爬虫入门实战课
写在最前
通过爬虫,可以搜集互联网上很多信息,有助于科研(比如爬个会议的网站之类的),因此想以应用带动一下学习,因此就有了这个小练手。另外这个课程算是慕课网上的爬虫入门实现吧:这里是课程入口
爬虫代码的主要结构
一个爬虫主要由四部分组成:
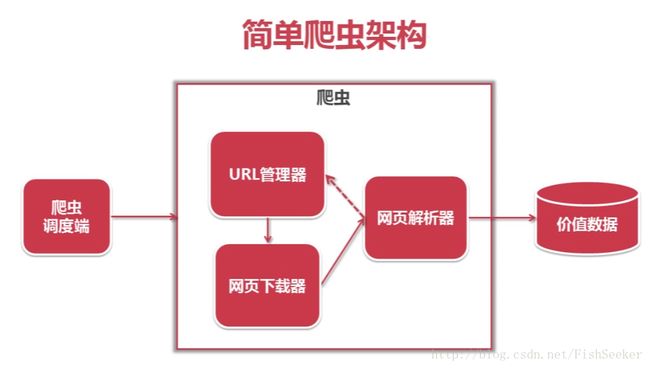
- 其中调度端相当于main函数,能启动这些组件。
- URL管理器是用来存储URL的,这个URL啊就是网址。这个URL管理器里面有两个集合,一个是已经访问过的URL另一个是尚未访问过的URL。平常就是从那个尚未访问过的集合中取出一个URL进行爬,爬出来的内容里还有新的URL,然后你判断一下,这个URL是不是从来都没出现过,如果是的话,就放到那个新URL的集合里就行了。
- 网页下载器就是用URL把整个网页都搞下来变成个文本
网页解析器貌似最重要,是把你用下载器下载下来的文本,弄成一个树型的结构,然后能够让你找到你需要的内容。
以上就是主要结构,而我们的代码也是需要完成以上这些结构的。
主要任务
本课程的主要任务就是,从百度百科的某个词条作为入口,将和其相关的词条和其相关的词条相关的词条(无限循环。。。)的名字和摘要弄出来,输出到一个html网页中,我们选用的是spark这个关键词,最后爬出来的结果是酱的:

当然是简陋得一批,不过入手嘛,得先易后难循序渐进是吧(认真脸)
调度端
视频里是先写的这个调度端,很有趣,就像写作文把主要结构写出来了,然后再细化。
这是main函数:
if __name__=="__main__":
root_url="http://baike.baidu.com/item/SPARK"
obj_spider= SpiderMain()
obj_spider.craw(root_url)就是,有个spidermain这么个类,然后这个类有个craw方法。如上面所说,这个类里得有至少仨东西,url管理器,下载器,分析器,当然最后要输出一波,就得再加个输出器。
之后发挥想象地先写出框架:
class SpiderMain(object):
def __init__(self):
self.urls = url_manager.UrlManager()
self.downloader=html_downloader.HtmlDownloader()
self.parser=html_parser.HtmlParser()
self.outputer=html_outputer.HtmlOutputer()
def craw(self, root_url):
count = 1
self.urls.add_new_url(root_url) # 把根url加入
while self.urls.has_new_url(): # 如果新的url
try:
new_url = self.urls.get_new_url() # 获得这个url
print 'craw %d : %s'%(count,new_url)
html_cont=self.downloader.download(new_url) # 从这个url下载内容
new_urls, new_data=self.parser.parse(new_url,html_cont) # 从内容中获取url和data
self.urls.add_new_urls(new_urls) # 将获取的url加到url列表里
self.outputer.collect_data(new_data) # 输出data
if count == 10:
break
count = count + 1
except:
print "craw failed"
self.outputer.output_html()是不是很简单很易懂,在构造函数里得让这个类有四个组件,看名字就知道它们是做什么的了。然后craw函数当然是用来爬网页的了。注释写得也很明白了,而且需要注意的是,这些方法,我们还都只有个名字哦,其他什么都没有,所有的东西都好像是用自然语言写出来而不是程序。之后的工作,当然是完善这些组件了。
URL管理器
上文也讲了,这个URL管理器,维护了两个集合,已经用过的集合和尚未用过的集合,这是为了防止循环爬取已经爬过的URL。通过主函数的代码能看出来,这个URL管理器需要实现四个方法:
# coding:utf8
class UrlManager(object):
def __init__(self): # 维护两个集合,新的url和用过的url
self.new_urls = set()
self.old_urls = set()
def add_new_url(self, url):
if url is None:
return
if url not in self.new_urls and url not in self.old_urls: # 如果两个集合都不在,就说明是新的url
self.new_urls.add(url)
def add_new_urls(self, urls):
if urls is None or len(urls) == 0:
return
for url in urls:
self.add_new_url(url)
def has_new_url(self):
return len(self.new_urls) != 0
def get_new_url(self): # 获得新的url并放到用过的url集合里
new_url=self.new_urls.pop()
