4.3.1有监督学习(四) - BP神经网络(BP Neuron Networks)
简介
BP神经网络(Backpropagation Neuron Networks)又被称作多层感应机(Multi-layer Perceptrons)。BP神经网络通过设定隐藏层,能够在原有逻辑回归的基础上实现非线性的分割。神经网络在构建过程中,通过定义输入层、隐藏层与输出层,明确激活函数、损失函数,通过梯度递减法训练样本,最终实现分类器。
一句话解释版本:
神经网络由输入层、隐藏层、输出层构成,通过损失函数与梯度下降法拟合参数并建立模型。
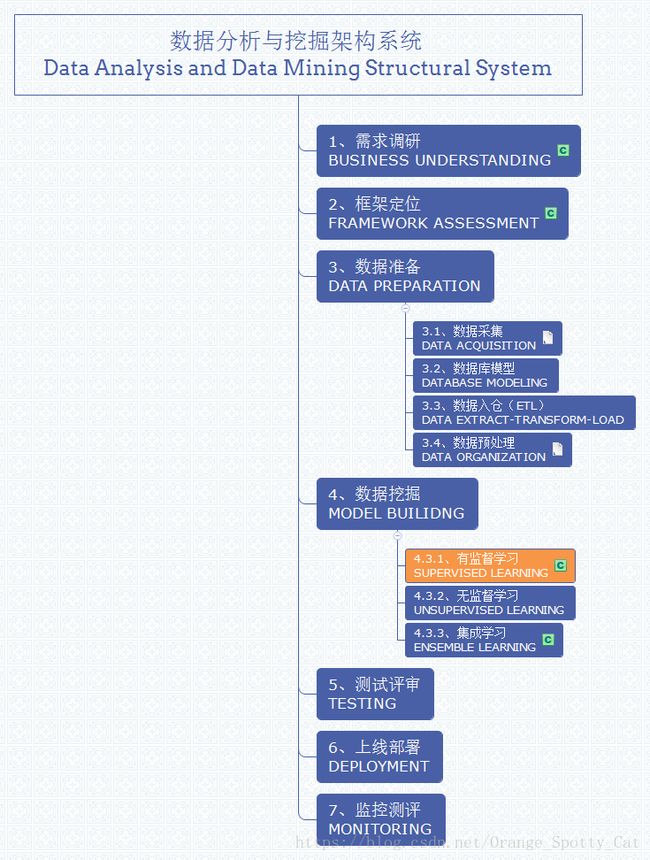
数据分析与挖掘体系位置
BP神经网络是有监督学习中的一种模型。所以在数据分析与数据挖掘中的位置如下图所示。
神经网络相关名词
神经网络中涉及的名词众多,所以我自己整理了一张表格,能够整理清楚这么多的专业词汇到底是为了做什么的。
| 名称 |
|
| BP神经网络 |
使用向后传播法进行参数估计得到的神经网络。 |
| 输入层,隐藏层,输出层 |
神经网络的组成部分 |
| 节点、神经元 |
输入层,隐藏层,输出层中的组成部分 |
| 神经健 |
连接各层的部分 |
|
|
|
| 激活函数 |
将数值进行转化的公式。 |
| 损失函数 |
确定参数值的公式 |
| 梯度递减法(SDG,MGD) |
确定参数值的方法 |
| 向前传播,向后传播 |
计算梯度的方法 |
BP神经网络的组成
BP神经网络一般由三部分构成:
- 输入层(Input Layer):接收自变量的数据层
- 隐藏层(Hidden Layer):负责增加计算能力,拟合模型的可多层。
- 输出层(Output Layer):进行决策,输出模型结果的决策层。
在每一层中,都有无数个神经元。在输入层,神经元就是自变量。在输出层,神经元就是Y的各种类别。因此在实际中,当数据与决策问题确定后,一般输入层与输出层就确定了。剩下可变的就是隐藏层的层数与每层的神经元数。
层与层之间的神经元是通过神经健(即,权重值)连接的。跨层的神经元之间没有连接,即输入层与输出层之间没有连接(除非没有隐藏层)。
BP神经网络的类型
依据BP神经网络的隐藏层与输出层的形式,其可以有如下四种较为常见的形式。
两层式单输出节点
- 输入层:自变量
- 隐藏层:无
- 输出层:一个节点
由于输出层(Y)只有一个节点,因此只能进行一种决策,结构最为简单。
这里说一句,这种没有隐藏层,Y是二分类的神经网络,分割就是线性的,与逻辑回归是一样的。
神经网络的架构如下图所示:

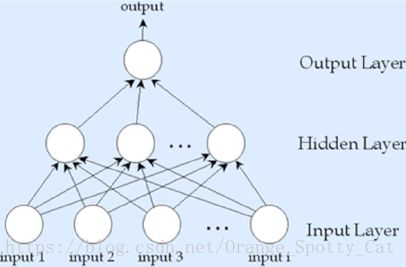
三层式单输出节点
- 输入层:自变量
- 隐藏层:一层
- 输出层:一个节点
拥有完整的输入层、隐藏层。但由于输出层(Y)只有一个节点,因此也只能进行一种决策。但是存在隐藏层,可以适用于较为复杂的决策问题,但是Y的决策结果只能有一个(如,二分类)。
神经网络的架构如下图所示:
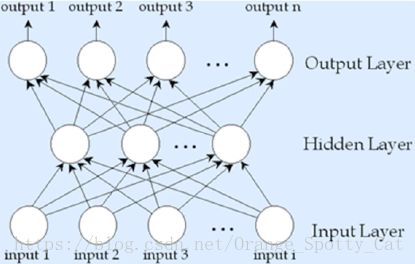
三层式多输出节点
- 输入层:自变量
- 隐藏层:一层
- 输出层:多个节点
拥有完整的输入层、隐藏层,且输出层(Y)有多个节点,支持多种决策。可以支持较为复杂的运算。
神经网络的架构如下图所示:
多层式多输出节点
- 输入层:自变量
- 隐藏层:多层
- 输出层:多个节点
相对最为复杂的神经网络形式。输入层一层,隐藏层依照需求的不同设定多层。输出层一层且多节点。能够支持复杂的运算与多决策结果判定。
BP神经网络的构建参数
BP神经网络的模型是Feedforward的,但是训练模型时是Train Backward。
模型的决策过程是:X自变量自输入层传入神经网络,通过带权重的神经健在隐藏层中依次传递,神经元最终接收到加权汇总值(weighted sum)并将这个汇总值与神经元的阈值做比较。最终通过激活函数(Active Function)产生决策结果,在输出层给出结果。
以图片表示就是,下图源自周志华《机器学习》:

在上图中,几个符号分别代表如下意思:
- x1,...,xn:输入数据。举之前“去不去玩”的例子的话,这里的x就可以为是否加班,是否双休日,天气等自变量数据。n就是自变量的个数。
- wij:权重值,可以理解为自变量的影响程度小。其对应某个x的绝对值越大,代表影响力越大。
-
θ:Bias,阈值。当x与w进行相乘加总后,得到的总数要与Bias相比较。得到输出。
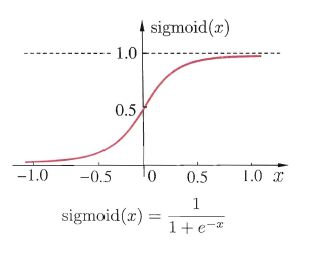
- f:激活函数。也被称位S型函数或转换函数,是能够把数据的值转换为0-1之间数值的function。一般最常见的就是Sigmoid函数。常见的激活函数公式为:
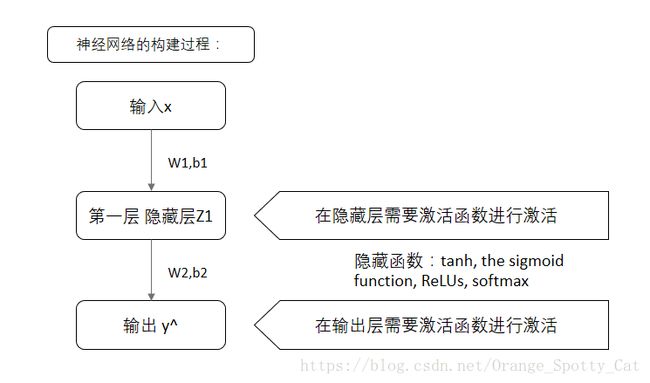
BP神经网络的构建过程
神经网络的构建步骤
下图是一个简单的BP神经网络的构建步骤:
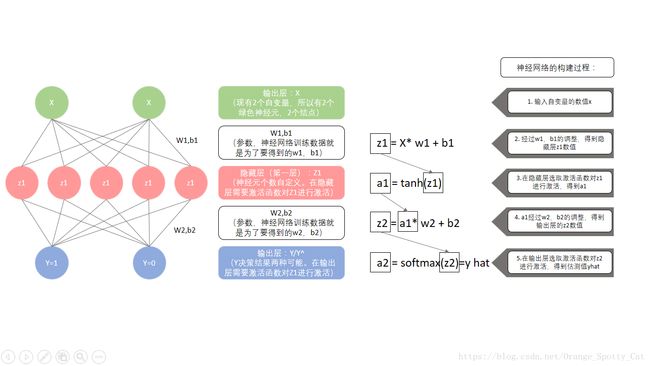
再转述一下就是:
神经网络的训练目标:损失函数最小化
