手把手教你用seq2seq模型创建数据产品(附代码)

原文标题:How To Create Data Products That Are Magical Using Sequence-to-Sequence Models
作者:Hamel Husain
翻译:笪洁琼
校对:梁傅淇
本文共7300字,建议阅读14分钟。
本文将教你如何使用Keras和TensorFlow来对Github项目进行文本摘要和特征提取。
目标:训练一个模型来对Github项目进行总结
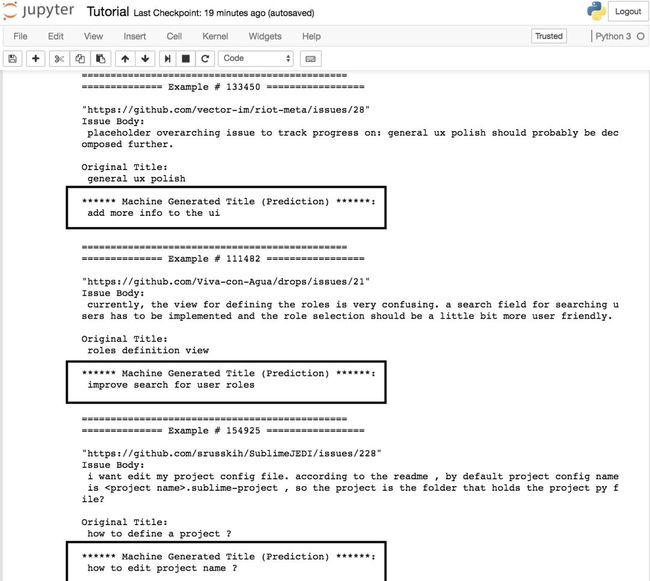
矩形框中的是预测结果
以上只是从一系列预测结果中随机选取的元素,请继续往下读,下文包含一个带有更多示例的链接!

Github的吉祥物章鱼猫(Octocat)
起因
我从来没有想过用“神奇的”这个词来描述机器学习技术的输出结果。但当我逐渐了解可以用于图像识别(https://machinelearningmastery.com/use-pre-trained-vgg-model-classify-objects-photographs/)或者对两吨乐高积木进行分类(https://jacquesmattheij.com/sorting-two-metric-tons-of-lego)的深度学习的时候,这一切改变了。更令人惊奇的是,你不需要一个博士学位或多年的训练来释放这些技术的力量。所有你所需要的只是:不排斥写代码、达到高中数学水平和拥有足够的耐心(http://www.fast.ai/2016/10/08/overview/)。
然而,在工业中使用深度学习技术的例子却少之又少。今天,我将与大家分享一个可复用的最简可行(https://en.wikipedia.org/wiki/Minimum_viable_product)产品,来演示使用深度学习从文本(Github Issues)中创造数据产品。
本教程将专注于使用Sequence to Sequence模型对Github issues上的文本进行概括,并将向您证明:
您不需要强大的计算能力来获得合理的结果(我将使用一个GPU)。
您不需要编写大量的代码。非常令人惊异的是,只需要几行代码就可以产生神奇的事物。
即使你不想对文本进行概括总结,训练一个模型来完成这个任务也会有助于其他进行特征提取的任务。
我将在这篇文章中介绍:
如何收集数据,并处理数据以为深度学习做准备。
如何构造Sequence to Sequence模型架构,并对模型进行训练。
如何使用模型进行推理,讨论和多个用例的演示。
我在这里提供一个端到端的示例以便你建立起一个概念上模型,而不必要深入到数学的细节之中。这里我也提供给你其他链接,让你后续可以研究得更加深入。
获取数据
如果你不熟悉Github Issues(https://guides.github.com/features/issues/),我强烈建议你先去浏览一下。具体来说,我们将要用以联系的数据是Github Issues的正文(Body)和标题(Title)。
下面就是一个例子:
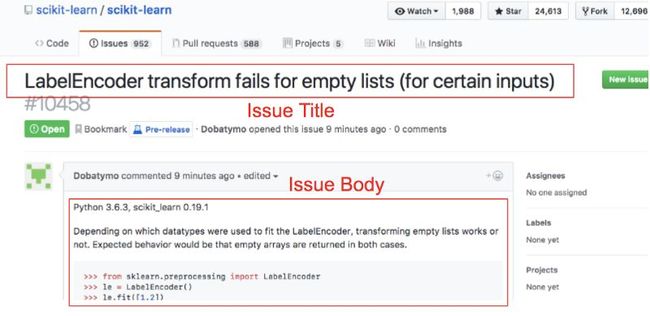
链接:https://github.com/scikit-learn/scikit-learn/issues/10458
我们将收集许多成对的问题的标题与正文来训练我们的模型以完成总结概括的任务。其中所蕴含的思想是通过多个问题的描述和标题一个模型能够学习到如何去总结、概括新的问题。
如果你并非Github的员工,那么获取Github上的数据最好的方法是利用这个出色的开源项目(https://www.githubarchive.org/),它被描述为:“一个记录、存档Github公开时间轴并使之可简易应用于分析的项目。”
本文的附录提供了使用这个项目获取数据的教程。一位聪颖的读者(David Shinn,https://medium.com/@david.shinn)已经完成了附录中列出的所有步骤,将这次练习所需要的数据存储为csv文档并上传到Kaggle!
