卷积神经网络与caffe的卷积层、池化层
卷积神经网络
卷积神经网络(CNN)是深度学习技术中极具代表的网络结构之一,在图像处理领域取得了很大的成功。在国际标准ImageNet数据集上,许多成功的模型都是基于CNN的。CNN相较于传统的图像处理算法的优点之一在于:可以直接输入原始图像,避免了对图像复杂的前期预处理过程(如:提取特征等)。传统的神经网络采用全连接的方式,即:输入层到隐藏层的神经元都是全部连接的,这样做将导致参数量巨大,使得网络训练耗时甚至难以训练,而CNN则通过局部连接、权值共享等方法避免这一困难。
在图像处理中,往往把图像表示为像素的向量,比如一个1000×1000的图像,可以表示为一个1000000的向量。在神经网络中,如果隐含层数目与输入层一样,也是1000000时,那么输入层到隐含层的参数数据为1000000×1000000=10^12,这样参数就太多了,基本没法训练。所以图像处理要想练成神经网络大法,必先减少参数、加快速度。卷积神经网络有两种神器可以降低参数数目:局部连接(Sparse Connectivity)和权值共享(Shared Weights)方法。
-------------------------------------------------------------------------------------------------------------------------------------
局部连接
局部连接的示意图,如下图所示:

在上图中,左边是全连接,右边是局部连接。对于一个1000 × 1000的输入图像而言,如果下一个隐藏层的神经元数目为10^6个,采用全连接则有1000 × 1000 × 10^6 = 10^12个权值参数,如此数目巨大的参数几乎难以训练;而采用局部连接,隐藏层的每个神经元仅与图像中10 × 10的局部图像相连接,那么此时的权值参数数量为10 × 10 × 10^6 = 10^8,将直接减少4个数量级。
-------------------------------------------------------------------------------------------------------------------------------------
权值共享
采用上述方法,虽然减少了参数,但是参数量依然很多。为了进一步减少参数,可以再采用权值共享。具体做法是,在局部连接中隐藏层的每一个神经元连接的是一个10 × 10的局部图像,因此有10 × 10个权值参数。将这10 × 10个权值参数共享给剩下的神经元,也就是说隐藏层中10^6个神经元的权值参数相同,那么此时不管隐藏层神经元的数目是多少,需要训练的参数就是这 10 × 10个权值参数(也就是卷积核的大小)。
-------------------------------------------------------------------------------------------------------------------------------------
多卷积核
上面所述只有100个参数时,表明只有1个10*10的卷积核,显然,特征提取是不充分的。我们可以添加多个卷积核,比如:32个卷积核,这样就可以学习32种特征。采用多卷积核时,如下图所示:

在上图中,不同颜色表明不同的卷积核,每个卷积核都会将图像生成为另一幅图像。比如,两个卷积核就可以将生成两幅图像,这两幅图像可以看做是一张图像的不同的通道
-------------------------------------------------------------------------------------------------------------------------------------池化
通过卷积获得了特征之后,我们希望利用这些特征进行分类。理论上讲,人们可以利用所有提取到的特征去训练分类器,但这样面临着计算量的挑战。例如:对于一个 96X96 像素的图像,假设已经学习得到了400个特征,卷积核大小为8X8,卷积核步长为1,每一个特征和图像卷积后都会得到一个 (96 − 8 + 1) × (96 − 8 + 1) = 7921 维的卷积特征,由于有 400 个特征,所以每个图像都会得到一个 7921 × 400 = 3,168,400 维的卷积特征向量。学习一个拥有超过 3 百万特征输入的分类器十分不便,并且容易出现过拟合问题。
为了解决这个问题,首先回忆一下,我们之所以决定使用卷积后的特征是因为图像具有一种“静态性”的属性,这也就意味着在一个图像区域有用的特征极有可能在另一个区域同样适用。因此,为了描述大的图像,一个很自然的想法就是对不同位置的特征进行聚合统计,例如,人们可以计算图像一个区域上的某个特定特征的平均值 (或最大值)。这些概要统计特征不仅具有低得多的维度 (相比使用所有提取得到的特征),同时还会改善结果(不容易过拟合)。这种聚合的操作就叫做池化 (pooling),有时也称为平均池化或者最大池化 (取决于计算池化的方法)。
