目标检测(object detection)系列(八)YOLOv2:更好,更快,更强
目标检测系列:
目标检测(object detection)系列(一) R-CNN:CNN目标检测的开山之作
目标检测(object detection)系列(二) SPP-Net:让卷积计算可以共享
目标检测(object detection)系列(三) Fast R-CNN:end-to-end的愉快训练
目标检测(object detection)系列(四) Faster R-CNN:有RPN的Fast R-CNN
目标检测(object detection)系列(五) YOLO:目标检测的另一种打开方式
目标检测(object detection)系列(六) SSD:兼顾效率和准确性
目标检测(object detection)系列(七) R-FCN:位置敏感的Faster R-CNN
目标检测(object detection)系列(八) YOLOv2:更好,更快,更强
目标检测(object detection)系列(九) YOLOv3:取百家所长成一家之言
目标检测(object detection)系列(十) FPN:用特征金字塔引入多尺度
目标检测(object detection)系列(十一) RetinaNet:one-stage检测器巅峰之作
目标检测(object detection)系列(十二) CornerNet:anchor free的开端
目标检测扩展系列:
目标检测(object detection)扩展系列(一) Selective Search:选择性搜索算法
目标检测(object detection)扩展系列(二) OHEM:在线难例挖掘
简介:更好,更快,更强
YOLO系列推出了它的第二代算法:YOLOv2,一个“更好,更快,更强”的检测器。╮( ̄▽  ̄)╭
YOLOv2的论文是《YOLO9000: Better, Faster, Stronger》,这里面的YOLO9000是YOLO2的基础上做了,使用检测与分类的联合训练,并根据ImageNet中的WordNet构建WordTree,达到9000类目标检测的目的,但是这部分内容在下面不做介绍了。YOLOv2同样延续了one-stage检测的思路,并在速度和准确性方面都超过了SSD。
YOLOv2原理
设计理念
一提到YOLOv2对YOLO的改进,一般都会有下面这个图:

但是它更多的是一种trick,比如用更大分辨率的图训练基础分类模型等等,这个东西我们后面再说,个人认为YOLOv2相比于YOLO主要在四个方面有比较大的改进:
- 首先就是主干网络结构,YOLO2v提出之前,已经涌现了一大批的优秀的图像分类网络,比如ResNet、Inception等,所以YOLOv2没必要再继续使用VGG16,当然它也没用现有的结构,而是自行设计了一个DarkNet-19;
- 其次,是anchor box的引入,在Faster R-CNN和SSD之后,YOLOv2也终于加入了anchor box;
- 随后,YOLOv2的每一个box都会输出全套的置信度信息,而不是像YOLO那样只有location信息;
- 最后,YOLOv2也引入了多层特征的概念,虽然它没像SSD一样拉取多个分支,但是使用了一种“reorg”操作,起到相似的效果。
网络结构
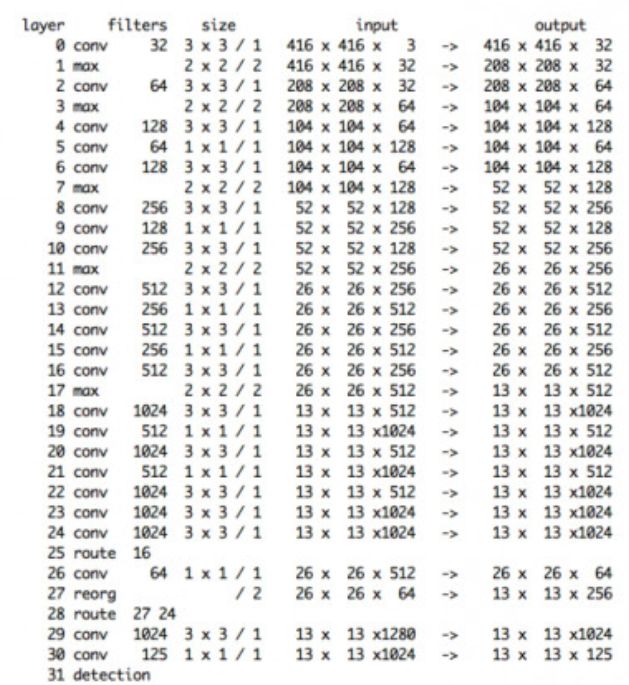
上图是YOLOv2的主干网络结构,可以看到YOLOv2有32层。结构还是比较常规的,主要就是在用 3 × 3 3\times3 3×3的卷积, 2 × 2 2\times2 2×2的池化和 1 × 1 1\times1 1×1的卷积。除了上面三个常规操作外,还有reorg和route,其中route在25层和28层,reorg在27层。
