基于论文的Fast R-CNN学习
基于论文的Fast R-CNN学习
Fast R-CNN的提出在R-CNN和SPPnet之后,它针对了R-CNN每个proposal都需要通过CNN而导致计算速度慢和SPPnet由于不能更新conv layer而导致的精度低的问题,在速度和精度方面都有一定的提升。
论文链接
方法的主要优点有:
- 更高的mAP;
- 使用了multi-task loss,训练更简单;
- 训练可以更新所有的网络层;
- 不需要对缓存进行磁盘存储。
文章目录
- 基于论文的Fast R-CNN学习
- 1.模型整体框架
- 2.模型细节
- 3.关键技术
- 3.1 RoI max Pooling
- 3.2 多任务损失函数
- 3.3 Truncated SVD
- 4.典型的训练及预测流程
- 4.1 训练过程
- 4.2 预测过程
- 5.用来加速、提高模型mAP的方法
- 5.1 加速
- 5.2 提高mAP
1.模型整体框架
- Regions of interest(RoIs)。通过Selective Search的方法,在原图上生成一系列大小不一,比例不一的Region proposal(建议窗口);
- 将RoIs和图片一起作为输入,输送进CNN;
- 图片通过CNN产生feature map,feature应该了通过padding保持size不变;
- 将每个RoIs作用在feature map上,并通过RoI最大池化产生固定size的feature vector;
- RoI feature vector经过两个fc后分别输入softmax进行分类和bbox regressor进行回归计算。
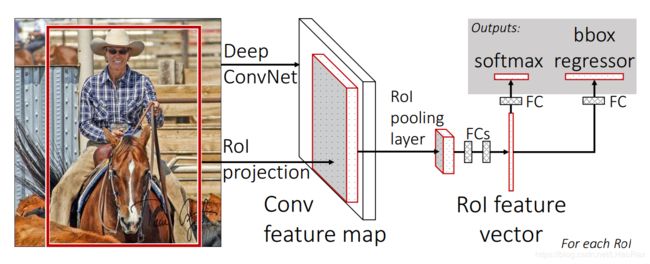
2.模型细节
- 模型相对于一个预训练的CNN网络做了3点的改变:
- 最后一个max pooling层改为RoI max pooling层;
- 最后一个fn层改为并行的softmax层和bbox regression层;
- 模型的输入从一个图片改为图片加RoIs的列表。
- 使用一个softmax分类器对K+1个类进行区分(K个物体类,1个背景类);使用bbox regressors对K个类的边框进行回归;
- 具体采样策略:
- 每个SGD的mini-batch是从2个图像中构建。如果mini-batch size=128,那么就从每个image中随机采样64个RoIs;
- 而这其中25%的RoIs为物体类,要求跟真实bbox的IoU大于0.5;
- 剩下的为背景类,要求IoU在**[0.1, 0.5)**的区间范围内。
- 数据增强。在模型中仅采用了0.5概率水平翻转的数据增强。
- SGD超参数设置:
- softmax和bbox regression的参数使用 zero-mean Gaussian distributions with standard deviations 0.01 and 0.001进行初始化;
- Bias初始化为0;
- weights的learning rate为1,biases的learning rate为2,global learning rate为0.001;
- 在30k个mini-batch iterations之后,后10k个iterations的global learning rate变为0.0001;
- 使用了0.9的momentum和0.0005的参数衰减(weights和biases都用了)。
- 这里再比较一下Fast R-CNN比R-CNN快的原因。如果同样构建一个size为128的mini-batch:对于R-CNN来说,需要128张图片,首先对他们都进行region proposals,在region proposals的过程中,由于来自不同的图片,这个过程参数肯定是不共享的。然后每个图片选择一个proposal,经过fixed size后产生size为128的mini-batch,再输入到CNN中,产生 feature map,这个feature map的shape为(128, C, H, W),C为filter数量;而对于Fast R-CNN来讲,由于采样策略的不同,需要2张图片,这两张图片会产生region proposals,每张图片内选择64个proposals,这个region proposals的过程中,由于64个proposals来自同一张图,所使用的参数共享,因此这个挑选64个proposals的过程会比从64张图片中各挑选1个proposals快64倍。同时,这两张图片输入CNN中产生feature map,此时feature map的shape为(2, C, H, W),然后feature map再结合每张图64个regions,形成size为128的mini-batch。可以看出,128形成的阶段不太相同,R-CNN在输入CNN前已经形成,它的128其实来自128个不同图片;而Fast R-CNN的128形成于RoI max pooling之前,它的128其实仅来自两个图片。
