深度学习-BP神经网络(python3代码实现)
BP神经网络
哈尔滨工程大学-537
一、试验数据
在试验开始前必定要先导入所需要的python库,%matplotlib inline是为了使绘制的图形能够显示在浏览器上。
import numpy as np
import matplotlib.pyplot as plt
import random
%matplotlib inline之后我们需要产生一些难以进行线性分类的数据集,这里直接copy斯坦福CS231n课程里的螺旋数据集,代码如下:
N = 100 # number of points per class
D = 2 # dimensionality
K = 3 # number of classes
X = np.zeros((N * K, D)) # data matrix (each row = single example)
y = np.zeros(N * K, dtype='uint8') # class labels
for j in range(K):
ix = list(range(N*j, N*(j + 1)))
r = np.linspace(0.0, 1, N) # radius
t = np.linspace(j*4, (j+1)*4, N) + np.random.randn(N)*0.2 # theta
X[ix] = np.c_[r*np.sin(t), r*np.cos(t)]
y[ix] = j
plt.scatter(X[:, 0], X[:, 1], c=y, s=40, cmap=plt.cm.gist_rainbow)
plt.show()我认为没有必要纠结于这段代码里的具体内容,不然就偏离了主题,总之就是通过一些奇奇怪怪的函数来画出这么一个布满随机点的图形。
所绘制的图形如下图所示:

图中共有300个点,每一个点代表数据集中的一个样本点,横坐标和纵坐标分别作为样本的两个特征,样本点一共分为三种类型,红色、紫色和绿色。如果用矩阵来表示的话就应该是这样的:
| 样本点 | 特征1 | 特征2 | 类标签 |
|---|---|---|---|
| 1 | -0.753 | -0.745 | 红色 |
| 2 | -0.754 | 0.501 | 紫色 |
| 3 | 0.752 | 0.258 | 绿色 |
| … | … | … | … |
二、softmax线性分类器
在开始神经网络之前,先训练一个softmax线性分类器。
所谓softmax,举例来说,就是有三个数字,分别为3、4、7,如果取max,那么每次都会取到7,因为7永远是三个数里最大的,但是把它们softmax一下,就映射为三个概率0.27、0.28、0.45,这样取到7的概率最大,但是也有取到其他两个数的可能。这样,我们取的就不是max值,而是softmax值,没有取max值那么硬。
而这三个数字是如何通过softmax映射为三个概率值的,即softmax函数是什么样的,接下来会提到。
而既然是线性分类器,必然离不开经典的公式 y=wx+b y = w x + b 。所以,就先初始化一下 w w 和 b b 吧,代码如下:
# initialize parameters randomly
W = 0.01 * np.random.randn(D,K)
b = np.zeros((1,K))这里的random库下的randn()函数是生成服从标准正态分布的随机数,这不同于生成在某一区间内均匀分布的随机数。生成D行K列,即2行3列。而偏置是1行3列的零向量。
权值 w w 和偏置 b b 打印出来如下:

由于这是一个线性分类器,所以只需做简单的矩阵乘法,即可得到各个类别的分数。
# compute class scores for a linear classifier
scores = np.dot(X, W) + b这里将300行2列的矩阵与2行3列的矩阵相乘,再加上偏置,得到300行3列的矩阵。每行代表一个样本点,共300个样本点,每列代表样本点对应各个类别的分数,共三个类别。
将score矩阵部分打印出来,如下图:
接下来的一个关键因素就是损失函数,我们需要用它来计算我们的损失,即预测结果和真实情况相差多少。在这里,我们希望正确的类别应该比其他类别有更高的分数,若确实如此,则损失应该很低,否则损失应该很高。量化这种直觉的方法有很多种,但在这个例子中我们可以使用与softmax分类器相关的交叉熵损失。公式如下:
公式其实比较直观,比如对某一个样本 i 预测,正确类别的概率值 prob(i) p r o b ( i ) 越大,损失就越小,反之其值越小,损失就越大。由于概率值在0和1之间,所以保证了 log l o g 函数自变量的取值范围(斯坦福CS231n上面是如此写交叉熵的,可是和别的资料都不一样)。
将每个样本的损失累加在一起再除以样本个数,得到训练样本的平均交叉熵损失: 1N∑iLi 1 N ∑ i L i
而完整的softmax分类器的损失则定义为:
公式后半部分为正则化损失,比如某个点的特征为[1, 1],而此时有两组不同的权重向量 w1 w 1 =[1, 0], w2 w 2 =[0.5, 0.5],与两组不同的权重分别做内积的结果相等,都为1。可是加上正则化损失项后,很明显 0.5∗0.5+0.5∗0.5<1∗1 0.5 ∗ 0.5 + 0.5 ∗ 0.5 < 1 ∗ 1 ,所以选择 w2 w 2 作为权重整体的损失更小。起作用在于增强泛化能力,去除权重的不确定性。