您可以通过这个链接(https://www.kaggle.com/davidshinn/github-issues)下载数据。
准备和清理数据

有时候,清理数据是很困难的工作(https://goo.gl/images/e5e6j7)
Keras文本预处理
现在我们已经收集了数据,需要为建模对数据进行处理。
在正式开始敲代码之前,让我们先用两个例子来热热身:
[“The quick brown fox jumped over the lazy dog 42 times.”, “The dog is lazy”]
以下是预处理这些原始文本步骤的大致描述:
1. 清理文本:在这个步骤中,我们想要删除或替换特定的字符,并将所有的文本替换为小写字母。这一步是可省略的,取决于数据的大小和你的领域的具体要求。在这个示例中,我将所有的字母小写化并将数字替换成“*数字*”。在实际数据处理过程中,我们还需要适应更多的场景。(https://github.com/hamelsmu/ktext/blob/master/ktext/preprocess.py#L46-L57)
[“the quick brown fox jumped over the lazy dog *number* times”, “the dog is lazy”]
2. 标记化:将每个文档拆分为单词列表
[[‘the’, ‘quick’, ‘brown’, ‘fox’, ‘jumped’, ‘over’, ‘the’, ‘lazy’, ‘dog’, ‘*number*’, ‘times’], [‘the’, ‘dog’, ‘is’, ‘lazy’]]
3.构建词汇表:在语料库中,你需要将每个不同的单词表示为整数,这意味着你需要构建一个标记->整数的映射。此外,我发现为了填充(参阅下一个步骤)而为出现次数低于某个阈值的单词保留一个整数是很有用的。在您应用了标记->整数的映射之后,您的数据可能是这样的:
[[2, 3, 4, 5, 6, 7, 2, 8, 9, 10, 11], [2, 9, 12, 8]]
4. 填充:这样处理过后,您的文本可能长短不一,在深度学习中有许多应对的策略,但在本教程中,我将对文档进行填充或截断,使它们都转换成相同的长度以简化操作。您可以使用0来填充并在开始或结束时截断文档,我分别将其称为“预”(pre)和“后”(post)。在预填充我们的示例之后,数据可能如下:
[[2, 3, 4, 5, 6, 7, 2, 8, 9, 10, 11], [0, 0, 0, 0, 0, 0, 0, 2, 9, 12, 8]]
决定目标文档的长度的一个合理的方式是创建一个文档长度的直方图并从中选择一个合理的数字。(请注意,上面的例子是在文档之前填充数据,但是我们也可以在文档的最后加上填充数据,下一节我们会详细讨论)。
准备Github Issues数据
在本节中,你将依照这个教程(https://github.com/hamelsmu/Seq2Seq_Tutorial/blob/master/notebooks/Tutorial.ipynb)来进行操作,我们所使用的数据看起来像这样:
Pandas dataframe with issue bodies and titles, from this notebook.
