聊一下“深度学习”的基本思想

深度学习这两年非常火热,带动人工智能新一轮热潮。这两天在图像之别、自然语言分析、语音识别等方面乃至围棋方面,之所以能够有突破完全是因为深度学习的功劳。很多数据分析、数据挖掘的相关从业者都会或多或少的关注“深度学习”,乃至尝试将深度学习应用到自身工作相关的领域中。比如,我们在电信行业耕耘过多年,自然也会想深度学习是否可以应用到精确营销、精确管理等方面。
想借此文聊一下“深度学习”的基本思想,希望能够给相关行业的数据分析人士一些启示。
此文较长,这是因为深度学习的基本思路,不是三眼两语可以讲清楚的,读完要考验同学们的耐心,主要包括以下几个部分内容:
(1)因为深度学习与特征工程紧密联系一起的,因此需要先简单回顾特征工程的内容;
(2)以MINIST为例介绍简单图像的特征提取和分类识别方法,让大家理解最简单的图像特征提取和建模方法,以及和数据建模场景的一些初步差异;
(3)传统图像识别的特征提取方法的简单介绍,让大家理解图像特征提取是一件充满专业领域知识的事情,缺乏领域知识完全抓瞎;
(4)以图像识别中为例介绍深度学习的一般理念;
(5)一些讨论。

什么是特征工程?我们在数据挖掘建模中,习惯把它称之为 “数据探索”,也可以理解为是“数据准备”的一部分工作。这个工作非常重要,甚至是决定建模效果的唯一因素,后续如何使用工具进行数据挖掘建模,反而不是一件困难的事情。
我们举一个运营商宽带用户流失预测的假想场景来介绍特征工程的内容。我们在建模会整理以下指标,比如:宽带档案信息、其它关联产品信息、用户消费行为等信息,这方面的信息采集和加工很多是常规性的工作。那么如何进一步提取相关特征?需要再展开一些想象力,这方面需要数据挖掘建模人员理解业务和了解数据,比如(以下是想象变量):
(1)宽带流失是否和宽带质量有关?比如频繁掉线,需要从“宽带拨号”频繁度,提取掉网信息,同时需要想办法区格“掉网重拨”和“路由器休眠”的场景,这方面需要研究相关数据的分布情况,再确定特征提取的方法;
(2)宽带流失是否被人策反?可以考虑用户名下的手机、固话与它网客服的联系情况。还可以考虑是否有它网的客户经理、代理商来做策反沟通,需要尝试研究一下“交往圈”与流失的历史关系;
(3)用户的价格敏感性?比如我们可以尝试计算“宽带价格或者套餐价格”与“用户在用手机价格”的比值,甚至更加精细一点,考虑到手机“平均在用年限”等;
(4)宽带质量的重要性评估,可以获取并研究用户在宽带上的典型性应用,比如游戏类应用、股票交易类应用等等。
可以看出我们在建模的数据准备工程中,一方面是希望能够增加一些数据;另一方面,我们希望在既有数据中,获取出更加有“业务意义”的衍生指标,这个过程其实就是特征工程。
好的特征工程产生的指标能够帮助建模者提升建模效果,这往往比选择具体的模型和参数设置更加重要。
举一个竞赛例子:在KAGGLE网站中,有一个“泰坦尼克”的预测幸存者的入门级数据挖掘比赛,其中有一个字段是乘客的姓名,有些人将“姓名”视同ID弃之不用,有些人将“称呼”,比如Dr.、Master.等从“姓名”中提取出来,并尝试通过“姓氏”来做家庭识别,结果能够取到比较好的排名成绩。
再比如:我们在公众号《通过Tensorflow游乐园和同学们一起玩耍下神经网络》演示了通过增加衍生特征值可以增强机器学习能力的示例(如果通过深度的网络实现复杂分布的划分,有兴趣可以翻阅一下)。
特征工程之所以可能是最终成绩的决定性因素,这是因为在后续建模阶段,使用什么模型、以及什么参数,都有成熟的工具/开发包来支持。比如“集成学习”+“单分类器”的效果一般是比“单分类器”好一些;离散变量多的数据集建模一般是“决策树”的相关模型要优于SVM,而“SVM+径向基函数”几乎总是优于3层“BP神经网络”,“随机森林”的稳定性最好等等,至于建模时的具体参数可以多试试,只要时间充裕。

深度学习的突破源于数字图像识别。我们先从这个最简单的手写数字识别的例子(来源于sklearn网站示例)开始下面的话题。这个手写体的图片像素是8*8,样式如下:

每个数字可以理解为建模样本中的一条记录,那么记录组成就是65个字段:“数字标签”+8*8=64个像素点信息。按照自左而右、自上而下的顺序记录,每个像素点的值从0-255。
这个建模过程可以理解为“通过64个变量来尝试分类数字标签(0-9)”,因为输入变量数量64个,不算多,可以采用很多算法模型,比如决策树、SVM、BP神经网络等,以下是采用BP神经网络的示意图:
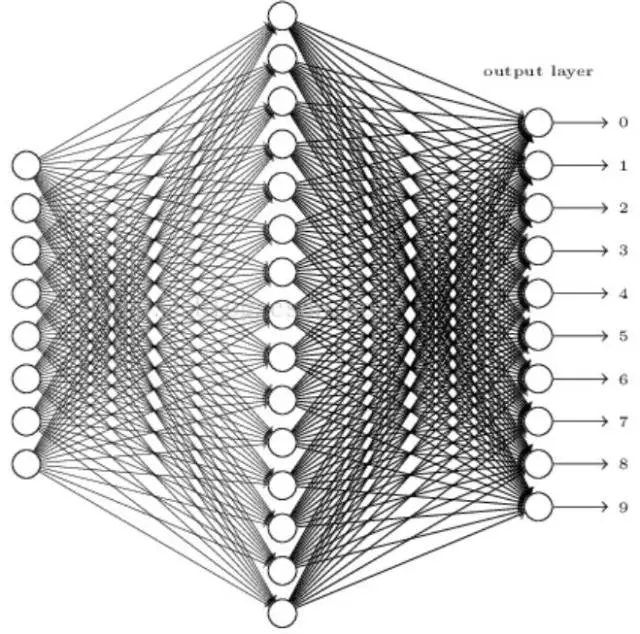
上述8*8图像的建模识别的准确率很容易可以达到95%以上,而且我们不需要做任何特征工程。再下来这个示例,就需要考虑做些特征工程的工作了,它就是知名的手写数字数据集MNIST,数字的像素是28*28,示例如下:

如果继续沿用前面建模的思路,那么输入变量有28*28=784个变量。如果我们做过建模工作,这个输入变量的数量,有点多。如果不加筛选的放到算法模型中去,有些算法的计算时间会非常长,比如SVM、逻辑回归、传统BP神经网络等。那么,我们需要考虑进行降维,降维也是特征工程的一个方面内容。我们尝试两种降维方式:一种是采用主成分分析(PCA)方式,选择100多个主成分,另一种是将28*28的图像压缩到14*14,压缩方式是将相邻2*2=4格的像素值取均值形成1格的像素值。有关详细介绍敬请阅读本公众号《聊一下‘主成分分析’在数据挖掘预处理中的作用》。
此类场景下的建模,如果缺乏一定的降维或者建模技巧,识别准确率很难达到95%以上。如果不做降维的话,如果仅仅在笔记本上运行的话,会非常费力的。
我们在尝试做MNIST模型时,还萌发了其它特征提取的方法,针对一些误分的数字,也考虑增加一些衍生变量:比如计算“左中右”的黑色像素点比例的特征变量,识别“1”这种数字肯定效果很好,再比如计算“上中下”黑色像素点比例的特征变量,那么识别“7”、“6”、“9”之类的效果也会不错。如果根据手写数字的特征,再设计一些特征变量来区格,估计不用原始变量,依靠这些特征变量也会有不差效果。但是我们必须意识到,这种方法之所以可行,是因为我们研究的是简单数字的识别,它非常封闭,容易针对特定场景做特定的特征提取设计。
但是如果是一般的图片呢,我们如何进行猫狗图像的识别?以下是KAGGLE中“Dogs vs Cats Redux:Kernels Edition”建模数据集的一些样例:

现在问题来了,上述这些图片如何进行识别?如何提取特征值,这些图片的像素可能是500*500*3 (RGB三种颜色),如果采用数字识别的方法,那么输入变量是75万,估计不会有人真的敢把75万像素信息一次性作为输入变量吧!还有一个值得关注的事情就是,MNIST的数据集是规整好的数据集,手写体虽然不太规范,但是提供的数据都是正面的,而不是倒过来的,背景都是黑色或者白色,没有干扰背景,不会增加什么横线、斜线之类的干扰东西。比如特征码识别:

因此图像的特征提取和识别,不像我们文章开头介绍流失预测分类的商业场景,从业务和数据层面理解下,就能够搞出来一些可用的特征值,然后使用这些特征值进行建模。
为了更好理解深度学习所解决的问题,还得先谈谈深度学习兴起前,传统图像识别是怎么做的?继续耐心往下读哦。