- route:
route层是串接的意思,比如28层的route把27层和24层串接到一起输出到下一层,第27层的输出是 13 × 13 × 256 13\times13\times256 13×13×256,24层输出是 13 × 13 × 1024 13\times13\times1024 13×13×1024,所以在第三个维度上做拼接就是28层的输出,同样也是29层的输入: 13 × 13 × 1280 13\times13\times1280 13×13×1280。
同理,第24层route只有16,那么就不做合并了,直接把16层的输出拿过来作为24层输出: 26 × 26 × 512 26\times26\times512 26×26×512,所以25层的输入是 26 × 26 × 512 26\times26\times512 26×26×512。 - reorg:
reorg是一种reshape,但是reshape的方式很新奇,它将 26 × 26 × 64 26\times26\times64 26×26×64 的输出形变为 13 × 13 × 256 13\times13\times256 13×13×256 ,因为 26 × 26 × 1 26\times26\times1 26×26×1可以变为 13 × 13 × 4 13\times13\times4 13×13×4,reorg其实是为了28层的route服务的,因为只有特征图的宽高时一致的,才能做串接。
YOLO2的主干网络的连接方式可以看下面这个图:
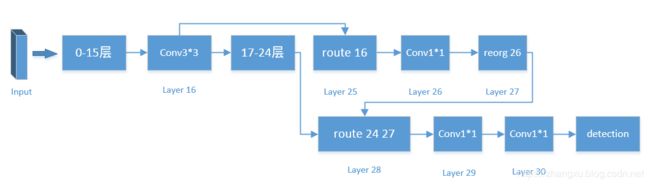
经过一系列的操作,YOLOv2最后输出特征图是 13 × 13 × 125 13\times13\times125 13×13×125,主干网络的部分就结束。
那么这里就有两个问题,为什么最后的输出是 13 × 13 × 125 13\times13\times125 13×13×125?为什么主干网络要做成这么个奇奇怪怪的样子,而不是顺序的一次性下来?
- 输出维度是 13 × 13 × 125 13\times13\times125 13×13×125
这个数的组合和YOLO其实是很相似的,不同的地方也是YOLOv2比较关键的地方。首先是我们应该注意的一个地方是YOLOv2没有全连接层了,最后一层也不是reshape出来的,而是直接卷积得到的,这个就已经SSD很像了。其次 13 × 13 13\times13 13×13是最后一层特征图的宽高,相比YOLO的 7 × 7 7\times7 7×7,这个图变大了,也就有了更丰富的信息。最后,也是最关键的地方,就是这个125,YOLO这个值可是只有30啊,同样是做20个类别的目标检测,YOLOv2就把它变大了这么多,都是用来干嘛了呢?125指的是 25 × 5 25\times5 25×5,其中的5指的是5个bbox框,在YOLO中这个数是2,但是在YOLOv2里它变成了5。
还剩最后一个数字:25,这是和要检测类别数量有关系,它包含了类别的置信度,边界框的位置以及是否有物体这些信息。YOLOv2在预测20类(VOC数据集),所以类别的置信度有20个,对应的某个bbox框中是某一个class的概率;边框的位置用 { d x , d y , d w , d h } \left \{ d_{x}, d_{y},d_{w},d_{h} \right \} {dx,dy,dw,dh}这4个数会被用来计算和大小;此外还有一个值表示边框预测里有真正的对象的概率confidence。所以最终25的排布是 20 + 4 + 1 20+4+1 20+4+1。
