hadoop生态系统的详细介绍
前提
日常喜欢看一些微信分享的好文,总结下来,可以作为过滤器吧(节约更多人的时间!),在这里引用的是别人的文章!对原文的作者表示感谢!确实写的很好!
hadoop生态系统的详细介绍
简介
Hadoop是一个开发和运行处理大规模数据的软件平台,是Appach的一个用java语言实现开源软件框架,实现在大量计算机组成的集群中对海量数据进行分布式计算。今天我们来详细介绍下hadoop的生态系统。

Hadoop生态系统概况
Hadoop是一个能够对大量数据进行分布式处理的软件框架。具有可靠、高效、可伸缩的特点。
Hadoop的核心是HDFS和MapReduce,hadoop2.0还包括YARN。
下图为hadoop的生态系统:
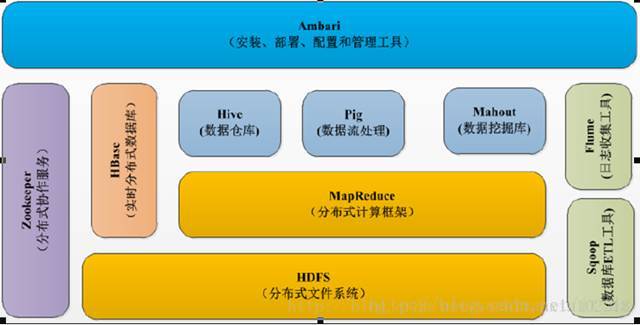
HDFS(Hadoop分布式文件系统)
源自于Google的GFS论文,发表于2003年10月,HDFS是GFS克隆版。
是Hadoop体系中数据存储管理的基础。它是一个高度容错的系统,能检测和应对硬件故障,用于在低成本的通用硬件上运行。HDFS简化了文件的一致性模型,通过流式数据访问,提供高吞吐量应用程序数据访问功能,适合带有大型数据集的应用程序。
HDFS这一部分主要有一下几个部分组成:
- Client:切分文件;访问HDFS;与NameNode交互,获取文件位置信息;与DataNode交互,读取和写入数据。
- NameNode:Master节点,在hadoop1.X中只有一个,管理HDFS的名称空间和数据块映射信息,配置副本策略,处理客户端请求。对于大型的集群来讲,Hadoop1.x存在两个最大的缺陷:
- 1)对于大型的集群,namenode的内存成为瓶颈,namenode的扩展性的问题;
- 2)namenode的单点故障问题。
- 针对以上的两个缺陷,Hadoop2.x以后分别对这两个问题进行了解决。
- 对于缺陷1)提出了Federation namenode来解决,该方案主要是通过多个namenode来实现多个命名空间来实现namenode的横向扩张。从而减轻单个namenode内存问题。
- 针对缺陷2),hadoop2.X提出了实现两个namenode实现热备HA的方案来解决。其中一个是处于standby状态,一个处于active状态。
- DataNode:Slave节点,存储实际的数据,汇报存储信息给NameNode。
- Secondary NameNode:辅助NameNode,分担其工作量;定期合并fsimage和edits,推送给NameNode;紧急情况下,可辅助恢复NameNode,但Secondary NameNode并非NameNode的热备。
目前,在硬盘不坏的情况,我们可以通过secondarynamenode来实现namenode的恢复。
Mapreduce(分布式计算框架)
源自于google的MapReduce论文,发表于2004年12月,Hadoop MapReduce是google MapReduce 克隆版。MapReduce是一种计算模型,用以进行大数据量的计算。其中Map对数据集上的独立元素进行指定的操作,生成键-值对形式中间结果。Reduce则对中间结果中相同“键”的所有“值”进行规约,以得到最终结果。MapReduce这样的功能划分,非常适合在大量计算机组成的分布式并行环境里进行数据处理。
MapReduce计算框架发展到现在有两个版本的MapReduce的API,针对MR1主要组件有以下几个部分组成:
(1)JobTracker:Master节点,只有一个,主要任务是资源的分配和作业的调度及监督管理,管理所有作业,作业/任务的监控、错误处理等;将任务分解成一系列任务,并分派给TaskTracker。
(2)TaskTracker:Slave节点,运行Map Task和Reduce Task;并与JobTracker交互,汇报任务状态。
(3)Map Task:解析每条数据记录,传递给用户编写的map(),并执行,将输出结果写入本地磁盘。
(4)Reducer Task:从Map Task的执行结果中,远程读取输入数据,对数据进行排序,将数据按照分组传递给用户编写的reduce函数执行。
在这个过程中,有一个shuffle过程,对于该过程是理解MapReduce计算框架是关键。该过程包含map函数输出结果到reduce函数输入这一个中间过程中所有的操作,称之为shuffle过程。在这个过程中,可以分为map端和reduce端。
Map端:
1) 输入数据进行分片之后,分片的大小跟原始的文件大小、文件块的大小有关。每一个分片对应的一个map任务。
2) map任务在执行的过程中,会将结果存放到内存当中,当内存占用达到一定的阈值(这个阈值是可以设置的)时,map会将中间的结果写入到本地磁盘上,形成临时文件这个过程叫做溢写。