包含问题正文和标题的Pandas数据框,来自这篇教程(https://github.com/hamelsmu/Seq2Seq_Tutorial/blob/master/notebooks/Tutorial.ipynb)。
我们将分别处理问题的标题和正文。 网址不会用于建模,而只是作为参考。 请注意,我从500万问题中抽取了200万个问题,以使本教程适合大家使用。
就我个人而言,我发现为深度学习而对文本数据进行预处理的步骤是高度重复的。 Keras可以很好地帮助你(https://keras.io/preprocessing/text/),但是我西望并行处理这些任务以提升速度。
Ktext包
我已经构建了一个名为ktext的库(https://github.com/hamelsmu/ktext),可以帮助你完成上一节描述的预处理步骤。 这个库是Keras和Spacy文本处理程序的简装版,并且利用Python多线程(process-based-threading,https://docs.python.org/2/library/multiprocessing.html)来加快速度。 它将所有的预处理步骤连接在一起,并提供了一系列便利功能。 警告:这个软件包还在开发中,所以在教程没有涉及的方面请谨慎使用(欢迎协助修订!https://github.com/hamelsmu/ktext)。 要了解更多这个库是如何运作的,看看这个教程(https://github.com/hamelsmu/ktext/blob/master/notebooks/Tutorial.ipynb),但现在我建议先往下阅读这篇博客。
为了处理正文数据,我们将执行下面的代码:
在这篇教程(https://github.com/hamelsmu/Seq2Seq_Tutorial/blob/master/notebooks/Tutorial.ipynb)中看完整的代码。
以上的代码清洗、标记、预填充和后截断,使得每个文档都是70个字长。 我通过研究ktext提供的文档长度直方图来决定填充长度。而且,我只保留词汇中出现频次前8,000个单词,其余的单词都被设置为对应于罕见单词的索引1(这是随意的选择)。 在8核、60GB内存的AWS p3.2xlarge实例上需要运行一个小时。以下是原始数据与已处理数据的一个示例:

图片来自这个教程(https://github.com/hamelsmu/Seq2Seq_Tutorial/blob/master/notebooks/Tutorial.ipynb)
这些标题的处理方式几乎相同,但会有一些细微的差别:
在这个教程(https://github.com/hamelsmu/Seq2Seq_Tutorial/blob/master/notebooks/Tutorial.ipynb)看完整的代码。
这一次,我们设定一些额外的参数:
append_indicators=True 会将“_start_”标记和“_end_”标记分别附加到每个文档的开始和结尾处。
padding='post' 意味着0填充将被添加到文档的末尾,而不是默认的开头('pre’)。
以这种方式处理标题,是因为我们希望我们的模型知道标题的第一个字母何时将要出现,并且学习预测短语的结尾应该在哪里。下一节讨论模型结构的时候你将进一步理解这么做的原因。
定义模型的结构

图片来源:https://goo.gl/images/IrVBHB
构建神经网络结构就像堆积乐高积木。对于初学者来说,将每个图层视为一个API会很有用:你向API发送一些数据,然后API会返回一些数据。以这种方式思考事情可以让你不至于被击溃,并且可以慢慢地建立起自己对事物的理解。理解两个概念很重要:
每层预期输入的数据形状以及图层将返回的数据形状。(当你将多个图层堆叠在一起时,输入和输出形状必须是兼容的,就像乐高积木一样)。
概念上来说,图层的输出代表着什么?堆叠层子集的输出代表什么?
以上两个概念对理解本教程至关重要。如果您在阅读以下内容时感觉不能理解,我强烈建议您根据自己的情况从这个MOOC平台(http://www.fast.ai/)上学习课程,然后再继续阅读。
在本教程中,我们将使用Sequence to Sequence的模型。请暂停阅读本教程,并仔细阅读Francois Chollet撰写的《十分钟学会用Keras实现Sequence-to-sequence模型》。
读完这篇文章之后,你应该能够理解下面这张图表,它展现了一个有两个输入、一个输出的网络:
