kaggle | 基于朴素贝叶斯分类器的语音性别识别
kaggle | 基于朴素贝叶斯分类器的语音性别识别
- 1 背景说明
- 2 关于数据集
- 2.1 什么是kaggle
- 2.2 数据集处理
- 3 代码实现
- 3.1 文件目录
- 3.2 核心代码
- 3.3 注意点
- 4 实验与结果分析
- 5 后记
概要: 本实验基于kaggle上的一个数据集,采用朴素贝叶斯分类器,实现了通过语音识别说话人性别的功能。本文将简要介绍这一方法的原理、代码实现以及在编程过程中需要注意的若干问题,代码仍然是用MATLAB写成的。
关键字: MATLAB; 语音性别识别; 朴素贝叶斯分类器
1 背景说明
由于我之前曾做过用朴素贝叶斯分类器进行数字手写体识别(基于MINIST数据集,之后也将整理到此博客上来)的小作业,所以对这个分类器比较熟悉,因而在此不再赘述其原理。网上有很多关于这个分类器的资料,包括朴素贝叶斯分类器、Naive Bayes classifier以及各种视频资料等等,都是比较优质的资源,随手即可查阅。本文我主要讨论怎样把这个方法用到该数据集上去。
2 关于数据集
2.1 什么是kaggle
这是我在博客中首次提到kaggle,因此有必要向读者作简要介绍。
WiKi上说得很清楚:Kaggle是一个数据建模和数据分析竞赛平台。企业和研究者可在其上发布数据,统计学者和数据挖掘专家可在其上进行竞赛以产生最好的模型。这一众包模式依赖于这一事实,即有众多策略可以用于解决几乎所有预测建模的问题,而研究者不可能在一开始就了解什么方法对于特定问题是最为有效的。Kaggle的目标则是试图通过众包的形式来解决这一难题,进而使数据科学成为一场运动。
而对于我来说它最大的好处就是有免费的数据集可供下载,涉及的内容方方面面——不管你有什么需求都可以去上面试着找一波,而且能找到满意资源的概率还不小。
2.2 数据集处理
这个数据集是基于对男女语音段进行合理的声音预处理而得到的语音特征(并不包含原始语音段)。集合中共有3168条数据,男女各1584条,每条数据可视作一个长度为21的一维数组。其中前20个数值是这条语音的20个特征值,这些特征值包括了语音信号的长度、基频、标准差、频带中值点/一分位频率/三分位频率等;最后一个数值是性别标记。元数据集中直接以字符串,即male和female进行标注,我则用0表示男性、1表示女性以方便后续处理,这当然并无大碍。
若有兴趣继续深入了解该数据集相关信息,请参见此链接。
现在进行数据集的预处理。刚下载下来的原始文件是CSV文件,首先读入MATLAB成为一个3168*21的矩阵。而贝叶斯分类器比较难以处理非整数特征的数据,所以下一步就是量化。
贝叶斯分类器是基于条件概率而进行分类的,所以最重要的一点是数据处理不能改变其分布律,因此一定要进行线性量化。而在这里事实上对结果有影响的是每个特征的相对数值而非绝对大小,故仅量化相对量即可。也就是说,以某一特征在所有实验数据(如上文所说,共计3168条)中的最大、最小值分别作为量化之后的最大、最小值,而不用去管小于最小值的所谓“基础量”。