3) map在溢写的过程中,会根据指定reduce任务个数分别写到对应的分区当中,这就是partition过程。每一个分区对应的是一个reduce任务。并且在写的过程中,进行相应的排序。在溢写的过程中还可以设置conbiner过程,该过程跟reduce产生的结果应该是一致的,因此该过程应用存在一定的限制,需要慎用。
4) 每一个map端最后都只存在一个临时文件作为reduce的输入,因此会对中间溢写到磁盘的多个临时文件进行合并Merge操作。最后形成一个内部分区的一个临时文件。
Reduce端:
1) 首先要实现数据本地化,需要将远程节点上的map输出复制到本地。
2) Merge过程,这个合并过程主要是对不同的节点上的map输出结果进行合并。
3) 不断的复制和合并之后,最终形成一个输入文件。Reduce将最终的计算结果存放在HDFS上。
针对MR2是新一代的MR的API。其主要是运行在Yarn的资源管理框架上。
Yarn(资源管理框架)
该框架是hadoop2.x以后对hadoop1.x之前JobTracker和TaskTracker模型的优化,而产生出来的,将JobTracker的资源分配和作业调度及监督分开。该框架主要有ResourceManager,Applicationmatser,nodemanager。其主要工作过程如下:
- ResourceManager主要负责所有的应用程序的资源分配,
- ApplicationMaster主要负责每个作业的任务调度,也就是说每一个作业对应一个ApplicationMaster。
- Nodemanager是接收Resourcemanager 和ApplicationMaster的命令来实现资源的分配执行体。
ResourceManager在接收到client的作业提交请求之后,会分配一个Conbiner,这里需要说明一下的是Resoucemanager分配资源是以Conbiner为单位分配的。第一个被分配的Conbiner会启动Applicationmaster,它主要负责作业的调度。Applicationmanager启动之后则会直接跟NodeManager通信。
在YARN中,资源管理由ResourceManager和NodeManager共同完成,其中,ResourceManager中的调度器负责资源的分配,而NodeManager则负责资源的供给和隔离。ResourceManager将某个NodeManager上资源分配给任务(这就是所谓的“资源调度”)后,NodeManager需按照要求为任务提供相应的资源,甚至保证这些资源应具有独占性,为任务运行提供基础的保证,这就是所谓的资源隔离。
在Yarn平台上可以运行多个计算框架,如:MR,Tez,Storm,Spark等计算,框架。
Sqoop(数据同步工具)
Sqoop是SQL-to-Hadoop的缩写,主要用于传统数据库和Hadoop之间传输数据。数据的导入和导出本质上是Mapreduce程序,充分利用了MR的并行化和容错性。其中主要利用的是MP中的Map任务来实现并行导入,导出。Sqoop发展到现在已经出现了两个版本,一个是sqoop1.x.x系列,一个是sqoop1.99.X系列。对于sqoop1系列中,主要是通过命令行的方式来操作。
- sqoop1 import原理:从传统数据库获取元数据信息(schema、table、field、field type),把导入功能转换为只有Map的Mapreduce作业,在mapreduce中有很多map,每个map读一片数据,进而并行的完成数据的拷贝。
- sqoop1 export原理:获取导出表的schema、meta信息,和Hadoop中的字段match;多个map only作业同时运行,完成hdfs中数据导出到关系型数据库中。
- Sqoop1.99.x是属于sqoop2的产品,该款产品目前功能还不是很完善,处于一个测试阶段,一般并不会应用于商业化产品当中。
Mahout(数据挖掘算法库)
Mahout起源于2008年,最初是Apache Lucent的子项目,它在极短的时间内取得了长足的发展,现在是Apache的顶级项目。相对于传统的MapReduce编程方式来实现机器学习的算法时,往往需要话费大量的开发时间,并且周期较长,而Mahout的主要目标是创建一些可扩展的机器学习领域经典算法的实现,旨在帮助开发人员更加方便快捷地创建智能应用程序。
Mahout现在已经包含了聚类、分类、推荐引擎(协同过滤)和频繁集挖掘等广泛使用的数据挖掘方法。除了算法,Mahout还包含数据的输入/输出工具、与其他存储系统(如数据库、MongoDB 或Cassandra)集成等数据挖掘支持架构。
mahout的各个组件下面都会生成相应的jar包。此时我们需要明白一个问题:到底如何使用mahout呢?