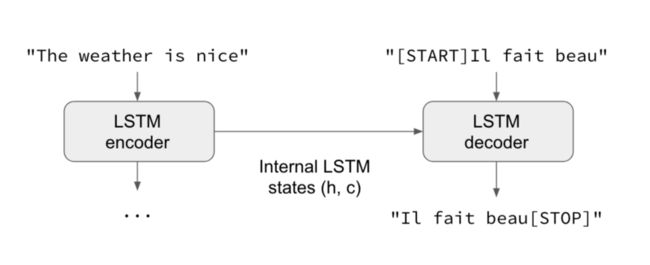
来源:https://blog.keras.io/category/tutorials.html
我们用来解决这个问题的网络跟上面这个教程描述的特别相似,并可以用以下代码进行定义:
更多的内容,请看这个教程(https://github.com/hamelsmu/Seq2Seq_Tutorial/blob/master/notebooks/Tutorial.ipynb)。
在你阅读以上代码时,你会注意到对教师强迫(teacher forcing)概念的引用。教师强迫是一个非常重要的机制,它能够使网络训练得更快。在这篇文章(https://machinelearningmastery.com/teacher-forcing-for-recurrent-neural-networks/)中对此有更详尽的解释。

来源:xkcd
你可能想知道我是在哪里找到上述结构的。我从公开参考的示例出发,并进行了大量的实验。xkcd漫画描述得十分生动。你会注意到我的损失函数是稀疏多分类的对数损失(sparse categorical crossentropy)而非多分类对数损失(categorical crossentropy),这样我就可以直接使用整数而非独热编码来进行预测,这将更有效地利用内存。
训练模型

图片来源:https://goo.gl/images/MYrQHk
我们将要通过“转动随机最速下降法(SGD,https://en.wikipedia.org/wiki/Stochastic_gradient_descent)的曲柄”来训练我们的模型。
训练模型的代码非常明确,是调用所定义的模型对象的合适方法。我们传递额外的参数,如登录回调(https://en.wikipedia.org/wiki/Callback_(computer_programming)),训练次数(https://stackoverflow.com/questions/4752626/epoch-vs-iteration-when-training-neural-networks)和批大小(https://stackoverflow.com/questions/4752626/epoch-vs-iteration-when-training-neural-networks)。
以下是我们用于训练模型的代码,同时还有一个markdown文件显示了运行这个代码的结果。想了解更多相关的信息,请参阅Jupyter笔记本。
我在AWS p3.2xlarge实例(https://aws.amazon.com/ec2/instance-types/p3/)上训练了这个模型,训练7次大约需要35分钟。实际应用过程中,我可能会让模型训练更长一段时间,并使用额外的回调函数(https://keras.io/callbacks/)来提前停止训练或动态调整学习率。但是,我发现上面列出的训练过程对最简可行产品而言已经足够了。
通过使用更先进的学习率调整方式和改进模型结构可以大大改善模型训练结果,本文末尾的“后续步骤”部分将对此进行讨论。
准备模型以备推理

图片来源:https://goo.gl/images/8ifMZA
为了准备好模型来推理(做出预测),我们必须重新组装它(训练后的权重不变),使得解码器将最新的预测结果而非前一次训练中的正确预测结果作为输入,如下图所示:
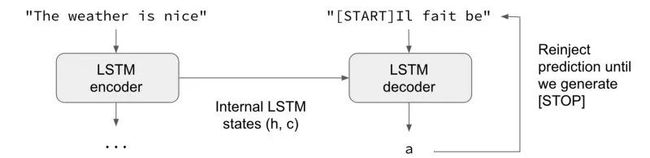
从Keras教程中有关sequence to sequence学习过程的内容(https://blog.keras.io/a-ten-minute-introduction-to-sequence-to-sequence-learning-in-keras.html)中截取。
如果没有明白,请重温此教程(https://blog.keras.io/a-ten-minute-introduction-to-sequence-to-sequence-learning-in-keras.html)。 解码器使用以下的代码进行重构(我在代码中作了非常详细的注释以方便你参照代码逐步操作):