那么YOLOv2的计算就应该是: 125 = 5 × ( 20 + 4 + 1 ) 125=5\times\left(20+4+1\right) 125=5×(20+4+1)
而YOLO的计算是: 30 = 20 + 2 × ( 4 + 1 ) 30=20+2\times\left(4+1\right) 30=20+2×(4+1)

这就是YOLOv2的关键了,类别的信息不再和框没有关系,而是像SSD那样,YOLOv2的每个框都有全套的输出。
另一方面,YOLO最终总共只有49个类别结果和98个预测框,而YOLOv2有845个,多了很多。 - 主干网络有跨层合并
YOLOv2的最后一层特征图尺寸是 13 × 13 × 125 13\times13\times125 13×13×125, 13 × 13 13\times13 13×13的尺寸足够检测到常规目标了,但是对于小目标还是比较吃力,而小目标用更大的更靠前的特征图,就有可能检测到了,所以这种奇怪的连接方法本质上就是在拉取更靠前的特征图,也就是第16层的输出,虽然这个 26 × 26 × 64 26\times26\times64 26×26×64 的特征图又被reshape小了,但是没关系啊,提出来的特征还是那些东西。 这个操作其实和SSD中的多层特征分支输出的操作作用相似
通过上面两个操作,很像吐槽一下CNN结构设计╮( ̄▽  ̄)╭,我们在做网络结构分析或网络结构设计的时候,经常会有这样的感觉,输出的数想让它代表什么就代表什么,网络结构想怎么拉分支就怎么拉分支,维度不匹配就用 1 × 1 1\times1 1×1卷积和reshape,有时候甚至看起来很没有道理,但是最后这样的操作却能有效果,最重要的原因就在于卷积操作是只是在做特征提取,它只是很强的抽取能力,但是它并不知道会抽取出什么东西,所以如果我们设计合适的损失函数,就可以任意指定输出,哪怕这种指定看起来并没有道理。CNN本质上就是连接input与output之间的一个极其复杂的,表达能力很强的,并且很有潜力的函数,但是这个函数最终的能力能不能充分发挥出来,要取决于很多东西,损失函数,训练技巧,数据集等等。
YOLOv2的anchor box
到这里,第一部分提到的四个点,就解释完了三个,还剩下一个archor box。
在SSD和Faster R-CNN中,要预测的边界框中心坐标 ( t x , t y ) (t_{x}, t_{y}) (tx,ty)实际上是一个offset,它表示了预设框与ground truth的偏差,ground truth的中心点是 ( x , y ) (x, y) (x,y),预设框表示为 { x a , y a , w a , h a } \left \{ x_{a}, y_{a},w_{a},h_{a} \right \} {xa,ya,wa,ha},那么 ( t x , t y ) (t_{x}, t_{y}) (tx,ty)可以被计算为:
t x = x − x a w a t_{x}= \frac {x-x_{a}}{w_{a}} tx=wax−xa t y = y − y a h a t_{y}= \frac {y-y_{a}}{h_{a}} ty=hay−ya
这个公式变换一下,当然加减符号不太重要,所以移项之后不变号了:
x = t x w a − x a x= t_{x}w_{a}-x_{a} x=txwa−xa y = t y h a − y a y=t_{y}h_{a}-y_{a} y=tyha−ya
这样来看的话,offset ( t x , t y ) (t_{x}, t_{y}) (tx,ty)有各自的系数 w a w_{a} wa和 h a h_{a} ha,又因为offset是无约束的,offset变化了一个单位,预测值值就要偏离实际值 w a w_{a} wa和 h a h_{a} ha这么多,这会造成优化的困难。为了避免这个问题,YOLOv2在边界框预测上还是沿用YOLO的策略,而没有使用SSD的。