从上面的公式与过程,可以发现,参数一共有:x,z,w,b,a,y^。而这之中,x是给定的,z,a,y^是通过公式求出来的。唯一不确定的就是w与b。这也就确定了神经网络的根本目的:
神经网络训练数据的目的,就是求出能让ERR最小的w1, w2, b1, b2的数值。
那么ERR,也就是误差是如何定义出来的呢?我们用损失函数(Loss Function)来定义。
如果Activate Function是softmax,一般会选择负对数似然(cross-entropy loss,交叉熵损失)来定义ERR。其公式为:

其中:
- N是训练样本的总数量
- x是样本
- y^是预测值
- y是真实值
Loss Function就是将每个样本的预测结果与真实值进行比较,算出差距,之后再加总。所以,预测值与真实值的差距越大,Loss Function的值就越大。
因此,神经网络就是在寻找合适的w1,w2,b1,b2值,使得计算出的Loss Function值最小化。
神经网络的训练方法:梯度递减法
那么,问题就变成了如何才能找到最合适的w与b的值。
这里最常用的方法是:梯度下降法(Gradient Descent)。我们常用的SGD(Stochastic Gradient Descent,随机梯度下降法),以及MGD(Minibatch Gradient Descent,最小批量梯度下降法)都是GD的延伸算法。
梯度下降法的原理可以简单归纳为:先是随机赋予w与b某个值,之后算法去看:如何改变w与b的值才能够让Loss Function更小一些。如果改变了w与b的值后,LF变小了,就往这个方向继续更改。这个过程不断迭代,知道往哪个方向改变w与b都不再让LF变得更小时,就停止迭代。并选取这时的w与b作为最合适的点。
我们可以想象,在一个地图中,有高山有盆地。我们随机把一个人放在这个地图中,告诉他,你给我找到地势最低的地方。这个时候,他就会看,我往哪里走会比之前的位置要低。我不断的走,知道不管往哪个方向迈一步,我都比以前在的位置要高。这个时候,我就确定我在最低点了。
GD的原理就与上面的过程有相通之处。GD需要对损失函数中各个参数求偏导数。这些偏导数,被称为梯度,而计算梯度的方法,有后向传播法(Backpropagation)与前向传播法(Forwardpropagation)。所以现在就明白了,BP神经网络,就是只用后向传播法进行参数估计得到的神经网络。
GD具体的流程,我可能需要单独一章来进行说明。这里,只需要知道,梯度下降是为了得到w与b的值。
BP神经网络在Python上的实现
代码好长,不想放这里占地方,请去Github下载吧。
https://github.com/starsfell/BP-NN