【Spark Mllib】K-均值聚类——电影类型
http://blog.csdn.net/u011239443/article/details/51707802
K-均值聚类
K-均值算法试图将一系列样本分割成K个不同的类簇(其中K是模型的输入参数),其形式化的目标函数称为类簇内的方差和(within cluster sum of squared errors,WCSS)。K-均值聚类的目的是最小化所有类簇中的方差之和。标准的K-均值算法初始化K个类中心(为每个类簇中所有样本的平均向量),后面的过程不断重复迭代下面两个步骤。
(1) 将样本分到WCSS最小的类簇中。因为方差之和为欧拉距离的平方,所以最后等价于将每个样本分配到欧拉距离最近的类中心。
(2) 根据第一步类分配情况重新计算每个类簇的类中心。
K-均值迭代算法结束条件为达到最大的迭代次数或者收敛。收敛意味着第一步类分配之后没有改变,因此WCSS的值也没有改变。
数据特征提取
这里我还是会使用之前分类模型的MovieLens数据集。
// load movie data
val movies = sc.textFile("/PATH/ml-100k/u.item")
println(movies.first)
// 1|Toy Story (1995)|01-Jan-1995||http://us.imdb.com/M/title-exact?Toy%20Story%20(1995)|0|0|0|1|1|1|0|0|0|0|0|0|0|0|0|0|0|0|0- 提取电影的题材标题
在进一步处理之前,我们先从u.genre文件中提取题材的映射关系。
val genres = sc.textFile("/PATH/ml-100k/u.genre")
genres.take(5).foreach(println)
/*
unknown|0
Action|1
Adventure|2
Animation|3
Children's|4
*/
val genreMap = genres.filter(!_.isEmpty).map(line => line.split("\\|")).map(array => (array(1), array(0))).collectAsMap
println(genreMap)
// Map(2 -> Adventure, 5 -> Comedy, 12 -> Musical, 15 -> Sci-Fi, 8 -> Drama, 18 -> Western, ...
val titlesAndGenres = movies.map(_.split("\\|")).map { array =>
val genres = array.toSeq.slice(5, array.size)
val genresAssigned = genres.zipWithIndex.filter { case (g, idx) =>
g == "1"
}.map { case (g, idx) =>
genreMap(idx.toString)
}
(array(0).toInt, (array(1), genresAssigned))
}
println(titlesAndGenres.first)
// (1,(Toy Story (1995),ArrayBuffer(Animation, Children's, Comedy)))- 训练推荐模型
// Run ALS model to generate movie and user factors
import org.apache.spark.mllib.recommendation.ALS
import org.apache.spark.mllib.recommendation.Rating
val rawData = sc.textFile("/PATH/ml-100k/u.data")
val rawRatings = rawData.map(_.split("\t").take(3))
val ratings = rawRatings.map{ case Array(user, movie, rating) => Rating(user.toInt, movie.toInt, rating.toDouble) }
ratings.cache
val alsModel = ALS.train(ratings, 50, 10, 0.1)
// extract factor vectors
import org.apache.spark.mllib.linalg.Vectors
val movieFactors = alsModel.productFeatures.map { case (id, factor) => (id, Vectors.dense(factor)) }
val movieVectors = movieFactors.map(_._2)
val userFactors = alsModel.userFeatures.map { case (id, factor) => (id, Vectors.dense(factor)) }
val userVectors = userFactors.map(_._2)训练聚类模型
在MLlib中训练K-均值的方法和其他模型类似,只要把包含训练数据的RDD传入KMeans对象的train方法即可。注意,因为聚类不需要标签,所以不用LabeledPoint实例,而是使用特征向量接口,即RDD的Vector数组即可。MLlib的K-均值提供了随机和K-means||两种初始化方法,后者是默认初始化。因为两种方法都是随机选择,所以每次模型训练的结果都不一样。K-均值通常不能收敛到全局最优解,所以实际应用中需要多次训练并选择最优的模型。MLlib提供了完成多次模型训练的方法。经过损失函数的评估,将性能最好的一次训练选定为最终的模型。
代码实现中,首先需要引入必要的模块,设置模型参数:
K(numClusters)、最大迭代次数(numIteration)和训练次数(numRuns)。然后,对电影的系数向量运行K-均值算法。最后,在用户相关因素的特征向量上训练K-均值模型:
// run K-means model on movie factor vectors
import org.apache.spark.mllib.clustering.KMeans
val numClusters = 5
val numIterations = 10
val numRuns = 3
val movieClusterModel = KMeans.train(movieVectors, numClusters, numIterations, numRuns)
/*
...
14/09/02 22:16:45 INFO SparkContext: Job finished: collectAsMap at KMeans.scala:193, took 0.02043 s
14/09/02 22:16:45 INFO KMeans: Iterations took 0.300 seconds.
14/09/02 22:16:45 INFO KMeans: KMeans reached the max number of iterations: 10.
14/09/02 22:16:45 INFO KMeans: The cost for the best run is 2585.6805358546403.
...
movieClusterModel: org.apache.spark.mllib.clustering.KMeansModel = org.apache.spark.mllib.clustering.KMeansModel@2771ccdc
*/
// train user model
val userClusterModel = KMeans.train(userVectors, numClusters, numIterations, numRuns)使用聚类模型进行预测
K-均值最小化的目标函数是样本到其类中心的欧拉距离之和,我们便可以将“最靠近类中心”定义为最小的欧拉距离。
下面让我们定义这个度量函数,注意引入Breeze库(MLlib的一个依赖库)用于线性代数和向量运算:
// define Euclidean distance function
import breeze.linalg._
import breeze.numerics.pow
def computeDistance(v1: DenseVector[Double], v2: DenseVector[Double]): Double = pow(v1 - v2, 2).sum利用上面的函数对每个电影计算其特征向量与所属类簇中心向量的距离:
// join titles with the factor vectors, and compute the distance of each vector from the assigned cluster center
val titlesWithFactors = titlesAndGenres.join(movieFactors)
val moviesAssigned = titlesWithFactors.map { case (id, ((title, genres), vector)) => //vector可以理解为该点的坐标向量
val pred = movieClusterModel.predict(vector)//pred为预测出的该点所属的聚点
val clusterCentre = movieClusterModel.clusterCenters(pred)//clusterCentre为该pred聚点的坐标向量
val dist = computeDistance(DenseVector(clusterCentre.toArray), DenseVector(vector.toArray))//求两坐标的距离
(id, title, genres.mkString(" "), pred, dist)
}
val clusterAssignments = moviesAssigned.groupBy { case (id, title, genres, cluster, dist) => cluster }.collectAsMap//根据聚点分组 我们枚举每个类簇并输出距离类中心最近的前20部电影
for ( (k, v) <- clusterAssignments.toSeq.sortBy(_._1)) {
println(s"Cluster $k:")
val m = v.toSeq.sortBy(_._5)
println(m.take(20).map { case (_, title, genres, _, d) => (title, genres, d) }.mkString("\n"))
println("=====\n")
}- Cluster 0
包含了很多20世纪40年代、50年代和60年代的老电影,以及一些近代的戏剧:

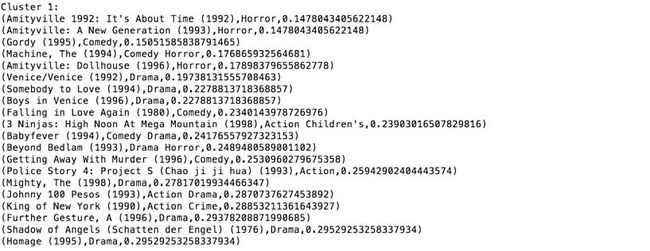
- Cluster 1
主要是一些恐怖电影:
- Cluster 2
有相当一部分是喜剧和戏剧电影:

- Cluster 3
和戏剧相关:

- Cluster 4
主要是动作片、惊悚片和言情片:

正如你看到的,我们并不能明显看出每个类簇所表示的内容。但是,也有证据表明聚类过程会提取电影之间的属性或者相似之处,这不是单纯基于电影名称和题材容易看出来的(比如外语片的类簇和传统电影的类簇,等等)。如果我们有更多元数据,比如导演、演员等,便有可能从每个类簇中找到更多特征定义的细节
评估聚类模型的性能
与回归、分类和推荐引擎等模型类似,聚类模型也有很多评价方法用于分析模型性能,以及评估模型样本的拟合度。聚类的评估通常分为两部分:内部评估和外部评估。内部评估表示评估过程使用训练模型时使用的训练数据,外部评估则使用训练数据之外的数据。
内部评价指标WCSS(我们之前提过的K-元件的目标函数),是使类簇内部的样本距离尽可能接近,不同类簇的样本相对较远。
MLlib提供的函数computeCost可以方便地计算出给定输入数据RDD [Vector]的WCSS。下面我们使用这个方法计算电影和用户训练数据的性能:
// compute the cost (WCSS) on for movie and user clustering
val movieCost = movieClusterModel.computeCost(movieVectors)
val userCost = userClusterModel.computeCost(userVectors)
println("WCSS for movies: " + movieCost)
println("WCSS for users: " + userCost)
// WCSS for movies: 2586.0777166339426
// WCSS for users: 1403.4137493396831聚类模型参数调优
不同于以往的模型,K-均值模型只有一个可以调的参数,就是K,即类中心数目。
// cross-validation for movie clusters
val trainTestSplitMovies = movieVectors.randomSplit(Array(0.6, 0.4), 123)
val trainMovies = trainTestSplitMovies(0)
val testMovies = trainTestSplitMovies(1)
val costsMovies = Seq(2, 3, 4, 5, 10, 20).map { k => (k, KMeans.train(trainMovies, numIterations, k, numRuns).computeCost(testMovies)) }
println("Movie clustering cross-validation:")
costsMovies.foreach { case (k, cost) => println(f"WCSS for K=$k id $cost%2.2f") }
/*
Movie clustering cross-validation:
WCSS for K=2 id 942.06
WCSS for K=3 id 942.67
WCSS for K=4 id 950.35
WCSS for K=5 id 948.20
WCSS for K=10 id 943.26
WCSS for K=20 id 947.10
*/
// cross-validation for user clusters
val trainTestSplitUsers = userVectors.randomSplit(Array(0.6, 0.4), 123)
val trainUsers = trainTestSplitUsers(0)
val testUsers = trainTestSplitUsers(1)
val costsUsers = Seq(2, 3, 4, 5, 10, 20).map { k => (k, KMeans.train(trainUsers, numIterations, k, numRuns).computeCost(testUsers)) }
println("User clustering cross-validation:")
costsUsers.foreach { case (k, cost) => println(f"WCSS for K=$k id $cost%2.2f") }
/*
User clustering cross-validation:
WCSS for K=2 id 544.02
WCSS for K=3 id 542.18
WCSS for K=4 id 542.38
WCSS for K=5 id 542.33
WCSS for K=10 id 539.68
WCSS for K=20 id 541.21
*/从结果可以看出,随着类中心数目增加,WCSS值会出现下降,然后又开始增大。另外一个现象,K-均值在交叉验证的情况,WCSS随着K的增大持续减小,但是达到某个值后,下降的速率突然会变得很平缓。这时的K通常为最优的K值(这称为拐点)。