3.关键技术
3.1 RoI max Pooling
RoI池化的目的是将RoI产生固定尺寸 H × W H×W H×W的feature vector,H和W是两个超参数。
RoI池化的原理与max pooling的原理类似,其池化策略也同为最大值池化。不过只是相当于将输出固定,根据不同的RoI尺寸产生不一样的步长,形成相同数量的子窗口,在子窗口内求最大值。
论文中还讲了RoI max Pooling的反向传播算法,看了一下感觉代码写起来跟常用的max pooling的反向传播差不多。。。
3.2 多任务损失函数
Fast R-CNN包含两个并行的输出模块,损失函数结合这两个模块的输出进行计算。第一模块对应的是该RoI在K+1个类上的离散概率分布, p = ( p 0 , . . . , p K ) p=(p_0,...,p_K) p=(p0,...,pK)。第二个输出模块是对所有类都有的 t k = ( t x k , t y k , t w k , t h k ) t^k=(t^k_x,t^k_y,t^k_w,t^k_h) tk=(txk,tyk,twk,thk),意思就是不管你的真实类别是什么,每一个RoI都会产生一个包含K个类 t k t^k tk的集合,再通过 k = a r g m a x ( p 0 , . . . , p K ) k=argmax(p_0,...,p_K) k=argmax(p0,...,pK)来进行定位,然后根据定位后的来进行损失函数的计算。这里的 t t t跟在R-CNN论文里定义的相同。
对于每一个RoI,它的损失函数都可以由下式表述:
L ( p , u , t u , v ) = L c l s ( p , u ) + λ [ u ≥ 1 ] L l o c ( t u , v ) L(p,u,t^u,v)=L_{cls}(p,u)+\lambda[u\ge1]L_{loc}(t^u,v) L(p,u,tu,v)=Lcls(p,u)+λ[u≥1]Lloc(tu,v)
式中: p p p——RoI的概率分布; u u u——真实的label; t u t^u tu——对应真实类预测出的bbox变换; v v v真实的bbox变换,并将其进行了0均值和单位方差的normalize。
从公式中可以看出损失函数为两个模块的损失函数叠加。
第一个模块的损失函数就是softmax上定义的log损失:
L c l s ( p , u ) = − l o g p u L_{cls}(p,u)=-logp_u Lcls(p,u)=−logpu
第二个模块上的损失函数:
L l o c ( t u , v ) = Σ i ∈ { x , y , w , h } s m o o t h L 1 ( t i u − v i ) L_{loc}(t^u,v)=\Sigma_{i\in\{x,y,w,h\}}smooth_{L_1}(t_i^u-v_i) Lloc(tu,v)=Σi∈{x,y,w,h}smoothL1(tiu−vi)
式中:
s m o o t h L 1 ( x ) = { 0.5 x 2 if |x|<1 ∣ x ∣ − 0.5 otherwise smooth_{L_1}(x)=\left\{ \begin{array}{rcl} 0.5x^2 & \text{if |x|<1}\\ |x|-0.5 & \text{otherwise}\\ \end{array} \right. smoothL1(x)={0.5x2∣x∣−0.5if |x|<1otherwise
[ u ≥ 1 ] [u\ge1] [u≥1]表示当 u ≥ 1 u\ge1 u≥1时为1,其他为0。意思是只有当类别是物体类而不是背景类是才计算损失。
λ \lambda λ为超参数,用来控制两个任务损失之间的平衡。在论文中所有的 λ = 1 \lambda=1 λ=1。
3.3 Truncated SVD
