推荐算法学习2-MXNET 实现movielen 融合个性化推荐
上篇文章记录了使用矩阵分解的方法来做个性化推荐。本篇文章参考了 http://book.paddlepaddle.org/08.recommender_system/ 上面的融合推荐算法,由于本人目前的精力放在学习MXNET上,所以将其用mxnet进行改写了。由于时间关系,暂时省略了原算法中对title的向量提取,预计下一篇会补充对title的CNN向量提取。
1. 数据准备
MovieLens 百万数据集(ml-1m)。ml-1m 数据集包含了 6,000 位用户对 4,000 部电影的 1,000,000 条评价(评分范围 1~5 分,均为整数),由 GroupLens Research 实验室搜集整理。提示:原数据的分割符是'::', 可以用文本工具打开,替换成','或者'\t', 这样在使用pandas加载的时候能使用C库,否则加载数据非常慢。
1)movies.dat 每列分别是movieid, title, categories, 例如:1Toy Story (1995) Animation|Children's|Comedy。
需要注意的是电影类型也就是电影标签,一部电影可以有多个标签。比如上面的电影,类型是三种Animation,Children's,Comedy。
2)ratings.dat 每列分别是userid, movieid, score, time-stamp,表示用户对电影的评分。最后一列时间数据本例未使用
3)users.dat 是记录用户profile,分别是userid, gender, age 年龄段, job 职业类型,最后一列不知道是什么东东,本例未使用。
2. 自定义 DataIter和DataBatch,用于装载训练数据
跟上篇案例的类似,只是做了一点小变化,data.append(mx.nd.array(np.array(_data.tolist()),self.ctx))
import mxnet as mx
import numpy as np
class SimpleBatch(object):
def __init__(self, data, label, pad=0):
self.data = data
self.label = label
self.pad = pad
class SimpleBatch(object):
def __init__(self, data, label, pad=0):
self.data = data
self.label = label
self.pad = pad
class CustDataIter2:
def __init__(self, data_names, data_gen, data_shape,
label_names, label_gen, label_shape,ctx, batch_size,total_batches):
self.data_names = data_names
self.label_names = label_names
self.data_gen = data_gen
self.label_gen = label_gen
self.data_shape = data_shape
self.label_shape = label_shape
self.batch_size = batch_size
self.total_batches = total_batches
self.cur_batch = 0
self.ctx = ctx
def __iter__(self):
return self
def reset(self):
self.cur_batch = 0
def __next__(self):
return self.next()
@property
def provide_data(self):
return zip(self.data_names,self.data_shape)
@property
def provide_label(self):
return zip(self.label_names,self.label_shape)
def next(self):
if self.cur_batch < self.total_batches:
data = []
for tdata in self.data_gen:
_data = tdata[self.cur_batch*self.batch_size:(self.cur_batch+1)*self.batch_size]
data.append(mx.nd.array(np.array(_data.tolist()),self.ctx))
assert len(data) > 0, "Empty batch data."
label = []
for tlabel in self.label_gen:
_label = tlabel[self.cur_batch*self.batch_size:(self.cur_batch+1)*self.batch_size]
label.append(mx.nd.array(_label,self.ctx))
assert len(label) > 0, "Empty batch label."