更多用于预测的辅助函数在这个文件之中(https://github.com/hamelsmu/Seq2Seq_Tutorial/blob/master/notebooks/seq2seq_utils.py)。具体来说,generate_issue_title方法(https://github.com/hamelsmu/Seq2Seq_Tutorial/blob/master/notebooks/seq2seq_utils.py#L233-L280)定义了预测问题标题的机制。在本教程中,我采用了贪心策略来决定下一个最佳的单词。 我建议你认真地阅读代码以便充分理解预测是如何做出的。
演示此模型的作用

图片来源:https://goo.gl/images/bfPNhR
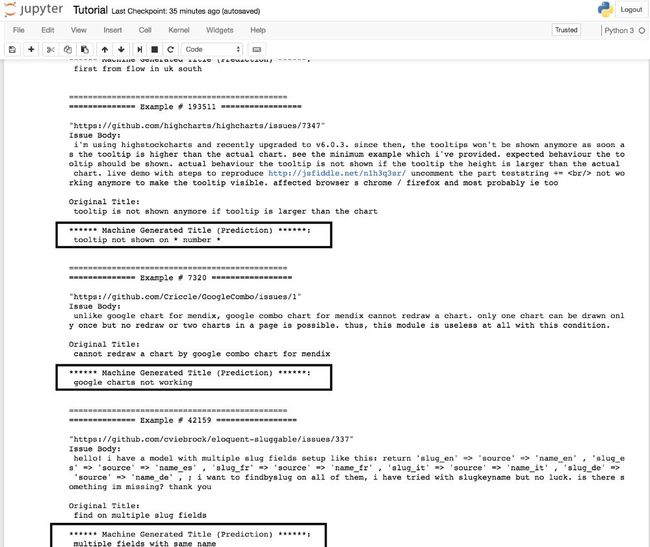
1. 总结文本,生成有创新性的好样例。
在典型的分类和回归模型中,除非伴随着大量的可视化和故事讲述,否则预测本身并非那么有趣。 然而,如果你可以训练一个模型来总结一段由自然语言写成的文本,那么预测本身就是向观众展示你已经学会从自然语言中提取有意义的特征的好方法——如果预测结果是好的,预测本身看起来就会很神奇。
总结文本的能力本身就可以是一个有用的数据产品,例如自动向用户提供拟定标题的建议。 但是,这可能并非这个模型中最有用的部分。 接下来的部分将讨论此模型的其他功能。
为文集做文本摘要的示例(更多示例可以参照这里:https://github.com/hamelsmu/Seq2Seq_Tutorial/blob/master/notebooks/Tutorial.ipynb):

预测结果在矩形框中。教程在Github上公开(https://github.com/hamelsmu/Seq2Seq_Tutorial/blob/master/notebooks/Tutorial.ipynb)。
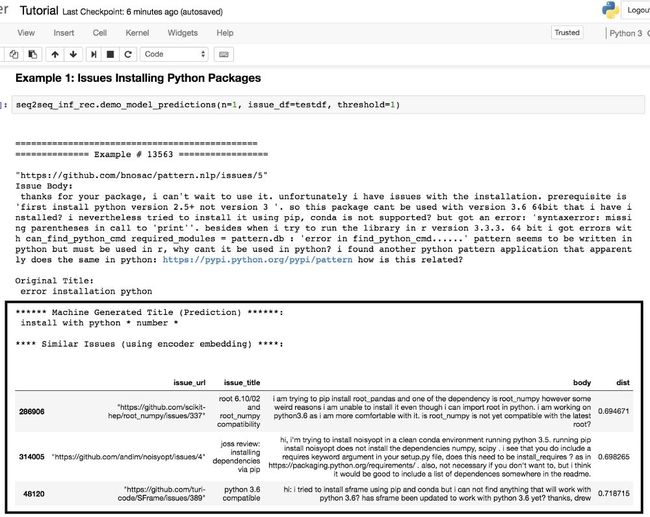
2. 提取可复用于大量任务的特征。
回想一下,Sequence to sequence模型有两个组成部分:编码器和解码器。编码器“编码”信息或从文本中提取特征,并将这些信息提供给解码器,解码器接收这些信息并试图尝试以自然语言生成连贯的概要。
在本教程中,编码器会为每个问题生成一个300维向量。这个向量可以用于各种机器学习任务,例如:
构建推荐系统来查找相似或重复的问题。
检测无用的问题。
为回归模型提供额外的特征以预测问题持续开放的时间。
为分类器提供额外的特征以识别哪些问题反映了缺陷或者漏洞。
应该指出的是,从正文中提取特征的方法有很多种,而且不能保证用某种方式提取的特征在特定任务上的应用效果会比另一种方法所提取的特征更好。我发现将用此方法提取的特征与其他特征相结合通常很有用。然而,我想强调的是,你可以在训练模型去总结文本的同时将获得这些特征!
以下是这些特征的一个应用实例。由于编码器提供了每一个问题所对应的300维向量,所以在向量空间中找到每个问题的最近邻居非常简单。使用annoy包(https://github.com/spotify/annoy),我就可以展示最近邻居、为好几个问题生成标题。
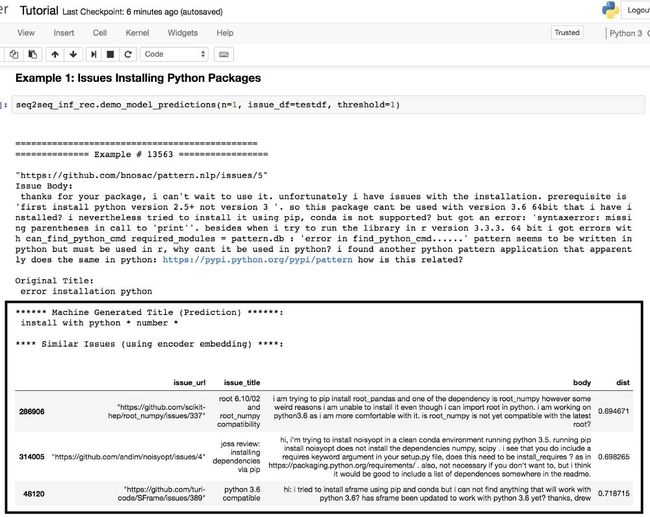
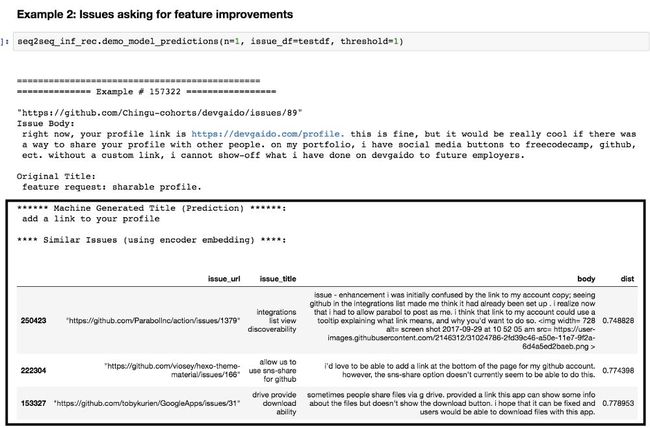
预测结果在矩形框中。这教程在Github上公开。(https://github.com/hamelsmu/Seq2Seq_Tutorial/blob/master/notebooks/Tutorial.ipynb)
以上两个示例展示了编码器提取的特性是如何应用到寻找语义上相似的问题的。除此以外,你还可以将这些特性应用到推荐系统或以上所列出的其他机器学习任务中。
更令人兴奋的是,它的应用并不仅仅局限于问题。我们可以使用相同的方法为README文件(https://help.github.com/articles/about-readmes/)、评论和代码中的说明部分(http://www.pythonforbeginners.com/basics/python-docstrings)生成标题。它的应用空间是无限的。我在附录中会介绍一个数据库,你可以从这个数据库中获取数据并亲自尝试一下!
模型评价
一个评估文本摘要模型性能的好方法是BLEU评分(https://en.wikipedia.org/wiki/BLEU)。在这里(https://github.com/hamelsmu/Seq2Seq_Tutorial/blob/master/notebooks/seq2seq_utils.py#L394-L425)可以找到生成BLEU评分的代码。这篇新博客(https://blog.floydhub.com/turning-design-mockups-into-code-with-deep-learning/)很好地用可视化方法阐释了这个指标。我将这个BLEU评分方法留给各位读者来练习。