-------------------------------------------------------------------------------------------------------------------------------------
卷积层的进一步分析
假设输入图像为w1 * h1 * c1,w1表示宽度,h1表示高度,c1表示通道数(图像的深度),输出图像为w2 * h2 * c2
在卷积层中,n表示卷积核的个数,k*k表示卷积核大小,p表示扩充边缘,s表示卷积核步长,那么有:
w2 = (w1 + 2 * p - k) / s + 1
h2 = (h1 + 2 * p - k) / s + 1
c2 = n
每个滤波器的权值个数为k * k * c1,偏置的个数为1,所以每个滤波器有 k * k * c1 + 1个参数;
该卷积层总共需要训练的参数为( k * k * c1 + 1 ) * n,网络中的连接数为 ( k * k * c1 + 1 ) * n * w2 * h2

------------------------------------------------------------------------------------------------------------------------------------
感受野的计算
由上面的分析知道:output_size = (input_size + 2*padding - kernel_size) / stride + 1,进而可以推出:
input_size = (output_size -1)*stride +kernel_size - 2*padding
在计算感受野时,需要说明以下情况:
1)在第一层卷积层的输出特征图,感受野的大小等于滤波器的大小
2)深层卷积层的感受野的大小和它之前所有层的滤波器的大小、步长有关系
3)计算感受野大小时,忽略了图像边缘的影响,即不考虑padding的大小
综上所述,我们在计算感受野时,采用 top to down 的方式, 即先计算最深层在前一层上的感受野,然后逐渐传递到第一层,采用如下公式:
RF = 1 #待计算的feature map上的感受野大小
for layer in (top layer To down layer):
RF = ((RF -1)* stride) + kernel_size
Caffe的卷积层、池化层
layer {
name: "conv1"
type: "Convolution"
bottom: "data"
top: "conv1"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
convolution_param {
num_output: 20
kernel_size: 5
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
num_output: 卷积核的个数
kernel_size: 卷积核的大小,如果卷积核的长和宽不等,需要用kernel_h和kernel_w分别设定
stride: 卷积核的步长,默认为1。也可以用stride_h和stride_w来设置。
pad: 扩充边缘,默认为0,不扩充。 扩充的时候是左右、上下对称的,比如卷积核的大小为5*5,那么pad设置为2,则四个边缘都扩充2个像素,即宽度和高度都扩充了4个像素,这样卷积运算之后的特征图就不会变小。也可以通过pad_h和pad_w来分别设定。
weight_filler: 权值初始化
bias_filler: 偏置项的初始化
输入:n * c0 * w0 * h0
输出:n * c1 * w1 * h1,
c1是参数中的num_output,也就是生成的特征图的个数
w1=(w0 + 2*pad - kernel_size) / stride +1;
h1 =(h0 + 2*pad - kernel_size) / stride +1;
-------------------------------------------------------------------------------------------------------------------------------------
池化层的定义:
layer {
name: "pool1"
type: "Pooling"
bottom: "conv1"
top: "pool1"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}pool: 池化方法,默认为MAX。目前可用的方法有MAX, AVE, 或STOCHASTIC