self.cur_batch += 1
# print('Return batch %d' % self.cur_batch)
return SimpleBatch(data, label)
else:
raise StopIteration3. 加载训练数据
分别有3个文件要装入,性别不是int型,所以需要进行变换。def LoadRatingData(fname,delimiter='::'):
df = pd.read_csv(fname,header=None,delimiter=delimiter,names=['userid','itemid','score','timestamp'])
return df
def gendercoding(x):
if x =='M':
return 2
else:
return 1
def LoadUserData(fname,delimiter='::'):
df = pd.read_csv(fname,header=None,delimiter=delimiter,names=['userid','gender','age','job','other'],index_col=0)
df['gender'] = df['gender'].apply(gendercoding)
return df
def LoadItemData(fname,delimiter='::'):
df = pd.read_csv(fname,header=None,delimiter=delimiter,names=['itemid','title','cat'],index_col=0)
return df4. encoding 电影类型
前面提到电影的类型是string,并且是多个值,例如Animation|Children's|Comedy。所以需要把这个值映射成一个向量来表示。
首先建立词典:
def build_categories_dic(cate):
cat_dic={}
cat_index = {}
cat_vocab = []
index = 0
for s in cate:
s = s.split('|')
for x in s:
if cat_dic.get(x) == None:
cat_dic[x]=1
cat_vocab.append(x)
cat_index[x]=index
index += 1
else:
cat_dic[x] += 1
return (cat_dic,cat_vocab,cat_index)
然后把类型string,转换成对应的词典的index,再使用sklearn包的oneHotEncoder转成0,1编码的向量
def featureTags(catid):
cat_dic,cat_vocab,cat_index = build_categories_dic(catid)
encoded_cat=[]
for cat in catid:
s = cat.split('|')
t = []
for tag in s:
index = cat_index.get(tag)
t.append(index)
encoded_cat.append(t)
df_cat = pd.DataFrame(encoded_cat).fillna(0)
return df_cat
def encodeTag(df):
catid = df['cat']
itemid = df.index
catfeatures = featureTags(catid).as_matrix()
enc = preprocessing.OneHotEncoder(sparse=False)
x_out = enc.fit_transform(catfeatures)
s = [i for i in x_out]
return pd.Series(s,index=itemid,name='encoded_cat')5. 定义网络
参考原文的算法,暂时忽略了title这个属性
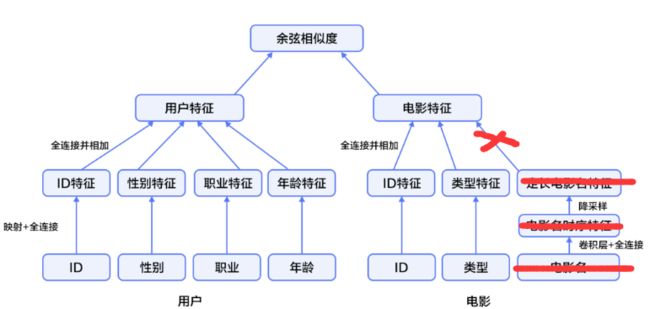
余弦相似度损失函数,并且rescale到1-5:
def calc_cos_sim(a,b,min=1,max=5):
x = mx.symbol.sum_axis( a*b, axis = 1)
y = mx.symbol.sqrt(mx.symbol.sum_axis( mx.symbol.square(a), axis = 1)) * mx.symbol.sqrt(mx.symbol.sum_axis( mx.symbol.square(b), axis = 1))
cos = x/y
rescale = cos*(max-min)+min
return rescale
定义网络结构
def get_one_layer_mlp( max_userid, max_itemid,max_gender,max_age, max_job, k=64,):
# user profile
userid = mx.symbol.Variable('userid')
gender = mx.symbol.Variable('gender')
age = mx.symbol.Variable('age')
job = mx.symbol.Variable('job')
#times profile
itemid = mx.symbol.Variable('itemid')
# title = mx.symbol.Variable('title')
cat = mx.symbol.Variable('cat')
score = mx.symbol.Variable('score')
# user latent features
userid = mx.symbol.Embedding(data = userid, input_dim = max_userid, output_dim = k,name='userid_Embedding')