对于目标检测问题,forward pass的时间主要消耗在fully connected layers上,对于大的全连接层,其参数众多,很容易使用SVD进行加速。
对于一个 u × v u×v u×v的权值矩阵W,可以将其分解为:
W ≈ U Σ t V T W\approx U\Sigma_tV^T W≈UΣtVT
通过使用truncated SVD,使得参数数量从 u × v u×v u×v减少到 t ( u + v ) t(u+v) t(u+v),只要t比 ( u , v ) (u,v) (u,v)的最小值更小,那么就能起到减少参数,从而加速训练的效果。
具体的操作是将原来的单一全连接层转化为两个全连接层,第一个全连接层的权值矩阵是 Σ t V T \Sigma_tV^T ΣtVT,该层没有biases;第二个全连接层的权值矩阵为 U U U,该层的biases跟W一致。
4.典型的训练及预测流程
4.1 训练过程
- 给图片产生proposals,并根据IoU为图片内的proposal打上label;
- 根据具体采样策略形成一个mini-batch,mini-batch中包含了来自不同图片的proposals;
- 将图片输入CNN,并经过conv layer层后产生feature map;
- feature map结合proposals并经过RoI池化后产生feature vector;
- 将vector送入softmax和regressors产生类的概率分布和所有类的边框回归预测;
- 结合label的正确类别信息计算multi-task损失函数;
- 进行反向传播。
4.2 预测过程
- 训练好的Fast R-CNN接收一个图像和包括R个proposals的列表。在测试阶段,R大约为2000;
- 对于每个RoI r,通过forward pass经过softmax产生一个概率分布p和一系列跟r相关的bbox 偏移量预测值(K个class的话,每个class都有自己的边框预测);
- 根据概率分布p的信息找到一系列bbox中对应预测类的偏移量,对边框位置进行调整;
- 根据每一个RoI的概率分布提出一个检测置信度, P r ( c l a s s = k ∣ r ) ≜ p k Pr(class=k|r)\triangleq p_k Pr(class=k∣r)≜pk;
- 对属于同一类的边框采取非极大抑制(NMS)减少冗余边框的数量,得到最后的边框。
5.用来加速、提高模型mAP的方法
5.1 加速
- 采用分层的采样策略。对于R-CNN和SPP,如果每个mini-batch的size是128,这128个RoI分别来自不同的image,这样会导致反向传播过程的训练速度受到影响;对于Fast R-CNN,采用了不同的采样策略,如果mini-batch size同为128,那么会有64个RoIs来自同一张图片,另外64个RoIs来自另一张图,并且来自同一张图片的RoIs在fp和bp过程中共享计算和存储,这样会使计算大大加快。
- 多任务损失函数。多任务损失函数的采用使得原本分为几个阶段(训练softmax,训练SVM,训练regressors)的过程合并。
- 采用SVD。通过Truncated SVD的使用能够显著降低全连接层消耗的时间,并且基本不会影响到mAP(仅降低0.3%)。在使用SVD之前,全连接层的消耗的时间占总时间的45%,使用SVD后,该部分由于参数减少,所消耗的时间显著降低。
5.2 提高mAP
- CNN网络。模型采用了三种预训练的ImageNet模型,其中最大最深的VGG16相较与其他两种模型有着普遍高的mAP。
- 增加额外数据。Fast R-CNN 在对VOC 12数据集进行训练时,加入07的trainval,可提高mAP。在增加数据量的同时,mini-batch iterations也随之增加。
- Fine-tuning the conv layers。对于conv layers的微调可以给mAP带来一个比较大的提升,但并不是对所有conv layer都有fine tune的必要,根据论文中的研究表明,对于VGG16,只有必要调整conv3_1以上的层。
- 训练时不加入难训练对象。训练时不对标记为“difficult”的对象进行训练,将这些对象从样本中移除可以使mAP上升一点。
- 分类模型的选择。使用softmax的整体效果要比one vs all的SVM要好;
- 改变proposal。在一定范围内提高proposals,但是效果很小,再增加甚至会影响mAP