pad: 和卷积层的pad的一样,进行边缘扩充,默认为0
stride: 池化的步长,默认为1。一般我们设置为2,即不重叠。也可以用stride_h和stride_w来设置。
pooling层的运算方法基本是和卷积层是一样的。
输入:n*c*w0*h0
输出:n*c*w1*h1
和卷积层的区别就是其中的c保持不变
w1=(w0 + 2*pad - kernel_size) / stride +1;
h1 =(h0 + 2*pad - kernel_size) / stride +1;
如果设置stride为2,前后两次卷积部分不重叠。100*100的特征图池化后,变成50*50
LeNet_5模型参数的分析
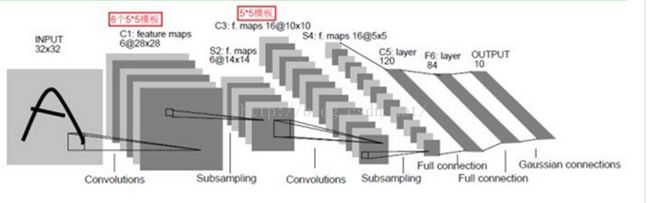
对于该模型的分析,主要参考其他博客,没有看过相关论文,可能存在一些错误,欢迎大家指出。
输入层:
输入图像为32*32大小,这比Mnist(一个公认的手写数据库)中最大的字母还大。这样做的原因是希望潜在的明显特征如笔画断电或角点能够出现在最高层特征监测子感受野的中心。
--------------------------------------------------------------------------------------------------------------------------------------------------------
C1层:
该层为卷积层,有6个28*28特征图。
输入图片大小: (32*32)*1
卷积窗大小: 5*5
卷积窗种类: 6
输出特征图数量: 6
输出特征图大小: 28*28 (32-5+1)
神经元数量: 4707 (28*28)*6
连接数: 122304 (5*5+1)*28*28*6
可训练参数: 156 (5*5+1)*6,每个滤波器有25个unit参数和一个bias参数
--------------------------------------------------------------------------------------------------------------------------------------------------------
该层为下采样层,有6个14*14的特征图,且特征图中的每个单元与C1中相对应特征图的2*2邻域相连接。S2层每个单元的4个输入相加,乘以一个可训练参数,再加上一个可训练偏置,并通过sigmoid函数计算最终结果。对于该层的参数分析, 没有理解好???
输入图片大小: (28*28)*6
卷积窗大小: 2*2
卷积窗种类: 6 ???
输出下采样图数量: 6
输出下采样图大小: 14*14 (28/2)
神经元数量: 1176 (14*14)*6
连接数: 2352 (1+1)*14*14*6 (5880 (2*2+1)*14*14*6 )
可训练参数: 12 (1+1)*6
--------------------------------------------------------------------------------------------------------------------------------------------------------
C3层:
该层为卷积层,它通过5x5的卷积核去卷积S2层,得到的特征图只有10x10个神经元,但是它有16种不同的卷积核,所以存在16个特征图。需要注意的是:C3中的每个特征图是连接到S2中的所有6个或者几个特征图的,表示本层的特征图是上一层提取到的特征图的不同组合(这个做法也并不是唯一的)。
C3中每个特征图由S2中所有6个或者几个特征图组合而成。为什么不把S2中的每个特征图连接到每个C3的特征图呢?原因有2点。第一,不完全的连接机制将连接的数量保持在合理的范围内。第二,也是最重要的,其破坏了网络的对称性。由于不同的特征图有不同的输入,所以迫使他们抽取不同的特征。
例如,存在的一个方式是:C3的前6个特征图以S2中3个相邻的特征图子集为输入,接下来的6个特征图以S2中4个相邻特征图子集为输入。然后的3个特征图以S2中不相邻的4个特征图子集为输入。最后一个特征图将S2中所有特征图为输入。这样C3层有1516个可训练参数和151600个连接,,如下图所示:

输入图片大小: (14*14)*6
卷积窗大小: 5*5
卷积窗种类: 16
输出特征图数量: 16
输出特征图大小: 10*10 (14-5+1)
神经元数量: 1600 (10*10)*16
连接数: 151600 1516*10*10
可训练参数: 1516 6*(3*25+1)+6*(4*25+1)+3*(4*25+1)+1*(6*25+1)