userid = mx.symbol.FullyConnected(data = userid, num_hidden = k)
userid = mx.symbol.Activation(data = userid, act_type="relu")
gender = mx.symbol.Embedding(data = gender, input_dim = max_gender, output_dim = k/4,name='gender_Embedding')
gender = mx.symbol.FullyConnected(data = gender, num_hidden = k/4)
gender = mx.symbol.Activation(data = gender, act_type="relu")
age = mx.symbol.Embedding(data = age, input_dim = max_age, output_dim = k/4,name='age_Embedding')
age = mx.symbol.FullyConnected(data =age, num_hidden = k/4)
age = mx.symbol.Activation(data = age, act_type="relu")
job = mx.symbol.Embedding(data = job, input_dim = max_job, output_dim = k/2,name='job_Embedding')
job = mx.symbol.FullyConnected(data =job, num_hidden = k/2)
job = mx.symbol.Activation(data = job, act_type="relu")
user = mx.symbol.concat(userid,gender,age,job,dim=1)
# item latent features
itemid = mx.symbol.Embedding(data = itemid, input_dim = max_itemid, output_dim = k,name='itemid_Embedding')
itemid = mx.symbol.FullyConnected(data = itemid, num_hidden = k)
itemid = mx.symbol.Activation(data = itemid, act_type="relu")
cat = mx.symbol.FullyConnected(data = cat, num_hidden = k,name='cat_Fc')
item = mx.symbol.concat(itemid,cat,dim=1)
pred = calc_cos_sim(user,item,1,5)
pred = mx.symbol.Flatten(data = pred)
# loss layer
pred = mx.symbol.LinearRegressionOutput(data = pred, label = score)
return pred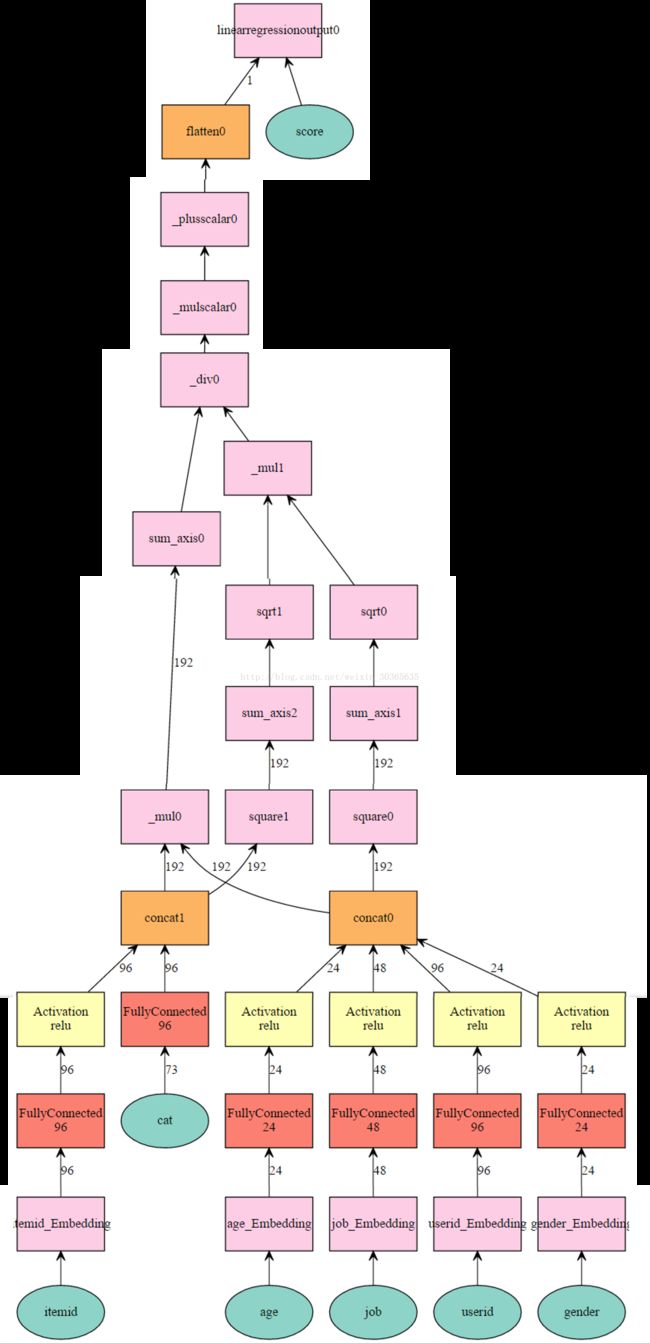
6. 训练函数
def train(network,data_train_iter,data_valid_iter, context, num_epoch,learning, learning_rate):
logging.getLogger().info('network debug:%s',network.debug_str())
model = mx.mod.Module(
symbol = network,
context=context,
data_names=['userid', 'gender','age','job','itemid','cat'],
label_names=['score']
)
model.fit(train_data = data_train_iter,
eval_data =data_valid_iter,
optimizer =learning,
optimizer_params={'learning_rate':learning_rate},
eval_metric ='RMSE',
num_epoch = num_epoch,
)
return model
def trainingModel():
TRAIN_DIR = 'C:/Users/chuanxie/PycharmProjects/mxnetlearn/data/movie/'
ratingdf = LoadRatingData(TRAIN_DIR+'ml-1m/ratings.dat',delimiter='\t')
userdf = LoadUserData(TRAIN_DIR+'ml-1m/users.dat',delimiter='\t')
itemdf = LoadItemData(TRAIN_DIR+'ml-1m/movies.dat',delimiter='\t')
np_encodedcat = encodeTag(itemdf)
print ratingdf.shape,np_encodedcat.shape
fulldf = ratingdf.join(userdf,on='userid').join(itemdf,on='itemid').join(np_encodedcat,on='itemid')
'''reconstruct series to dataframe'''
matrix_encoded_cat = fulldf['encoded_cat'].as_matrix()
df_encoded_cat = np.array(matrix_encoded_cat.tolist())
