MonoGRNet: A Geometric Reasoning Network for Monocular 3D Object Localization
Abstract
利用RGB单张图片在真实3D场景进行目标定位由于图像投影过程几何信息的丢失变得相当困难,而这个工作在场景理解中有相当重要的作用。我们提出了通过观察到的2D投影与未观察到的深度维度进行几何推理,用于单目RGB图像三维定位的MonoGRNet算法。MonoGRNet是一个由四个特定子任务网络组成的单一统一的网络结构,四个子任务分别是2D目标检测,实例深度估计(IDE),3D定位与本地角点回归。与需要进行像素级别标注的像素级深度估计方法不同,我们提出的先进的IDE算法直接利用稀疏监督预测目标3Dbbox中心的深度。通过估计水平和垂直方向的位置,进一步实现了3D定位。最后,MonoGRNet利用全局上下文联合优化定位与3DBbox。结果展示MonoGRNet在挑战数据集上达到了SOTA的表现。
1、Introduction
典型的目标定位或者检测是从RGB图像中估计2Dbbox,将图像平面上特定类型的可见部分用2Dbbox框住。然而,这类的结果在场景理解的时候不能提供真实3D世界的几何认知信息,这对例如机器人,混合现实与自动驾驶来说有着十分迫切的需求。
本文我们解决从单目RGB图片中定位目标完整的模态3Dbbox(ABBox-3D)。与图像平面的2D分析相比,扩展到不可视区域的3D定位(例如深度),不仅扩大了搜索空间而且引入了固有2D到3D映射过程的不确定性,严重增加了任务的难度。
最SOTA的单目方法(Xu and Chen 2018; Zhuo et al. 2018)估计像素级别的深度然后进行3Dbbox的回归。然而像素级的深度预测用设计来说不是用于目标定位的。他的目标是使得所有像素的平均误差最小,从而得到整个图像的平均最优估计,而覆盖面积小的目标往往被忽略掉(Fu et al. 2018),这样大幅度的降低了3D检测的准确率。
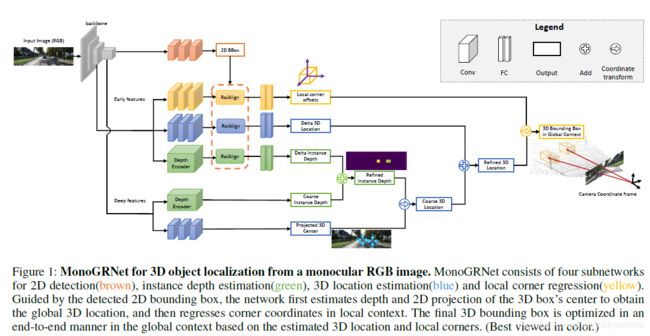
我们提出了MonoGRNet,一种从单目图片中进行模态3D目标定位的方法。这种方法的关键思想是将3D定位问题转换成数个先进的可以利用单目RGB数据解决的子任务。改网络从二维图片予以感知出发,实现3D空间的几何推理。
我们需要克服的一个很有挑战的问题是在不计算像素级深度的情况下,准确估计实例的三维中心深度。我们提出了一种全新的实例深度估计(IDE)模块,探索深度特征图的大感受野,将其与高分别率早期高分比率特征融合记性深度估计优化。
为了同时找到纵向与横向的位置,我们首先预测3D中心的2D投影。与IDE结合,我们将投影中心映射到3D空间,从而获得最终3D目标位置。所有组件都集成到一个端到端的网络MonoGRNet,它三个3D推理分支如图1所示,最终通过一个联合几何loss全局最小化3Dbbox的差值。
我们任务RGB信息足以用来进行精准的物体3D定位与姿态估计。在KITTI比赛数据集上的实验结果展示,我们的方法用了最少的推理时间超过了SOTA的3D单目方法的效果。总的来说,我们的贡献有三个方面:
- 提出一种先进的升读估计方法,无论遮挡与截断直接在缺少深度信息的前提下预测目标的ABBox-3D中心的深度。
- 提出一种先进的3D定位结构,二维图像的丰富特征表达与扩展到3D几何信息推理。
- 提出了一种在2D,2.5D,3D空间联合优化的目标左边定位的统一网络,具有高效推理性能(0.06s/张样本)。
2、Related Work
我们的工作与3D目标检测与单目深度估计相关。我们主要专注于3D检测与深度估计的研究,将2D检测作为连贯性基础。