虽然我不能分享我最好的模型的BLEU评分,但我可以告诉你,我在这篇文章中分享的模型有很大的改进空间。在下面的步骤中,我提供了一些提示。
下一步
本文的目标是演示如何使用Seq2Seq(Sequence to sequence)模型来生成有趣的数据产品。我正在积极调试的模型与此架构并不相同,但基本思想是相通的。有一些有用的改善技巧我并没有在本篇博客中提及:
增添attention层、双向的循环神经网络(RNNs)。
在编码器和解码器中叠加更多的重复层,并调整不同层的大小。
使用正规化(不包括dropout)。
使用完整的问题语料库预先训练词嵌入(word embeddings)。
采用更好的分词器,可以处理代码和文字混合的文本、其他问题模板还有其他Markdown文件(https://guides.github.com/features/mastering-markdown/)。
使用更多的数据训练(我们在本教程中只使用200万个问题来训练示例模型,还有更多可用数据)。
使用beam search(https://en.wikipedia.org/wiki/Beam_search)而不是贪婪策略来预测问题标题。
探索基于PyTorch(http://pytorch.org/) 的fastai库(https://github.com/fastai/fastai),它阐释了也可应用于NLP的几种精巧的手法,包括从Keras切换到PyTorch。
上述技巧是更为高级的内容,但是学习起来可以非常容易。想要了解更多信息的读者,请参阅资源部分的内容。
复现环境:Nvidia-Docker
为了提供给那些尝试运行我代码的人的方便,我将所有的依赖项打包成一个Nvidia-Docker容器。对于那些不熟悉Docker的人,也许我的这篇博客(https://towardsdatascience.com/how-docker-can-help-you-become-a-more-effective-data-scientist-7fc048ef91d5)会对你有用。
Dockerhub上本教程的镜像(https://hub.docker.com/r/hamelsmu/ml-gpu/)。
资源
本文的Github版本在这里(https://github.com/hamelsmu/Seq2Seq_Tutorial),而Juypter笔记本可以在这里(https://github.com/hamelsmu/Seq2Seq_Tutorial/blob/master/notebooks/Tutorial.ipynb)查看。
在学习这些概念的过程中,我在Jeremy Howard的fast.ai课程上实现了最高的回报率 。在这门MOOC课程的最新版本中,Jeremy使用PyTorch,而不是Keras,并使用带随机重启的周期性学习率(https://arxiv.org/abs/1506.01186)等有用特征进行高度抽象。
Francois Chollet的博客(https://blog.keras.io/)、Keras库(https://keras.io/)的文档,还有Keras在Github上的问题部分(https://github.com/keras-team/keras/issues)。
Kaggle数据集页(https://www.kaggle.com/davidshinn/github-issues/)中有供此练习的数据(感谢David Shinn(https://medium.com/@david.shinn))。如果你想获得更大的数据集,可以扩展原始的查询参数,如附录所述。
Avneesh Saluja(https://medium.com/@asaluja)——Airbnb的机器学习科学家,在这精彩的演讲(https://www.youtube.com/watch?v=kX4CiA94bmQ&feature=youtu.be)中展示了他使用类似的方法做了什么。
鸣谢
此外,感谢那些审阅这篇文章,并给我提供了宝贵的信息的人们:David Shinn、Robert Chang和Zachary Deane-Maye.
