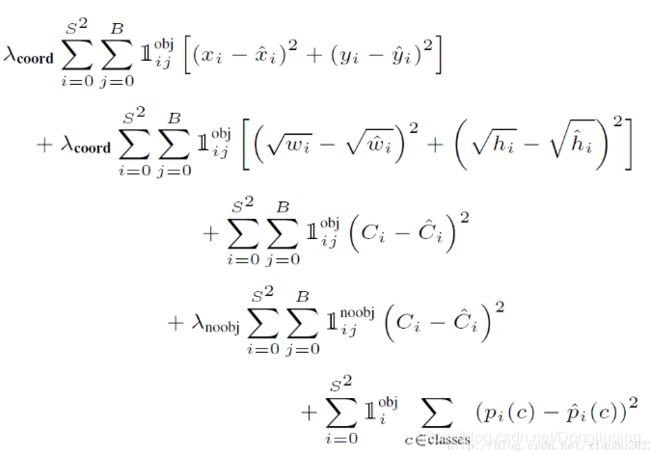
其中第一项是边界框中心坐标的误差项,![]() 指的是第 i 个单元格存在目标,且该单元格中的第 j 个边界框负责预测该目标。第二项是边界框的高与宽的误差项。第三项是包含目标的边界框的置信度误差项。第四项是不包含目标的边界框的置信度误差项。而最后一项是包含目标的单元格的分类误差项,
指的是第 i 个单元格存在目标,且该单元格中的第 j 个边界框负责预测该目标。第二项是边界框的高与宽的误差项。第三项是包含目标的边界框的置信度误差项。第四项是不包含目标的边界框的置信度误差项。而最后一项是包含目标的单元格的分类误差项,![]() 指的是第 i 个单元格存在目标。
指的是第 i 个单元格存在目标。
当然这其中还用到了另一种机制,叫做NMS(non maximum suppression)非极大值抑制算法。NMS算法主要解决的是一个目标被多次检测的问题。这个机制不是针对YOLO的,而是对于各种检测算法都有用到。就比如说YOLO,yolo-v1预测了两个边界框,但是我检测的时候总不能把两个框都画上去吧,因此我只取概率值最大的那个框,这就叫做非极大值抑制,除了极大概率的那个框,别的我丢弃。

YOLO的缺点
1.YOLO对相互靠的很近的物体,还有很小的群体 检测效果不好,这是因为一个网格中只预测了两个框,并且只属于一类。
2.同一类物体出现的新的不常见的长宽比和其他情况时,泛化能力偏弱。
3.由于损失函数的问题,定位误差是影响检测效果的主要原因。尤其是大小物体的处理上,还有待加强。
yolo-v2的改进
Batch Normalization
CNN在训练过程中网络每层输入的分布一直在改变, 会使训练过程难度加大,但可以通过normalize每层的输入可以解决这个问题。新的YOLO网络在每一个卷积层后添加batch normalization,通过这一方法,mAP(精度)获得了2%的提升。batch normalization 也有助于规范化模型,可以在舍弃dropout优化后依然不会过拟合。
High Resolution Classifier
目前的目标检测方法中,基本上都会使用ImageNet预训练过的模型(classifier)来提取特征,如果用的是AlexNet网络,那么输入图片会被resize到不足256 * 256,导致分辨率不够高,给检测带来困难。为此,新的YOLO网络把分辨率直接提升到了448 * 448,这也意味之原有的网络模型必须进行某种调整以适应新的分辨率输入。
对于YOLOv2,作者首先对分类网络(自定义的darknet)进行了微调,分辨率改成448 * 448,在ImageNet数据集上训练10轮(10 epochs),训练后的网络就可以适应高分辨率的输入了。然后,作者对检测网络部分(也就是后半部分)也进行微调。这样通过提升输入的分辨率,mAP(精度)获得了4%的提升。
Convolutional With Anchor Boxes
之前的YOLO利用全连接层的数据完成边框的预测,导致丢失较多的空间信息,定位不准。作者在这一版本中借鉴了Faster R-CNN中的anchor思想,回顾一下,anchor是RPN网络中的一个关键步骤,说的是在卷积特征图上进行滑窗操作,每一个中心可以预测9种不同大小的建议框。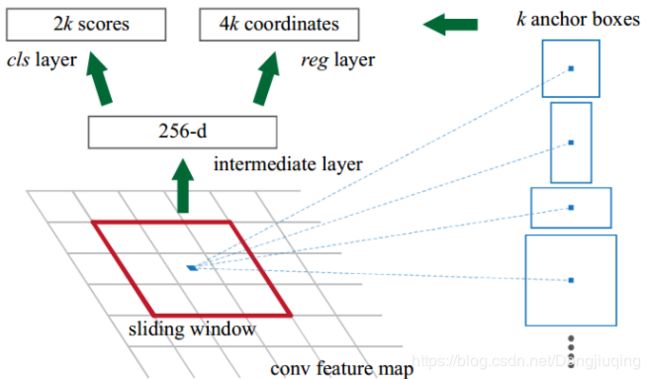
为了引入anchor boxes来预测bounding boxes,作者在网络中果断去掉了全连接层。剩下的具体怎么操作呢?首先,作者去掉了后面的一个池化层以确保输出的卷积特征图有更高的分辨率。然后,通过缩减网络,让图片输入分辨率为416 * 416,这一步的目的是为了让后面产生的卷积特征图宽高都为奇数,这样就可以产生一个center cell。作者观察到,大物体通常占据了图像的中间位置, 就可以只用中心的一个cell来预测这些物体的位置,否则就要用中间的4个cell来进行预测,这个技巧可稍稍提升效率。最后,YOLOv2使用了卷积层降采样(factor为32),使得输入卷积网络的416 * 416图片最终得到13 * 13的卷积特征图(416/32=13)。
加入了anchor boxes后,可以预料到的结果是查全率上升,准确率下降。我们来计算一下,假设每个cell预测9个建议框,那么总共会预测13 * 13 * 9 = 1521个boxes,而之前的网络仅仅预测7 * 7 * 2 = 98个boxes。具体数据为:没有anchor boxes,模型查全率为81%,mAP为69.5%;加入anchor boxes,模型查全率为88%,mAP为69.2%。这样看来,准确率只有小幅度的下降,而查全率则提升了7%,说明可以通过进一步的工作来加强准确率,的确有改进空间。
而yolo-v3则是将格子划分的更细了一些从13*13细化到了19*19,每个框预测3个框,在一定程度上缓解了小目标检测不到的问题以及多个框重叠在一起只能画出一个框的问题。细节请去阅读论文。
对于yolo,官方给出了使用darknet框架训练的压缩包。但是使用darknet框架训练,难以理解其中的细节了,调试起来非常困难,对于darknet,我做到的只能是做出训练数据,然后把数据丢进网络进行训练,完全没有tensorflow的那种运算框架非常清晰地感觉。(甚至找不到darknet训练网络的时候损失函数定义在哪里。)之后我可以给出一个用darknet训练yolo的具体步骤,但是我还是想去用tensorflow或者keras训练自己的数据。在tensorflow或者keras的train.py文件中可以清晰地看出逻辑关系。
参考博客https://blog.csdn.net/xiaohu2022/article/details/79211732
https://blog.csdn.net/jesse_mx/article/details/53925356
https://blog.csdn.net/app_12062011/article/details/77554288
https://blog.csdn.net/zxyhhjs2017/article/details/83013297