2D目标检测。2D目标检测深度网络已经被广泛研究。基于RPN的方法(Girshick 2015; Ren et al. 2017)可以得到很好的效果,但是由于复杂的多步结构推理速度很慢。另外一类方法(Redmon et al. 2016;Redmon and Farhadi 2017; Liu et al. 2016; Fu et al. 2017)专注于快速使用一个一部检测结构进行快速训练与测试。Multi-net(Teichmann et al. 2016)引入了一种encoder-decoder结构进行实施语义推理。这个检测解码器结合了YOLO(Redmon et al. 2016)的快速回归器与Mask-RCNN(He et al. 2017)的size-adjusting RoiAlign,取得了不错的速度准确率比率均衡。所有这些方法预测目标的2Dbbox而不考虑任何3D几何特征。
3D目标检测。现有的方法包括单目RGB方法(Chen et al. 2016; Xu and Chen 2018; Chabot et al. 2017; Kehl et al. 2017),多视角RGB方法(Chen et al. 2017; Chen et al. 2015; Wang et al.),与基于RGB-D的方法(Qi et al. 2017; Song and Xiao 2016; Liu et al. 2015; Zhang et al. 2014)。如果提供了深度维度的几何信息,那么3D检测会变得简单的多。使用RGB-D数据,FPointNet(Qi et al. 2017)将2D中region proposal的方式扩展到截面的3D视角,在点云中分割出感兴趣的目标。MV3D(Chen et al. 2017)在LIDAR点云的鸟瞰图上进行3D目标的proposal,在RGB图片、LIDAR前向图、与鸟瞰图上复用这些特征进行3Dbbox的预测。3DOP(Chen et al. 2015)使用用于自动驾驶的立体信息与上下文模型。
与我们的方法最相关的是单目RGB图像的方法。深度维度中信息的丢失显著增加了任务的难度。这些方法的STOA与RGB-D或者多视角的方法相比任有很大的差距。Mono3D(Chen et al. 2016)使用语义分割与上下文先验知识来产生3D proposal。这种方法需要额外的网络进行语义与实力分割,这使得训练与推理的时间花费更多。Xu et al.(Xu and Chen 2018)利用预训练的视差估计模型(Mahjourian, Wicke,and Angelova 2018)引导几何信息推理。其他的方法(Chabot et al. 2017; Kehl et al. 2017)利用3DCAD模型产生训练的模拟数据,提供了用于监督的目标的3D模板,目标姿态与相应的2D投影。所有之前的方法利用额外数据与网络促进3D感知,而我们的方法仅需要3Dbbox标注,不需要任何其他网络。这使得我们的网络在训练与测试时更轻量级并且更高效。
单目深度估计。这些年来,尽管许多像素级的深度估计网络(Fu et al. 2018; Eigen and Fergus 2015)被提了出来,他们对于3D目标定位来说并不够。当进行像素级的深度回归时,loss函数将深度图的每个像素都进行权衡并且对他们进行无差别对待。通常情况下,每个像素的loss值最后被加起来一起进行优化。然而,有一种可能是,位于目标中的像素比位于背景中的像素要少得多。因此,较低的平均误差并不表示在目标中像素的深度值是准确的。此外,密集深度的估计往往来自视差图,这可能会在较远区域产生较大的误差,这会大大降低三维定位的性能。
与上述像素级深度估计方法不同,我们首先提出的一种基于稀疏监督的联合语义信息与几何特征的实例级深度估计方法。