联系我
我希望你喜欢这篇博客文章。 以下是我的联系方式:
Twitter(https://twitter.com/HamelHusain)
Linkedin(https://www.linkedin.com/in/hamelhusain/)
Github(https://github.com/hamelsmu)
警告和免责声明
本文中提出的所有想法或观点都是我自己的。文中提及的任意想法或技术并不预示将来Github会推出的产品。
附录——[选读] 如何从头开始自己获取Github问题数据

图片来源:https://goo.gl/images/NfaY7t
获取这些数据(https://www.githubarchive.org/)最简单的方法是使用BigQuery。 当你注册Google Cloud帐户时,他们会给你300美元,足够用来查询此练习所需要的数据。如果有聪明的读者找出一个更简单的方法来获取这些数据,请在评论中说明!这还可以让你制作一个出色的Kaggle数据集(https://www.kaggle.com/datasets)以获取积分呢。
我们将严格按照这个链接(https://www.githubarchive.org/#bigquery)中的指引进行操作。如果你感到迷茫,请参考此文档。不过,我会提供以下步骤指引:
如果你还没有在Google上创建项目:
登录到Google开发者控制台
创建一个项目并激活BigQuery API
在计费控制台(https://console.cloud.google.com/billing/)确认你创建的项目与你的计费账户相关联,这样你就可以利用作为新用户获得的300美元优惠(这个练习的查询花费了我4美元)。
完成以上步骤之后,你就可以继续查询数据了。你可以点击此链接(https://bigquery.cloud.google.com/table/githubarchive:day.20150101)查看查询控制台。你需要选择屏幕右上角的“Query Table”按钮,然后你就会看到这样的屏幕:
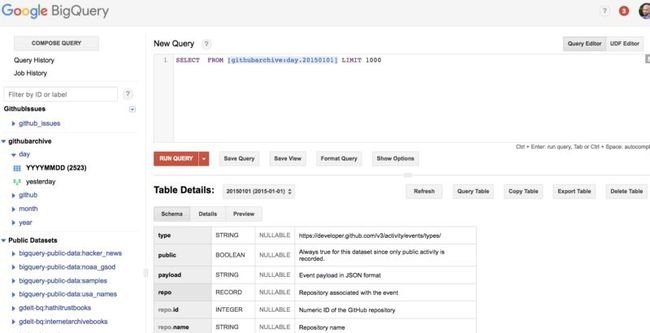
接下来,你可以单击“Show Options”按钮,并确认“Legacy SQL”复选框未被选中(默认情况下为选中状态)。
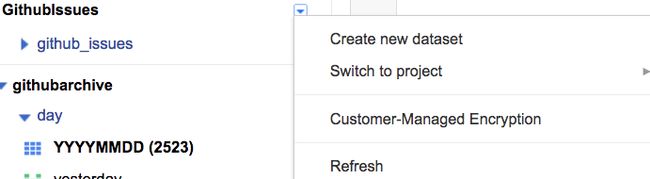
你还会注意到,左侧会显示你的项目名称,我的项目名称是GithubIssues。点击名称旁边的蓝色下拉框(如下图),选择“Create new dataset”并为数据集取名。你可以看到,我的数据集取名为github_issues。这个名称之后会有用处
现在,我们已经准备好获取所需的数据了!复制下面的SQL查询代码并粘贴到控制台中,并单击红色按钮“Run query”。或者,你也可以点击这个链接(https://bigquery.cloud.google.com/savedquery/506213277345:60eee3aa040c40e0bda4e07c5e024b5e)。你可以随时研究下面的SQL代码,我们仅仅只是收集问题的标题和正文,并在收集数据的同时对它进行一些清理。
查询会返回大约从Github问题上截取的包含url、标题和正文的500万数据行,这个文件可以在这里(https://github.com/hamelsmu/Seq2Seq_Tutorial)找到。
在查询完成之后,你应该将它保存到Google Cloud Bucket(https://console.cloud.google.com/storage/)中,这类似于Amazon S3(https://aws.amazon.com/s3/)存储。为此,你应该单击查询结果上方的“Save as Table”按钮,这将显示以下窗口:
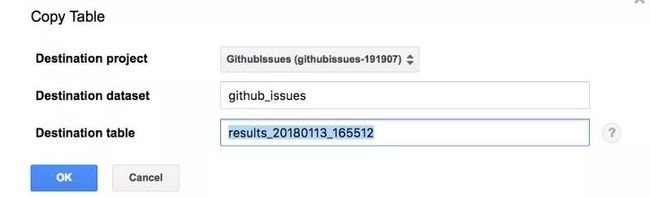
选择目标数据集(你在前面的步骤中创建的数据集)并点击ok。现在切换到你刚才在左侧窗格中创建的表格,选择蓝色的下拉菜单,点击“Export table”,这时,你将会看到这样的窗口:
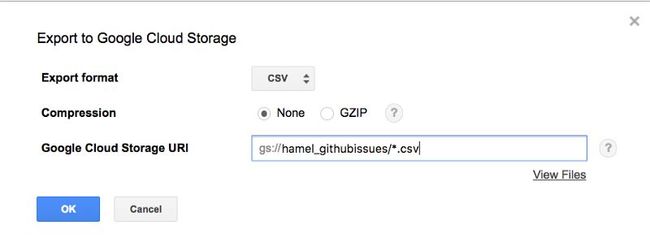
如果你没有Google Cloud Bucket的话,你需要点击“View Files”链接来创建一个。Google云存储的URI语法如下:
g:/ / bucket_name / destination_filename.csv
由于数据量太大,无法放入一个csv文件中(总数据约为3GB),你必须添加一个通配符。例如,我的(私有)bucket的名称是hamel_githubissues,所以我在这里放置文件的路径是:
g:/ / hamel_githubissues / * . csv
一旦你完成了这一步骤,你将看到表名旁的一条消息(显示“…extracting”)。这仅仅需要几分钟的时间。之后,你可以切换到你的bucket并看到这些文件(就像下面所显示的一样):
包含我们查询得到的数据的多个csv文件。
在你下载这些数据之后,你就拥有完成本教程余下部分所需的全部内容。
你可以通过简单单击每个文件或使用谷歌云存储客户端(Google Cloud Storage)CLI(https://cloud.google.com/storage/docs/gsutil)来下载这些数据。
或者,你可以使用pandas库(http://pandas.pydata.org/pandas-docs/stable/generated/pandas.read_gbq.html)来完成查询表格的整个过程。
老实说,我决定只使用用户界面,因为我很少使用谷歌云。
感谢Robert Chang。(https://medium.com/@rchang?source=post_page)
原文链接:https://towardsdatascience.com/how-to-create-data-products-that-are-magical-using-sequence-to-sequence-models-703f86a231f8
译者简介

笪洁琼,中南财大MBA在读,目前研究方向:金融大数据。目前正在学习如何将py等其他软件广泛应用于金融实际操作中,例如抓包预测走势(不会预测股票/虚拟币价格)。可能是金融财务中最懂建筑设计(风水方向)的长腿女生。花式调酒机车冲沙。上赛场里跑过步开过车,商院张掖丝路挑战赛3天徒步78公里。大美山水心欲往,凛冽风雨信步行。
翻译组招募信息
工作内容:需要一颗细致的心,将选取好的外文文章翻译成流畅的中文。如果你是数据科学/统计学/计算机类的留学生,或在海外从事相关工作,或对自己外语水平有信心的朋友欢迎加入翻译小组。
你能得到:定期的翻译培训提高志愿者的翻译水平,提高对于数据科学前沿的认知,海外的朋友可以和国内技术应用发展保持联系,THU数据派产学研的背景为志愿者带来好的发展机遇。
其他福利:来自于名企的数据科学工作者,北大清华以及海外等名校学生他们都将成为你在翻译小组的伙伴。
点击文末“阅读原文”加入数据派团队~
转载须知
如需转载,请在开篇显著位置注明作者和出处(转自:数据派ID:datapi),并在文章结尾放置数据派醒目二维码。有原创标识文章,请发送【文章名称-待授权公众号名称及ID】至联系邮箱,申请白名单授权并按要求编辑。
发布后请将链接反馈至联系邮箱(见下方)。未经许可的转载以及改编者,我们将依法追究其法律责任。

点击“阅读原文”拥抱组织