--------------------------------------------------------------------------------------------------------------------------------------------------------
S4层:
该层为下采样层,有16个5*5大小的特征图。特征图中的每个单元与C3中相应特征图的2*2邻域相连接,跟C1和S2之间的连接一样。
输入图片大小: (10*10)*16
卷积窗大小: 2*2
卷积窗种类: 16
输出下采样图数量: 16
输出下采样图大小: 5*5 10/2
神经元数量: 400 (5*5)*16
连接数: 800 (1+1)*5*5*16 (2000 (2*2+1)*5*5*16)
可训练参数: 32 (1+1)*16
--------------------------------------------------------------------------------------------------------------------------------------------------------
C5层:
该层为卷积层,有120个特征图。特征图中的每个单元与S4层的全部16个特征图的5*5邻域相连。由于S4层特征图的大小也为5*5(同滤波器大小一样),故C5特征图的大小为1*1,这构成了S4和C5之间的全连接。之所以仍将C5标示为卷积层,而非全相联层,是因为如果LeNet-5的输入变大,而其他的保持不变,那么此时特征图的维数就会比1*1大。
输入图片大小: (5*5)*16
卷积窗大小: 5*5
卷积窗种类: 120
输出特征图数量: 120
输出特征图大小: 1*1 (5-5+1)
神经元数量: 120 (1*1)*120
连接数: 48120 (5*5*16+1)*1*1*120
可训练参数: 48120 (5*5*16+1)*120
--------------------------------------------------------------------------------------------------------------------------------------------------------
F6层:
F6层有84个单元(之所以选这个数字的原因来自于输出层的设计),与C5层全相连。如同经典神经网络,F6层计算输入向量和权重向量之间的点积,再加上一个偏置,然后将其传递给sigmoid函数产生单元的一个状态。
输入图片大小: (1*1)*120
卷积窗大小: 1*1
卷积窗种类: 84
输出特征图数量: 1
输出特征图大小: 84
神经元数量: 84
连接数: 10164 120*84+84
可训练参数: 10164 120*84+84
--------------------------------------------------------------------------------------------------------------------------------------------------------
OUTPUT层:
输入图片大小: 1*84
输出特征图数量: 1*10
输出层由欧式径向基函数单元组成,每类一个单元,有84个输入。换句话说,每个输出RBF单元计算输入向量和参数向量之间的欧式距离。输入离参数向量越远,RBF输出的越大。一个RBF输出可以被理解为衡量输入模式和与RBF相关联类的一个模型的匹配程度的惩罚项。用概率术语来说,RBF输出可以被理解为F6层配置空间的高斯分布的负log-likelihood。给定一个输入模式,损失函数应能使得F6的配置与RBF参数向量(即模式的期望分类)足够接近。这些单元的参数是人工选取并保持固定的(至少初始时候如此)。这些参数向量的成分被设为-1或1。虽然这些参数可以以-1和1等概率的方式任选,或者构成一个纠错码,但是被设计成一个相应字符类的7*12大小(即84)的格式化图片。这种表示对识别单独的数字不是很有用,但是对识别可打印ASCII集中的字符串很有用。
使用这种分布编码而非更常用的“1 of N”编码用于产生输出的另一个原因是,当类别比较大的时候,非分布编码的效果比较差。原因是大多数时间非分布编码的输出必须为0。这使得用sigmoid单元很难实现。另一个原因是分类器不仅用于识别字母,也用于拒绝非字母。使用分布编码的RBF更适合该目标。因为与sigmoid不同,他们在输入空间的较好限制的区域内兴奋,而非典型模式更容易落到外边。
RBF参数向量起着F6层目标向量的角色。需要指出这些向量的成分是+1或-1,这正好在F6 sigmoid的范围内,因此可以防止sigmoid函数饱和。实际上,+1和-1是sigmoid函数的最大弯曲的点处。这使得F6单元运行在最大非线性范围内。必须避免sigmoid函数的饱和,因为这将会导致损失函数较慢的收敛和病态问题。