self.old_urls.add(new_url)
return new_url其中add_new_url是为了增加单个的URL而add_new_urls是为了增加一组URL。而且这个add_new_urls也是调用了add_new_url完成的。
下载器
这个下载的功能十分简单,就是把指定URL的内容都下载下来就行:
# coding:utf8
import urllib2
class HtmlDownloader(object):
def download(self, url):
if url is None:
return None
res=urllib2.urlopen(url)
if res.getcode() != 200:
return None
return res.read()这里引入了个啥玩意库,反正这库就有这功能,就是能open一个URL就是了。最后返回一个字符串,这个字符串就是html代码。
解析器
这才是最最重点的地方。这个解析器的原理就是,你获得了HTML的内容之后,其实每块内容都是由标签的,比如我们想找标题和摘要,这里标题的标签叫bulabula-title,摘要的标签叫bubulala-summary什么的,然后我们就根据这个标签,就用(人家写好的)解析器解析出你要的内容就可以了。
另外,解析器需要获得两个东西,一个是URL列表,另外是内容。你应该知道是为啥吧,不知道的话请留言(说得就好像有人看似的,微笑)
主方法:
def parse(self, page_url, html_cont):
if page_url is None or html_cont is None:
return
soup=BeautifulSoup(html_cont,'html.parser',from_encoding='utf-8')
new_urls = self._get_new_urls(page_url,soup)
new_data = self._get_new_data(page_url,soup)
return new_urls,new_data这里的BeautifulSoup(好看的汤?)就是那个别人家的解析器,第一个参数是网页内容,第二个参数是它使用的解析方法,第三个是网页的编码方式。
获得标签
如何才能知道你想要的内容的标签呢,比如那个bulabula-title到底应该填蛇,这里用的是chrome的‘检查’功能。就是,对着你想要看的元素右键,然后点击检查,就能看到了,效果如图:
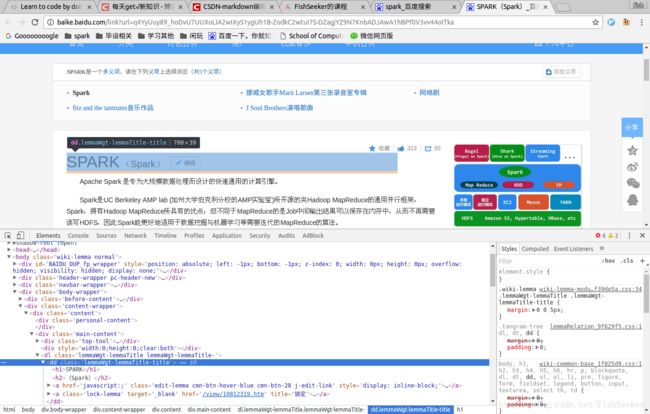
你会看到标题那里有了阴影,说明就是这块了。这样我们就得到了它们的标签:lemmaWgt-lemmaTitle-title和lemma-summary
获取URL列表
要从那碗汤里弄出来URL,需要以下代码:
def _get_new_urls(self, page_url, soup):
new_urls = set()
# /item/Hadoop
links = soup.find_all('a', href=re.compile(r"/item/\w+")) # 正则表达式
for link in links:
new_url = link['href']
new_full_url = urlparse.urljoin(page_url,new_url) # 这个方法会将new_url按照page_url的格式拼接成新的url
new_urls.add(new_full_url)
return new_urls因为知道百度百科URL的格式就是/item/*这种,因此我们从soup里找这个,放到URL列表里,之后返回。
获取数据
获取数据的原理也基本一样:
def _get_new_data(self, page_url, soup):
res_data = {} # 这是个字典
res_data['url'] = page_url
#×××
这个class_(一定要注意下划线)就是那个生成的树的节点名。这样,我们获得了正常人能够阅读的内容了。
输出器
既然已经获得了内容,那么就要输出到一个文件里看看,这里就手动写一个html网页,就可以了:
# coding:utf8
class HtmlOutputer(object):
def __init__(self):
self.datas = []
def collect_data(self,data): # 先获取到数据集
if data is None:
return
self.datas.append(data)
def output_html(self):
fout = open('output.html','w')
fout.write("")
fout.write("")
fout.write("")
for data in self.datas:
fout.write("")
fout.write("%s " % data['url'])
fout.write("%s " % data['title'].encode('utf-8'))
fout.write("%s " % data['summary'].encode('utf-8'))
fout.write(" ")
fout.write("
")
fout.write("")
fout.write("")
最后
然后运行起来了之后就能看到我们在开头的输出的网页了。这里是代码:点我。导入到idea或者pycharm里可以运行。不懂的,建议看看开头的课程,或者,直接评论区见~