由之前得到的分数矩阵score,可以计算得到每个样本对应各个类别的概率值。这里就用到了之前所说的softmax,把三个数,通过softmax函数映射为归一化的三个概率,softmax公式如下:
例如:某个样本 i 对应各个类别的分值分别为(3, 3, 8),则该样本对应各个类别的概率值为 (e3e3+e3+e8,e3e3+e3+e8,e8e3+e3+e8) ( e 3 e 3 + e 3 + e 8 , e 3 e 3 + e 3 + e 8 , e 8 e 3 + e 3 + e 8 ) 。
实现代码如下:
num_examples = X.shape[0]
# get unnormalized probabilities
exp_scores = np.exp(scores)
# normalize them for each example
probs = exp_scores / np.sum(exp_scores, axis=1, keepdims=True)现在我们有了一个300行3列的概率矩阵,由于已经进行了归一化处理,所以每一行的三个概率值相加和为1。接下来将每个样本的正确类别的概率提取出来,并做 −log − l o g 映射。例如:第一个样本对应各个类别的概率为[0.2, 0.3, 0.5],而第一个样本的类别标签为1,则取出第1列的概率值0.3进行 −log − l o g 映射。
代码如下:
corect_logprobs = -np.log(probs[range(num_examples),y])得到了一个包含300个元素的一维数组,每个元素都是相应样本的正确类别的概率值。
之后根据上文所述公式计算完整的损失,代码如下:
# compute the loss: average cross-entropy loss and regularization
data_loss = np.sum(corect_logprobs)/num_examples
reg_loss = 0.5 * reg * np.sum(W * W)
loss = data_loss + reg_loss当然了这里的 reg 即公式中的 λ λ 在实际运行代码的时候是需要赋值的。先随意将其赋值为1.5,打印loss,可以得到此时的loss值为:
1.099367068027489
即使改变reg值,loss值变化也不大,这是因为我们给权重的初始值非常小,还记得下图是我们随机生成的权重矩阵和偏置向量吧。
某样本的两个特征,无论是和权重矩阵的第一列内积,还是和第二列内积,还是和第三列,所得的结果都差不了多少。所以最后算得的该样本属于各个类别的概率值应该都是三分之一左右。
这显然很不理想,我们希望能提升正确类别的概率值,即降低loss的值。
那么如何降低损失值,必然又要用到梯度下降。要想找到 w w 和 b b 取什么值的时候,最终的loss值能最小。就得对它们分别求导,用梯度下降找到导数为0的点,即为极小值点。
先计算 L=1N∑iLi+12λ∑k∑lW2k,l L = 1 N ∑ i L i + 1 2 λ ∑ k ∑ l W k , l 2 加号之前部分的导数。
首先让损失loss对分数score求导,得到 ∂损失∂分数=∂损失∂概率.∂概率∂分数 ∂ 损 失 ∂ 分 数 = ∂ 损 失 ∂ 概 率 . ∂ 概 率 ∂ 分 数 ,这一点由高数知识就可得到。
这里损失loss由正确类别的概率值决定,而正确类别的概率值由各个类别分数共同决定,所以求得应分别是对三个分数的导数,为了不偏离主题,求导过程略掉,总之最后损失loss对各个分数的导数为
简单举例来说就是:某一个样本对应各个类别的概率为[0.2, 0.3, 0.5],而该样本的类别标签为1,即0.3是正确类别的概率,于是该样本的损失值loss对于分数score的导数为[0.2, -0.7, 0.5],即正确类别的概率值减1,其他类别的概率值不变,而从直觉上来想,也确实应该是这样的。
显然中间那列的导数值是负数,所以增加中间那列的score值,减少两边的score值,可以使得该样本的loss值降低。
以下代码实现导数表达式:
dscores = probs
dscores[range(num_examples),y] -= 1
dscores /= num_examples最后除以样本个数,因为之前计算用到的是样本的平均损失,所以这里也要做平均处理(个人这么理解/(ㄒoㄒ)/~~)。
现在得到了 ∂损失∂分数 ∂ 损 失 ∂ 分 数 ,我们想要得到的是 ∂损失∂权重 ∂ 损 失 ∂ 权 重 ,易知 ∂损失∂分数.∂分数∂权重=∂损失∂权重 ∂ 损 失 ∂ 分 数 . ∂ 分 数 ∂ 权 重 = ∂ 损 失 ∂ 权 重 ,故需要求得 ∂分数∂权重 ∂ 分 数 ∂ 权 重 ,对任意一个样本来说,[特征1, 特征2]与权重向量各列分别做内积得到三个分数score。因此三个分数各自对影响自己的权重求导,得到的就是[特征1,特征2],而考虑到所有样本的话,三个分数对权重求导结果就是样本矩阵X。故将样本矩阵X与之前所得的dscores矩阵相乘。
而每个分数对偏置的求导自然是1了,考虑到300个样本,就是由300个1为元素的向量与dscores矩阵相乘。
故代码如下:
dW = np.dot(X.T, dscores)
db = np.sum(dscores, axis=0, keepdims=True)