3、Approach
我们提出了端到端的MonoGRNet,直接从单张RGB图片中预测ABBox-3D。MonoGRNet包括一个2D检测模块与三个用于几何信息推理模块,IDE,3D定位,与ABBox-3D回归。本节中,我们首先正式定义3D定位问题,然后详细介绍MonGRNet四个子网络。
问题定义
通过一张给定的单目RGB图像,目标是在3D空间定位指定类型目标的位置。目标物体有一个类标签与ABBox3D组成,无论是截断还是遮挡情况都包围住整个目标。一个ABBox-3D是由全局3D中心点![]() 与8个局部角点相关顶点
与8个局部角点相关顶点![]() 定义的。三维位置C在摄像机坐标系中标定,局部角点O在局部坐标系中标定,分别如图2(b)与(c)所示。
定义的。三维位置C在摄像机坐标系中标定,局部角点O在局部坐标系中标定,分别如图2(b)与(c)所示。
我们提出将3D定位任务分解称为四个可以只用一张单目图片解决的任务。首先,检测ABBox-3D投影的2Dbbox ![]() ,中心点为b,大小为(w,h)。之后,通过预测3Dbbox中心点C的深度
,中心点为b,大小为(w,h)。之后,通过预测3Dbbox中心点C的深度![]() 与2D投影c实现C的定位。符号在图2中展示。最后,基于局部特征根据3D中心回归出本地角点O。总的来说,我们通过估计每个感兴趣目标下列参数来表达ABBox-3d定位:
与2D投影c实现C的定位。符号在图2中展示。最后,基于局部特征根据3D中心回归出本地角点O。总的来说,我们通过估计每个感兴趣目标下列参数来表达ABBox-3d定位:
![]()
Monocular Geometric Reasoning Network
MonoGRNet设计用来估计是个组建,四个子网络分别对应![]() ,
,![]() 。在同一个CNN骨架结构下,他们合并到一个统一框架下,见图1。
。在同一个CNN骨架结构下,他们合并到一个统一框架下,见图1。
2D Detection。2D检测模块是稳定特征学习的基本模块,同事也是回叙几何推理模块的感兴趣区域。
我们使用(Teichmann et al. 2016)中的检测组建设计,将快速回归(Redmon et al. 2016)与尺度自适应RoiAlign(He et al. 2017)相结合,达到速度与准确率合理的均衡。一个大小为W×H的输入样本I分解成![]() 个方格
个方格![]() ,这里一个各自表示为g。与图像网格单元对应的特征图中每个像素产生一个预测。每个单元格g的2D预测包括感兴趣区域是否存在目标的置信度与该目标的2Dbbox,也就是说,
,这里一个各自表示为g。与图像网格单元对应的特征图中每个像素产生一个预测。每个单元格g的2D预测包括感兴趣区域是否存在目标的置信度与该目标的2Dbbox,也就是说,![]() ,表示为上标g。2Dbbox
,表示为上标g。2Dbbox ![]() 通过中心b到g偏置
通过中心b到g偏置![]() 与2D框的大小(w,h)。
与2D框的大小(w,h)。
预测的2Dbbox利用RoiAlign(He et al. 2017)层提取高分辨率的早期特征作为输入,来优化预测结果,优化快速检测器与基于proposal检测器效果间的差异。
Instance-Level Depth Estimation。IDE子网络预测ABBox-3D中心点![]() 的深度。从骨干网络的特征图中得到分好的网格
的深度。从骨干网络的特征图中得到分好的网格![]() ,每个网格g预测以阈值
,每个网格g预测以阈值![]() 预测最近实例的3D中心的深度,考虑到深度信息,例如为更近的实例分配了网格,如图3(a)所示。一个单元格预测深度的示例如图3(c)所示。