print df_encoded_cat.shape
data = np.array([fulldf['userid'],fulldf['gender'],fulldf['age'],fulldf['job'],fulldf['itemid'],fulldf['encoded_cat']])
print data.shape
label = np.array([fulldf['score']])
context = mx.gpu()
BATCH_SIZE = 16000
num_epoch = 100
trainIter = CustDataIter2(['userid', 'gender','age','job','itemid','cat'],data,
[(BATCH_SIZE,),(BATCH_SIZE,),(BATCH_SIZE,),(BATCH_SIZE,),(BATCH_SIZE,),(BATCH_SIZE,df_encoded_cat.shape[1])],
['score'],label,[(BATCH_SIZE,)],context,BATCH_SIZE,data.shape[1]/BATCH_SIZE)
max_userid = pd.Series(fulldf['userid']).max()
max_itemid = pd.Series(fulldf['itemid']).max()
max_gender = pd.Series(fulldf['gender']).max()
max_age = pd.Series(fulldf['age']).max()
max_job = pd.Series(fulldf['job']).max()
net =get_one_layer_mlp( max_userid=max_userid, max_itemid=max_itemid,max_gender=max_gender,
max_age = max_age , max_job = max_job, k=96)
mx.viz.plot_network(net,shape={'userid':(128,),'gender':(128,),'age':(128,),'job':(128,),'itemid':(128,),'cat':(128,73)})
##Train module
train(net,trainIter,None,context,num_epoch=num_epoch,learning = 'adam',learning_rate=0.001)
if __name__ == '__main__':
trainingModel()7. 运行结果
迭代100次就能把平均根方差降到0.7X,而前一篇文章单纯使用矩阵分解的算法迭代了1000次也只能达到0.9X,可见融合模型不仅加入了客户的行为数据,还融合了客户的自然属性,电影的自然属性,数据更加全面,因而准确度越高
INFO:root:Epoch[91] Train-RMSE=0.765856
INFO:root:Epoch[91] Time cost=7.528
INFO:root:Epoch[92] Train-RMSE=0.765861
INFO:root:Epoch[92] Time cost=7.575
INFO:root:Epoch[93] Train-RMSE=0.765705
INFO:root:Epoch[93] Time cost=7.794
INFO:root:Epoch[94] Train-RMSE=0.765217
INFO:root:Epoch[94] Time cost=7.455
INFO:root:Epoch[95] Train-RMSE=0.765055
INFO:root:Epoch[95] Time cost=7.401
INFO:root:Epoch[96] Train-RMSE=0.765331
INFO:root:Epoch[96] Time cost=7.409
INFO:root:Epoch[97] Train-RMSE=0.765364
INFO:root:Epoch[97] Time cost=7.401
INFO:root:Epoch[98] Train-RMSE=0.765842
INFO:root:Epoch[98] Time cost=7.425
INFO:root:Epoch[99] Train-RMSE=0.766367
INFO:root:Epoch[99] Time cost=7.445
INFO:root:Epoch[91] Time cost=7.528
INFO:root:Epoch[92] Train-RMSE=0.765861
INFO:root:Epoch[92] Time cost=7.575
INFO:root:Epoch[93] Train-RMSE=0.765705
INFO:root:Epoch[93] Time cost=7.794
INFO:root:Epoch[94] Train-RMSE=0.765217
INFO:root:Epoch[94] Time cost=7.455
INFO:root:Epoch[95] Train-RMSE=0.765055
INFO:root:Epoch[95] Time cost=7.401
INFO:root:Epoch[96] Train-RMSE=0.765331
INFO:root:Epoch[96] Time cost=7.409
INFO:root:Epoch[97] Train-RMSE=0.765364
INFO:root:Epoch[97] Time cost=7.401
INFO:root:Epoch[98] Train-RMSE=0.765842
INFO:root:Epoch[98] Time cost=7.425
INFO:root:Epoch[99] Train-RMSE=0.766367
INFO:root:Epoch[99] Time cost=7.445