dW += reg*W # don't forget the regularization gradient完整的损失对权重的求导还要加上正则项对权重的求导结果。这里的reg应设置为与之前相同的值。
最后对权值和偏置进行更新
# perform a parameter update
W += -step_size * dW
b += -step_size * db当然了,只更新一次肯定是不够了,所以将上面的代码都放在一个循环中,迭代200次。代码如下:
#Train a Linear Classifier
# initialize parameters randomly
W = 0.01 * np.random.randn(D,K)
b = np.zeros((1,K))
# some hyperparameters
step_size = 1e-0
reg = 1e-3 # regularization strength
# gradient descent loop
num_examples = X.shape[0]
for i in range(200):
# evaluate class scores, [N x K]
scores = np.dot(X, W) + b
# compute the class probabilities
exp_scores = np.exp(scores)
probs = exp_scores / np.sum(exp_scores, axis=1, keepdims=True) # [N x K]
# compute the loss: average cross-entropy loss and regularization
corect_logprobs = -np.log(probs[range(num_examples),y])
data_loss = np.sum(corect_logprobs)/num_examples
reg_loss = 0.5 * reg * np.sum(W * W)
loss = data_loss + reg_loss
if i % 10 == 0:
print ("iteration %d: loss %f" % (i, loss))
# compute the gradient on scores
dscores = probs
dscores[range(num_examples),y] -= 1
dscores /= num_examples
# backpropate the gradient to the parameters (W,b)
dW = np.dot(X.T, dscores)
db = np.sum(dscores, axis=0, keepdims=True)
dW += reg*W # regularization gradient
# perform a parameter update
W += -step_size * dW
b += -step_size * db迭代200次,将10的被数次的损失函数值打印出来,结果如下:

最后计算一下用更新后的权值和偏置预测出来的结果的精度,代码如下:
# evaluate training set accuracy
scores = np.dot(X, W) + b
predicted_class = np.argmax(scores, axis=1)
print('training accuracy: %.2f' % (np.mean(predicted_class == y))) 得到的精度结果为:0.50
心累,这不就是随机瞎蒙吗,这就是用线性分类器给线性不可分的数据进行分类的后果……
三、BP神经网络
显然,对这个数据集来说,线性分类器是不够的,那么我们就需要使用神经网络来进行分类了。
首先整理一下思路,先通过一张图来表达一下softmax线性分类器的工作原理。
由图可以看出,把每个样本的特征作为输入,每个样本的特征都加上权值和偏置进行运算之后得到输出,这个输出是三个分数,把这个三个分数再通过激活函数即softmax函数映射为三个概率,这样就得到了预测结果,把预测结果和真实情况作为输入,通过损失函数算出预测结果和真实情况相差多少。把300样本都这么算一下,看看平均损失是多少。然后想办法尽快降低这个损失。于是就得通过修改权值和偏置来使这个损失降低,
那么神经网络和这个softmax线性分类器有什么不同呢,不同就是多了一层隐藏层。也就是每个样本的特征加上权值和偏置进行运算之后得到的输出,再加上一次权值和偏置进行运算,然后得到的结果,再通过激活函数进行运算。如下图所示:
首先初始化参数,增加了一个有一百个神经元的隐藏层,所以需要初始化的权重和偏置的数量肯定是增多了。这里初始化了两套权重和偏置 W,b W , b ,分别为隐藏层的权重和偏置,以及输出层的权重和偏置 W2,b2 W 2 , b 2 ,代码如下:
# initialize parameters randomly
h = 100 # size of hidden layer
W = 0.01 * np.random.randn(D,h)
b = np.zeros((1,h))
W2 = 0.01 * np.random.randn(h,K)