预测最近实例的3D中心的深度,考虑到深度信息,例如为更近的实例分配了网格,如图3(a)所示。一个单元格预测深度的示例如图3(c)所示。
IDE模块由一个不考虑尺度与特定目标2D位置的区域深度的粗回归与一个细化的阶段依靠2Dbbox在目标覆盖的区域提取编码的深度特征,如图4所示。
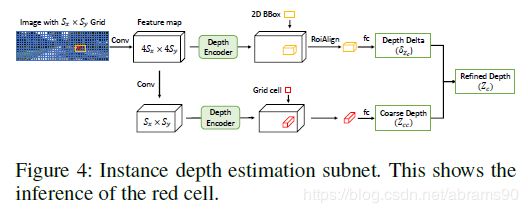
与浅层网络相比,CNN骨干网络得到的深度特征图中的网格有更大的感受野与更低的分辨率。因为他们对目标物体确切位置不那么敏感,可以从深度层回归大致深度偏置![]() 。给定检测到的2Dbbox,我们可以对早期特征图中包含实例的区域用更高的分辨率与更小的感受野进行RoiAlign。校准特征通过全连接网络回归
。给定检测到的2Dbbox,我们可以对早期特征图中包含实例的区域用更高的分辨率与更小的感受野进行RoiAlign。校准特征通过全连接网络回归![]() 从而优化实例级深度值。最终的预测值是
从而优化实例级深度值。最终的预测值是![]() 。
。
Loss Funtions
这里我们正式以公式的形式表述上述子网络四个任务的loss,并形成一个统一的联合loss。所有预测呗修改的都有一个上标g对应网格g。真实值的结果通过标致![]() 修改。
修改。
2D Detection Loss。目标的置信度使用softmax交叉熵loss进行训练,2Dbbox ![]() 通过带掩模的L1距离loss回归得到。注意w与h通过W与H进行正则化。那么2D检测loss定义如下:
通过带掩模的L1距离loss回归得到。注意w与h通过W与H进行正则化。那么2D检测loss定义如下:

这里![]() 分别表示预测的与真实的置信度,
分别表示预测的与真实的置信度,![]() 表示L1距离
表示L1距离![]() 屏蔽未包含任何物体的网络。每个网格g的掩模函数
屏蔽未包含任何物体的网络。每个网格g的掩模函数![]() 如果g b小于
如果g b小于![]() 则设置为1,否则设置为0.这两个部分通过
则设置为1,否则设置为0.这两个部分通过![]() 做均衡。
做均衡。
Instance Depth Loss。这是一个用于实例深度的L1 Loss:
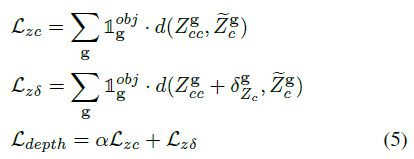
这里α>1,使得网络受限学习大致深度然后再学习精确的。
3D定位Loss。这个loss将2D投影与3D定位的L1loss相加:
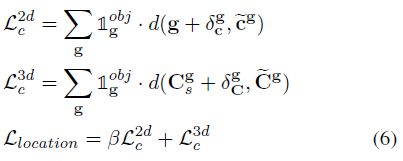
这里β>1,使得首先学习投影中心,然后细化最终的3D预测。
Local Corner Loss。这个loss是所有角点L1 loss之和:
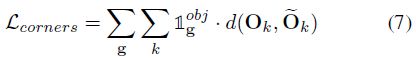
Joint 3D Loss。注意以上所有的损失函数,我们将单目3D检测任务分解成数个子任务,分别回归出3Dbbox的不同组件。然而,预测需要是一个整体,需要在不同部分构建一定的联系。我们将联合3Dloss作为摄像机坐标系中角点坐标距离之和:
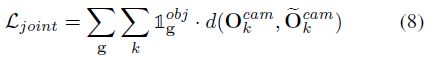
Implementation Details
Network Setup。MonoGRNet网络结构如图1所示。我们选择VGG-16(Matthew and Rob 2014)作为骨干网络,去除其中的FC层。我们将KittiBox(Teichmann et al. 2016)用于快速2D检测,插入缓冲区将3D推理分支2D检测器分离。在IDE模块中,为了同时获取局部与全局特征,集成了一个类似DORN(Fu et al. 2018)的深度编码结构。详细的每一层设置在补充材料中描述。总共有46个权重层,最深的路径只有20个权重层(例如从输入到IDE输出),由于平行的3D推理分支。在我们的设计中,所有的3D与2D模块有770万参数,是包含全连接层原始VGG-16的6.2%。