实际上,mahout只是一个机器学习的算法库,在这个库当中是想了相应的机器学习的算法,如:推荐系统(包括基于用户和基于物品的推荐),聚类和分类算法。并且这些算法有些实现了MapReduce,spark从而可以在hadoop平台上运行,在实际的开发过程中,只需要将相应的jar包即可。
Hbase(分布式列存数据库)
源自Google的Bigtable论文,发表于2006年11月,传统的关系型数据库是对面向行的数据库。HBase是Google Bigtable克隆版,HBase是一个针对结构化数据的可伸缩、高可靠、高性能、分布式和面向列的动态模式数据库。和传统关系数据库不同,HBase采用了BigTable的数据模型:增强的稀疏排序映射表(Key/Value),其中,键由行关键字、列关键字和时间戳构成。HBase提供了对大规模数据的随机、实时读写访问,同时,HBase中保存的数据可以使用MapReduce来处理,它将数据存储和并行计算完美地结合在一起。
Hbase表的特点
- 大:一个表可以有数十亿行,上百万列;
- 无模式:每行都有一个可排序的主键和任意多的列,列可以根据需要动态的增加,同一张表中不同的行可以有截然不同的列;
- 面向列:面向列(族)的存储和权限控制,列(族)独立检索;
- 稀疏:空(null)列并不占用存储空间,表可以设计的非常稀疏;
- 数据多版本:每个单元中的数据可以有多个版本,默认情况下版本号自动分配,是单元格插入时的时间戳;
数据类型单一:Hbase中的数据都是字符串,没有类型。
Hbase物理模型
每个column family存储在HDFS上的一个单独文件中,空值不会被保存。
Key 和 Version number在每个 column family中均有一份;
HBase 为每个值维护了多级索引,即:”key, column family, column name, timestamp”,其物理存储:- Table中所有行都按照row key的字典序排列;
- Table在行的方向上分割为多个Region;
- Region按大小分割的,每个表开始只有一个region,随着数据增多,region不断增大,当增大到一个阀值的时候,region就会等分会两个新的region,之后会有越来越多的region;
- Region是Hbase中分布式存储和负载均衡的最小单元,不同Region分布到不同RegionServer上。、
- Region虽然是分布式存储的最小单元,但并不是存储的最小单元。Region由一个或者多个Store组成,每个store保存一个columns family;每个Strore又由一个memStore和0至多个StoreFile组成,StoreFile包含HFile;memStore存储在内存中,StoreFile存储在HDFS上。
Zookeeper(分布式协作服务)
源自Google的Chubby论文,发表于2006年11月,Zookeeper是Chubby克隆版,主要解决分布式环境下的数据管理问题:统一命名,状态同步,集群管理,配置同步等。
Zookeeper的主要实现两步:
- 选举Leader
- 同步数据。这个组件在实现namenode的HA高可用性的时候,需要用到。
Pig(基于Hadoop的数据流系统)
由yahoo!开源,设计动机是提供一种基于MapReduce的ad-hoc(计算在query时发生)数据分析工具
定义了一种数据流语言—Pig Latin,将脚本转换为MapReduce任务在Hadoop上执行。通常用于进行离线分析。
Hive(基于Hadoop的数据仓库)
由facebook开源,最初用于解决海量结构化的日志数据统计问题。
Hive定义了一种类似SQL的查询语言(HQL),将SQL转化为MapReduce任务在Hadoop上执行。通常用于离线分析。
Flume(日志收集工具)
Cloudera开源的日志收集系统,具有分布式、高可靠、高容错、易于定制和扩展的特点。
它将数据从产生、传输、处理并最终写入目标的路径的过程抽象为数据流,在具体的数据流中,数据源支持在Flume中定制数据发送方,从而支持收集各种不同协议数据。同时,Flume数据流提供对日志数据进行简单处理的能力,如过滤、格式转换等。此外,Flume还具有能够将日志写往各种数据目标(可定制)的能力。总的来说,Flume是一个可扩展、适合复杂环境的海量日志收集系统。