就是预测边界框中心点相对于对应cell左上角位置的相对偏移值,为了将边界框中心点约束在当前cell中,使用sigmoid函数处理偏移值,这样预测的偏移值在(0,1)范围内(每个cell的尺度看做1)。总结来看,根据边界框预测的4个offset { t x , t y , t w , t h } \left \{ t_{x}, t_{y},t_{w},t_{h} \right \} {tx,ty,tw,th},可以按照下列公式计算出ground truth在特征图上的相对值 { b x , b y , b w , b h } \left \{ b_{x}, b_{y},b_{w},b_{h} \right \} {bx,by,bw,bh},注意这个是ground truth在特征图上的相对值,不是 ( x , y , w , h ) (x, y,w,h) (x,y,w,h)。
b x = σ ( t x ) + c x b_{x}= \sigma(t_{x})+c_{x} bx=σ(tx)+cx b y = σ ( t y ) + c y b_{y}= \sigma(t_{y})+c_{y} by=σ(ty)+cy b w = p w e t w b_{w}= p_{w}e^{t_{w}} bw=pwetw b h = p h e t h b_{h}= p_{h}e^{t_{h}} bh=pheth
具体的如下图:
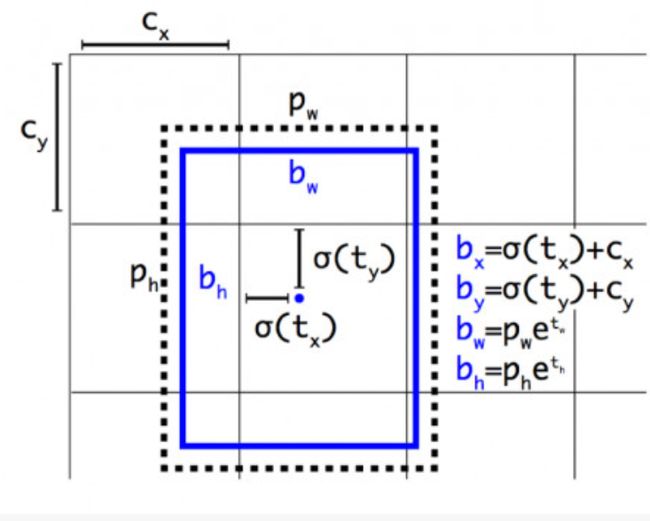
c x c_{x} cx和 c y c_{y} cy是特征图中格子的左上角坐标,这样一来,要预测的 b x b_{x} bx和 b y b_{y} by就被限定到了一个格子里,而 t x t_{x} tx和 t y t_{y} ty被限定到了 ( 0 , 1 ) (0,1) (0,1),所以回归方法去处理这个问题时更加容易。然后还剩下 p w p_{w} pw和 p h p_{h} ph,这两个东西就是YOLOv2的archor。这样ground truth就又被archor重新编码了,只是编码的方式和SSD不同。
YOLOv2在决定anchor的取值的时候,是根据要预测的数据集来的,它事先统计了VOC中的boundingbox的长宽分布情况,选择了5对比较合适anchor,这种统计的方式在论文里称为Dimension Clusters(维度聚类),其实就是个K-means,以聚类个数k为anchor boxs个数,以k个聚类中心box的宽高维度为anchor box的维度。但是使用标准的K-means有一个问题,那就是大的bbox会比小的bbox产生更大的error,哪怕他们离实际的聚类中心更近,所以为了解决这个问题,维度聚类重新设计了距离评价:
d ( b o x , c e n t r o i d ) = 1 − I O U ( b o x , c e n t r o i d ) d\left(box,centroid\right)=1-IOU\left(box,centroid\right) d(box,centroid)=1−IOU(box,centroid)
经过K-means预测之后,它们分别是:
( 1.32210 , 1.73145 ) (1.32210,1.73145) (1.32210,1.73145)
( 3.19275 , 4.00944 ) (3.19275,4.00944) (3.19275,4.00944)
( 5.00587 , 8.09892 ) (5.00587,8.09892) (5.00587,8.09892)