Training。VGG-16主干网络是在ImageNet上进行权重预训练的。在损失函数中,我们设置![]() 。模型参数引用L2正则化,学习率为
。模型参数引用L2正则化,学习率为![]() 。我们收下利用骨干网络独立训练2D检测器,使用Adam optimizer(Kingma and Ba 2015)迭代120K次。之后是3D推理模块,IDE,3D定位与局部角点定位,利用Adam optimizer训练80K次迭代。最后,我们使用SGD利用端到端方式进行40K次迭代优化整个网络。Batchsize设置成5,训练期间学习率始终设置为
。我们收下利用骨干网络独立训练2D检测器,使用Adam optimizer(Kingma and Ba 2015)迭代120K次。之后是3D推理模块,IDE,3D定位与局部角点定位,利用Adam optimizer训练80K次迭代。最后,我们使用SGD利用端到端方式进行40K次迭代优化整个网络。Batchsize设置成5,训练期间学习率始终设置为![]() 。模型利用单GPU NVIDIA P40训练。
。模型利用单GPU NVIDIA P40训练。
4、Experiment
我们在KITTI挑战集上(Geiger, Lenz, and Urtasun 2012)评估我们提出的网络,数据集包含7481张训练样本与7518张测试数据,包含相机的标定参数。检测以三个维度进行评估:easy,moderate与hard,根据遮挡与截断的程度。我们将我们的算法与SOTA的3D单目检测方对比,包括MF3D (Xu and Chen 2018)与Mono3D(Chen et al. 2016)。我们还将基于立体视觉的3DOP(Chen et al. 2015)作为对比。为了进行公平的对比,我们依据(Chen et al. 2016;Chen et al. 2017)中训练集与验证集的分割方式,每个子集包含半数的图片。
Metrics。为了评估三维定位的性能,我们使用预测的预测3Dbbox与GTbbox中心位置之间的平均误差作为度量指标。对于3D检测表现,我们依据不用IOU阈值KITTIbenchmark的官方设定来评估3D平准准确率(![]() )。
)。
3D Localization Estimation。我们根据目标物体与相机中心之间的距离来评估三维定位误差(水平、垂直与深度)。距离分成10米间隔。误差计算为预测的三维位置与其最近的GT之间的米级平均误差。结果在图5中展示。误差,特别是深度维度的误差,随着距离增加而增加,因为代表小尺度的较远目标更难学习。
结果证明,我们的方法(红色曲线)比Mono3D表现好得多,比需要立体图像输入的3DOP方法也要好。另外一个发现是,整体来说,我们的模型对具体更不敏感。当目标距离相机源于30米或者更远,我们的表现最稳定,这就说明我们方法对远目标处理更好(包括小图像区域)。
有趣的是,水平与垂直误差由于数量级的原因比深度的更小,例如深度误差主导了整体的定位误差。这是合理的,因为深度维度没有直接观察到二维图像而是从几何特征进行推理。本文提出的IDE模块性能在easy与moderate数据集表现更好,在hard集合上与立体视觉上效果类似。

3D目标检测。3D目标检测通过在车辆类别上应用0.3,0.4,0.5的3DIoU阈值的![]() 进行评估。我们将表现与两种单目方法Mono3D与MF3D进行对比。结果在表1中展示。由于MF3D的作者并没有公布他们的评估结果,我们仅报告了他们论文里