图1和图2分别展示了所有3168条数据的第4号特征在量化前后的图景,量化阶取20。从中明显可见线性量化不改变原始数据的分布律。
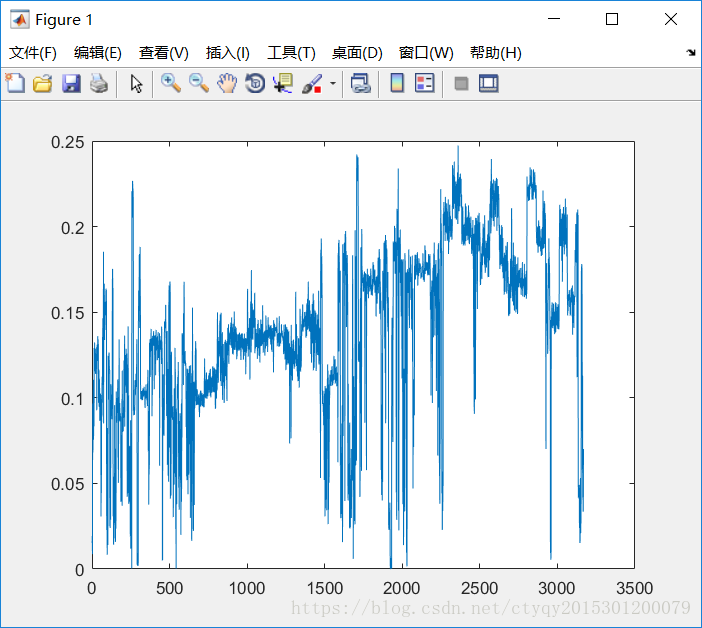
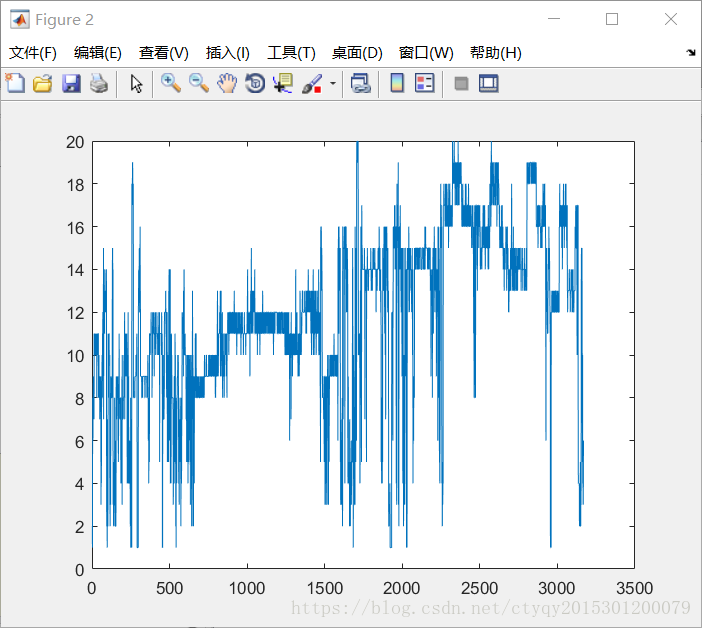
量化阶也是一个需要考虑的参数。量化阶越大,量化越粗糙,计算量越小;量化阶越小,量化越细致,计算量越大。其对最后结果准确性的影响将在后文加以讨论。
另外,仔细观察数据会发现其中有不少数值为0项,这是原始数据的缺项,我直接采用均值加以弥补,在不确定的时候优先考虑均值总不失为一种稳妥的处理方法。注意,对缺项数据的补写应当最优先处理。
最后一步也可以看做是所有学习算法的第一步:划分训练集和验证集。在这里不妨多补充几句关于训练集、验证集和测试集的区别和联系。一般而言,在不考虑测试集时训练集、验证集常采用7:3或8:2的数量划分,考虑到测试集时一般划分为6:2:2。原始数据集的划分还是很有讲究的,周志华教授在他著名的科普大作《机器学习》中对此有很详细的讨论。本实验中我优先按照7:3的比例划分训练集和验证集。
3 代码实现
3.1 文件目录
现在来介绍一下代码的文件目录以及各个文件之间的联系。本实验用到的全部程序如图3所示:
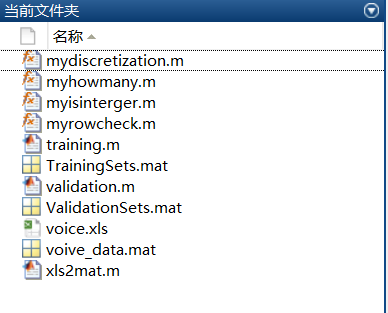
其中倒数第三个.xls文件就是下载得到的文件,将它通过文件xls2mat.m之后即可获得voice_data.mat文件,这就是上文所提到的那个3168*21矩阵。之后再经过文件mydiscretization.m进行量化处理就得到了量化后的数据文件,该数据文件覆盖voice_data.mat。通过文件training.m得到训练集TrainingSets.mat以及通过文件validation.m得到验证集ValidationSets.mat。在实验中,先后运行training.m和validation.m即可得到结果。另外的3个.m文件是辅助性文件,是在我写程序过程中测试代码的正确性顺手写的,它们的功能分别是:
myhowmany.m:查询某个数据在某个矩阵中的数量。
myisinterger.m:查询某矩阵中整数的个数,并找出非整数元素的坐标。
myrowcheck.m:找出某2个矩阵的相同行并返回其在原矩阵中的行坐标。
这三个代码文件不是本实验所必须的,但是在写与数组有关的代码时不失为不错的辅助工具。
3.2 核心代码
核心代码其实很少,只有二三十行,是有关计算后验概率的。
数据训练步骤的核心代码如下:
for j=1:20
for i=1:stepnum
TrainingSets(1).feature_prob(i,j) = ...