( 9.47112 , 4.84053 ) (9.47112,4.84053) (9.47112,4.84053)
( 11.2364 , 10.0071 ) (11.2364,10.0071) (11.2364,10.0071)
最后这个在特征图上计算出来的bbox是要向原图上映射的,这就是一个对应比例的坐标变换。
YOLOv2阈值与分类
YOLOv2最后会对20个class都打分,显然分值最高的那个,就是最后的这个建议框的类别,并拿出该类别的probability。
YOLOv2对于VOC的结构,最后将产生13135的目标,但是一张正常的图片中是不可能有这么多物体的,所以最后需要一个阈值限定这些输出,这个阈值论文中给出的是0.24,那么拿什么值和0.24比较呢?上面我们已经拿出了一个probability,还有一个输出是confidence,比较的就是二者的乘积。
在darknet的官网给出了一个图,说明了如果阈值取的非常小的话,就会是这样:
YOLOv2损失函数
YOLOv2同样是一个多任务损失,在R-CNN系列中,一般是把分类的回归的加在一起作为最后的loss function的,而在YOLO2中loss function有四项,并且这四项的weight不同,他们分别是:
- object_scale:5
- noobject_scale:1
- class_scale:1
- corrd_scale:1
什么意思呢?object是对于存在物体的区域判定为无物体,noobject是没有存在物体的区域判定为存在物体,class是分错类别,corrd是bbox的偏差,可以看到,YOLOv2对于检测不到物体时给的惩罚是很大的。
具体的过程是,YOLOv2最先关注的是noobject的类,最后一层会输出 13 × 13 × 5 13\times13\times5 13×13×5个bbox,把这些bbox逐个与每一个ground truth比较,如果还是有一些bbox与ground truth的IOU小于0.6的话,那么就认为属于noobject,传回去的东西就是 n o o b j e c t s c a l e × c o n f i d e n c e noobject_scale\times confidence noobjectscale×confidence。
下一步,关注和ground truth重合度最大的bbox,计算剩下的三个loss,这三个loss是没有判定条件的,不管什么样都会输出:
1.object类会回传object_scale*(1-confidence)
2.corrd类会回传四个数的L1距离
3.class类就直接回传交叉熵

YOLOv2性能评价
YOLOv2在VOC2007表现:
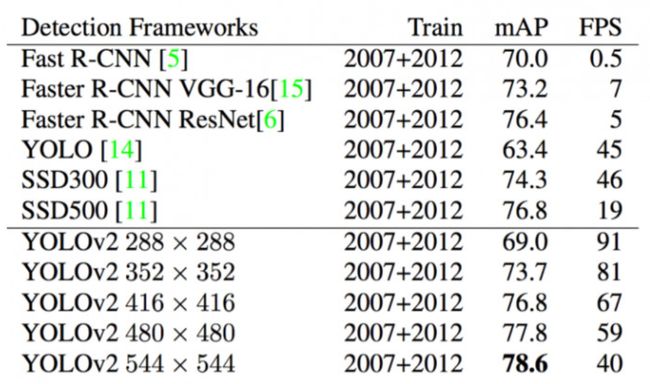
YOLOv2在VOC2012和COCO:

YOLOv2改进细节
最后说一下这个图,其实很多东西上面提到过了:
- BN层
YOLOv2的主干网络加了BN层,因为BN在当时已经被证明了好用,不加白不加; - 高分辨率的分类器
这只是一个trick,用 448 × 448 448\times448 448×448的分辨率图像训练分类backbone; - 卷积
前面提到过,YOLOv2不再是全连接+reshape的方式输出特征图了; - archor box
- 新的backbone
- 维度聚类
- 定位预测
上面四个,前面都提到过; - passthrough
前面提到过,就是那个“route”操作; - 多尺度
用多种尺度的输入训练,这个训练只能训主干,因为不同的输入,最后的检测层会变化; - 高分辨率的检测器
就是输入的图更大了。