进行评估。我们将表现与两种单目方法Mono3D与MF3D进行对比。结果在表1中展示。由于MF3D的作者并没有公布他们的评估结果,我们仅报告了他们论文里![]() 在0.5与0.7时的结果。结果显示我们的方法在所有SOTA单目检测器中表现更好,可以与基于立体视觉的方法效果相当。
在0.5与0.7时的结果。结果显示我们的方法在所有SOTA单目检测器中表现更好,可以与基于立体视觉的方法效果相当。
我们的网络设计用来高效应用,使用了一个不带有rpn的2D目标检测器。在Geforce GTX TitanX上每张图片前向时间为约0.06ms,比其它三种方法要快得多。换句话说,这样的设计某种程度上牺牲了2D目标检测器的速度。我们2D检测器在moderate集上的在0.7Iou阈值上的准确率是78.14%,比基于提出大量候选区域尽量覆盖GT的RPN方法低了近10%。比起使用相对较弱的2D检测器,我们3D检测器取得了SOTA的表现,依靠我们的IDE与3D定位模块。注意到2d目标检测器在我们的框架中是可以替换的子模块,并不是我们的主要贡献点。
Local 3D Bounding Box Regression。我们从本地3Dbbox大小(高,宽,长)与朝向层面评估回归算法。3Dbbox的长宽高可以很容易的根据8个角点计算出来。朝向是通过相机坐标系中的偏角度量实现的。我们的均值展示如表2。我们提出的网络在仅用光学特征定位3Dbbox上展示出了更好的能力。值得注意的是,在RoiAlign层后的角点回归模块中,所有感兴趣目标被resize成一样的大小,然而网络任然学习他们实际的3D大小。这是因为我们的网络提取包含目标真实类型(SUV通常比其它车辆大)投影几何与语义分割信息来获得大小与朝向的估计。

Qualitative Result。定性可视化分析在三种典型场景下提供,如图6。在通常的街景场景下,我们的预测通常可以成功召回目标。可以观察到,尽管车辆被图像的边界严重的截断,我们的网络依然可以精准的预测3Dbbox。在自动驾驶场景下,鲁棒性对于避免与横向物体碰撞非常重要。对于车辆被其它车辆严重遮挡的情景,例如(g)(h)(i),我们的3D检测器可以处理可见的车辆,对于不可见的车辆检测失败。事实上,这是从单目RGB图像中进行感知的常见问题,可以通过配合3D数据或者多视角数据获得更多提供有效信息的3D几何细节。
Ablation Study
定位3D中心C的重要步骤是定位2D投影c,由于c与C在分析上是相关的。尽管2Dbbox中心b可能与c相近,如图2(a)中所示,但它并没有3D的意义。当我们在3D推理时,用b替代c,水平定位误差从0.27m上升到0.35m,垂直误差从0.09m上升到0.69m。此外,当目标被图像的边界截断的时候,它的投影c可能在图像的边界外面,而b总是在内部。因此,使用b进行3D定位可能导致严重的偏差。因此,我们用于定位投影3D中心的子网络是不可或缺的。
为了检验局部角点回归前坐标变换的影响,我们直接在不旋转坐标轴的前提下回归角点的offset。结果显示平均弧度误差从0.251上升到0.442,而3Dbbox高度、宽度与长度的误差基本保持不变。这一现象与我们的分析一致,转换到物体坐标可以减少投影引起的旋转不确定性,因此可以进行更精确的3Dbbox估计。
5、Conclusion
本文我们提出了用于单目图片3D目标定位的MonoGRNet,在3D检测,定位与姿态估计方面得到了比SOTA更好的结果。提出了先进的IDE模块进行实例级深度预测,避免了花费额外计算在像素级深度预测上,无论目标与相机之间的距离是多少。与此同时,我们为3D定位中的更好几何信息推理,区分了2Dbbox与3Dbbox的中心。目标姿态估计是通过在局部坐标系上角点坐标的回归实现的,这样减少了透视变换中三维旋转的不确定性。最后用一个统一的网络集成了各个组件,进行高效的前向运算。