(myhowmany(i,TrainingSets(1).feature(:,j))+1)/(M_train_num+1);
TrainingSets(2).feature_prob(i,j) = ...
(myhowmany(i,TrainingSets(2).feature(:,j))+1)/(F_train_num+1);
end
end
这就得到了每一个特征在量化范围内的每一个可能取值的概率。
数据验证步骤的核心代码如下:
for i=1:2
for j=1:ValidationSets(i).number % for each voice
data = ValidationSets(i).feature(j,:);
for k=1:20
% probability of being male voice
ValidationSets(i).results(j,1)=...
TrainingSets(1).feature_prob(data(k),k)*ValidationSets(i).results(j,1);
% probability of being female voice
ValidationSets(i).results(j,2)=...
TrainingSets(2).feature_prob(data(k),k)*ValidationSets(i).results(j,2);
end
if ValidationSets(i).results(j,1) > ValidationSets(i).results(j,2)
% this is male voice
ValidationSets(i).results(j,3) = 0;
else
% this is female voice
ValidationSets(i).results(j,3) = 1;
end
end
end
这就得到了每一条待验证的数据分别为男声和女声的概率,通过比较大小即可得出最终判断。
3.3 注意点
从实际应用角度来看,朴素贝叶斯分类法其实并不太适合于特征数量过多的分类问题,不管是二分类还是多分类。这是由于该方法本质上是概率的叠乘,每有一个特征就需要进行一次概率相乘,而这里有20个特征就需要乘上20次。而概率都是小于1的,所以在计算上颇为麻烦——会得到小于10的负20次方的小数。对这个问题可以采用每次都乘以某个略大于1的常数如sqrt(2)来补偿,或者取对数。
另外一个就是计算量,这一点可以通过不考虑全概率以及人为操作使得先验概率相同这两样手法来减少一些运算。
第三点比较细节,在于若某个新数据在某个特征处取到了训练集所未曾取到的数据,就会得出此处的后验概率为0的结果,从而通过概率连乘导致最终的概率为0,而这显然是不正确的。解决措施也很简单,只要在每次计算时分子分母同时加1即可,而因此所造成的误差可以认为是忽略不计的。
4 实验与结果分析
影响实验结果的因素主要有2个:量化阶数目和数据集比例,因此实验主要围绕这两个参数的改变进行。另外还有一点需要注意的就是:由于数据集是随机划分的,所以每次训练-验证的结果有少许不同是正常的,这是因为每次划分到训练集和验证集中的数据条目并不完全相同。所以我在参数没有改变时连做3次训练-验证实验,取结果的平均值作为在该组量化数目和数据集比例条件下所得模型的识别效果。
简略起见,我在量化数目和数据集比例这两个参数上各取两点:量化阶为10和20,训练集和验证集比例为7:3和8:2。得到的结果如图4所示:
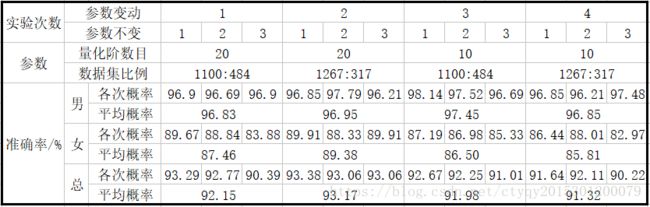
从上图中可以看出:首先,朴素贝叶斯分类器对男声的判断效果明显好于女声;第二,在这四组参数中,量化阶数目选为20、训练集和验证集比例选为8:2(即1267:317)时相对而言效果最好;第三,量化阶选取10和20对识别结果并无显著影响。
显然只选取4组参数是很无法准确体现该算法性能的,但是我比较懒,读者如有兴趣不妨可以多做几组实验,看看能不能找出一组参数使得分辨效果优越的同时尽可能减小量化阶数目,即在效果和运算之间达到一个较好的平衡。
5 后记
本实验的一个遗憾就是没有建立测试代码,也就不能实时检测现场录入的语音性别。这是因为此数据集的来历我还没有研究透彻,也就是说还不明白这20个特征是如何提取出来的。主要还是时间比较紧张,接下来我将花几天时间争取把它弄明白。
转载时务必注明来源及作者。尊重知识产权从我做起。
代码已上传至网络,欢迎下载,密码是0lu5。