b2 = np.zeros((1,K))初始化2行100列的权重和1行100列的偏置,用来与300个样本的特征做计算,得到300行100列的结果。再初始化100行3列的权重和1行3列的偏置,用来与之前所得的300行100列的结果再做运算,并得到300行3列的分数矩阵。
接下来编写由特征矩阵得到分数矩阵的代码,首先定义每个隐藏层神经元的激活函数,在这里使用ReLu函数作为隐藏层神经元的激活函数,ReLu函数的图像如下图所示:
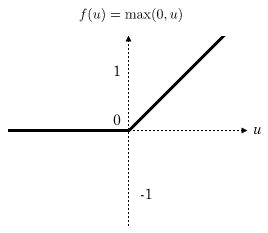
函数表达式为 ReLu(x)=max{0,x} R e L u ( x ) = m a x { 0 , x } ,即取0和自变量之间的最大值。
# evaluate class scores with a 2-layer Neural Network
hidden_layer = np.maximum(0, np.dot(X, W) + b) # note, ReLU activation
scores = np.dot(hidden_layer, W2) + b2之后的操作和softmax线性分类器没什么区别,将分数矩阵通过softmax映射为概率矩阵,然后计算平均损失和正则损失,再将二者相加。
num_examples = X.shape[0]
# get unnormalized probabilities
exp_scores = np.exp(scores)
# normalize them for each example
probs = exp_scores / np.sum(exp_scores, axis=1, keepdims=True)
corect_logprobs = -np.log(probs[range(num_examples),y])
# compute the loss: average cross-entropy loss and regularization
data_loss = np.sum(corect_logprobs)/num_examples
reg_loss = 0.5 * 2 * np.sum(W * W)
loss = data_loss + reg_loss然后还是和softmax线性分类器一样,要想计算 ∂分数∂输出层的权重 ∂ 分 数 ∂ 输 出 层 的 权 重 以及 ∂分数∂输出层的偏置 ∂ 分 数 ∂ 输 出 层 的 偏 置 ,就需要先计算损失对分数的导数 ∂损失∂分数 ∂ 损 失 ∂ 分 数
dscores = probs
dscores[range(num_examples),y] -= 1
dscores /= num_examples而接下来,与softmax线性分类器不同,softmax线性分类器的分数是由特征和权重进行运算得到的,而该神经网络的分数是由隐藏层的输出结果和输出层的权重、偏置进行运算得到的。所以这里 ∂分数∂输出层的权重 ∂ 分 数 ∂ 输 出 层 的 权 重 应该为隐藏层的输出矩阵。而 ∂分数∂输出层的偏置 ∂ 分 数 ∂ 输 出 层 的 偏 置 仍然为全是1的向量。所以损失对输出层的权重、输出层的偏置求导代码如下:
# backpropate the gradient to the parameters
# first backprop into parameters W2 and b2
dW2 = np.dot(hidden_layer.T, dscores)
db2 = np.sum(dscores, axis=0, keepdims=True)而 ∂损失∂隐藏层的权重=∂损失∂隐藏层的输出.∂隐藏层的输出∂隐藏层的权重 ∂ 损 失 ∂ 隐 藏 层 的 权 重 = ∂ 损 失 ∂ 隐 藏 层 的 输 出 . ∂ 隐 藏 层 的 输 出 ∂ 隐 藏 层 的 权 重 ,于是就需要先求得 ∂损失∂隐藏层的输出 ∂ 损 失 ∂ 隐 藏 层 的 输 出 ,而 ∂损失∂隐藏层的输出=∂损失∂分数.∂分数∂隐藏层的输出 ∂ 损 失 ∂ 隐 藏 层 的 输 出 = ∂ 损 失 ∂ 分 数 . ∂ 分 数 ∂ 隐 藏 层 的 输 出 。
而由于分数是由隐藏层的输出和输出层的权重加上偏置进行运算得到的,所以 ∂分数∂隐藏层的输出 ∂ 分 数 ∂ 隐 藏 层 的 输 出 应该为输出层的权重矩阵。故 ∂损失∂隐藏层的输出 ∂ 损 失 ∂ 隐 藏 层 的 输 出 代码如下:
dhidden = np.dot(dscores, W2.T)而 ∂隐藏层的输出∂隐藏层的权重=∂隐藏层的输出∂ReLu函数输入值.∂ReLu函数输入值∂隐藏层权重 ∂ 隐 藏 层 的 输 出 ∂ 隐 藏 层 的 权 重 = ∂ 隐 藏 层 的 输 出 ∂ R e L u 函 数 输 入 值 . ∂ R e L u 函 数 输 入 值 ∂ 隐 藏 层 权 重 ,而 ∂隐藏层的输出∂ReLu函数输入值 ∂ 隐 藏 层 的 输 出 ∂ R e L u 函 数 输 入 值 很显然,隐藏层的输出大于0的,对函数输入值的导数是其本身,隐藏层的输出小于等于0的,对函数输入值的导数是0。故 ∂隐藏层的输出∂RelU函数输入值 ∂ 隐 藏 层 的 输 出 ∂ R e l U 函 数 输 入 值 的代码应该如下:
# backprop the ReLU non-linearity
dhidden[hidden_layer <= 0] = 0
所以 ∂隐藏层的输出∂隐藏层的权重 ∂ 隐 藏 层 的 输 出 ∂ 隐 藏 层 的 权 重 以及 ∂隐藏层的输出∂隐藏层的偏置 ∂ 隐 藏 层 的 输 出 ∂ 隐 藏 层 的 偏 置 的代码如下:
# finally into W,b
dW = np.dot(X.T, dhidden)
db = np.sum(dhidden, axis=0, keepdims=True)现在有了损失对各层权重、偏置的导数,即 dW,db,dW2,db2 d W , d b , d W 2 , d b 2 ,就可以通过循环迭代来更新各层的权重和偏置了。
这次将涉及神经网络的所有代码都整理到一起,代码如下:
# initialize parameters randomly
h = 100 # size of hidden layer
W = 0.01 * np.random.randn(D,h)
b = np.zeros((1,h))
W2 = 0.01 * np.random.randn(h,K)
b2 = np.zeros((1,K))
# some hyperparameters
step_size = 1e-0
reg = 1e-3 # regularization strength
# gradient descent loop
num_examples = X.shape[0]
for i in range(10000):
# evaluate class scores, [N x K]
hidden_layer = np.maximum(0, np.dot(X, W) + b) # note, ReLU activation
scores = np.dot(hidden_layer, W2) + b2
# compute the class probabilities
exp_scores = np.exp(scores)
probs = exp_scores / np.sum(exp_scores, axis=1, keepdims=True) # [N x K]
# compute the loss: average cross-entropy loss and regularization
corect_logprobs = -np.log(probs[range(num_examples),y])
data_loss = np.sum(corect_logprobs)/num_examples
reg_loss = 0.5 * reg * np.sum(W * W) + 0.5 * reg * np.sum(W2 * W2)
loss = data_loss + reg_loss
if i % 1000 == 0:
print("iteration %d: loss %f" % (i, loss))
# compute the gradient on scores
dscores = probs
dscores[range(num_examples),y] -= 1
dscores /= num_examples
# backpropate the gradient to the parameters
# first backprop into parameters W2 and b2
dW2 = np.dot(hidden_layer.T, dscores)
db2 = np.sum(dscores, axis=0, keepdims=True)
# next backprop into hidden layer
dhidden = np.dot(dscores, W2.T)
# backprop the ReLU non-linearity
dhidden[hidden_layer <= 0] = 0
# finally into W,b
dW = np.dot(X.T, dhidden)
db = np.sum(dhidden, axis=0, keepdims=True)
# add regularization gradient contribution
dW2 += reg * W2
dW += reg * W
# perform a parameter update
W += -step_size * dW
b += -step_size * db
W2 += -step_size * dW2
b2 += -step_size * db2运行代码结果如下:
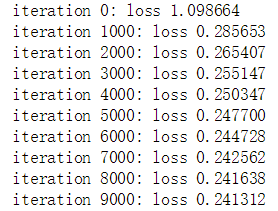
迭代了10000次,最后的损失降低为0.241312。
再来打印一下精度:
# evaluate training set accuracy
hidden_layer = np.maximum(0, np.dot(X, W) + b)
scores = np.dot(hidden_layer, W2) + b2
predicted_class = np.argmax(scores, axis=1)
print('training accuracy: %.2f' % (np.mean(predicted_class == y)))可以得到最后的精度为:0.98
可以说最终得到了比较理想的精确度,事实证明BP神经网络在某些情况下比单纯的线性分类器的效果要好的多。上文通过了一张图直观的了解到softmax线性分类器的工作原理。那就再通过下面这张图,直观、形象的了解一下全连接的前馈反向传播传播神经网络的工作原理吧。
多了一层隐藏层,其他的没啥不同,这么看感觉BP神经网络还算比较好理解的哈。