我们指的“传统图像识别”,特指2012年以前,计算机图像专业方向采用的主流方法。
讲图像识别绕不开ImageNet,它是华人科学家李飞飞负责创建的,花费了数百人数年的投入,采集了上亿的互联网图片,并从中选出数千万照片通过人工打好内容标签(有关ImageNet进一步介绍,可以观看李飞飞在TED的演讲“如何教计算机识别图像”)。从2010年开始,每年举办了一次基于ImageNet的图像识别的全球比赛。传统图像识别怎么做的呢?以下PPT截屏来自ImageNet 2011的冠军队伍的技术思路分享:
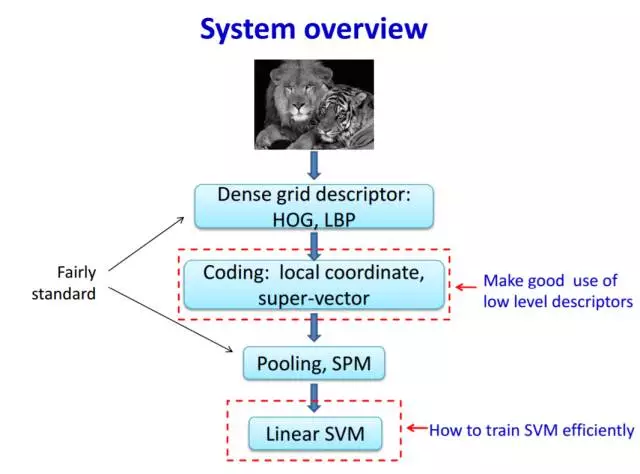
从这张胶片,我们看出这支冠军队伍的贡献主要在第二步和第四步做了优化,但识别的整体架构还是沿用传统思路。除了第二步编码处理(已经过时技术,没必要花力气研究),其它还是挺明白它的框架的:
第一步是做特征提取,有点宽带流失中设计特征值的意思,具体传统思路怎么做我们下面再具体介绍;
第二步是编码,可能有点像28*28转换成784一维数组一样,但肯定做了很多专业化的技术处理工作,总之是编码工作;
第三步是做降维,就像是MNIST数据集28*28压缩成14*14的例子一样;
第四步是做模型分类算法,这个思路和我们做宽带流失预测是一样的,和MNIST最终分类建模是完全一样的套路。
好了,上述框架第二到第四没什么说的,我们重点介绍传统方法的特征提取是怎么做的?根据上面的胶片,我们就就大致了解一下HOG和LBP。
1、什么是HOG
HOG是全称是Histogram of Oriented Gradient,它的计算思路是什么就不在此处搬材料了,总之,就是根据事先的算法,明确的计算出来,它表述的是图像各个像素的“梯度”(像素值的上升/下降方向吧)。基于HOG处理后,图像信息明显减少,但是一定程度保留了被识别基本要素。以下是几个转换例子:


HOG处理后,涉及到一系列具体的编码后续处理,比如归一化等,总之并不影响我们的“想象理解”。
2、什么是LBP
LBP的全称是Local Binary Pattern,局部二值模式,是一种用来描述图像局部纹理特征的图像转换算法。这个处理非常简单,就下它的思路:
原始的LBP转换算法是定义为在3*3的窗口内,以窗口中心像素为阈值,将相邻的8个像素的灰度值与其进行比较,若周围像素值大于中心像素值,则该像素点的位置被标记为1,否则为0。这样,3*3邻域内的8个点经比较可产生8位二进制数,即得到该窗口中心像素点的LBP值,并用这个值来反映该区域的纹理信息。上面描述有点啰嗦,看图就了然了:
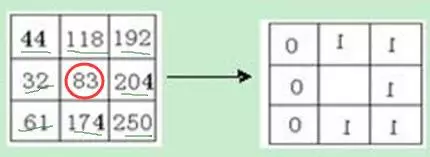
当然原始算法之外还有变种算法,比如圆形或者不同半径什么的。LBP的效果是这样的,总之是突出了一些特征,消减了很多其它信息:
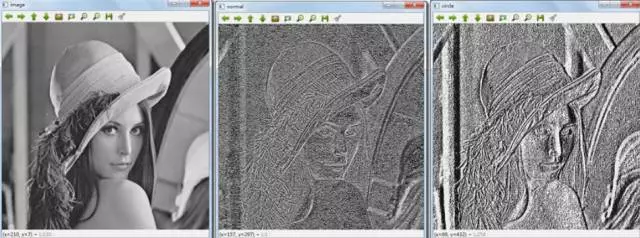

以上我们就简单介绍了图像识别中用的两个特征提取技术,还有其它技术,比如SIFT据说非常NB。
以上就是传统图像识别的基本性框架。它的基本思路,就是根据“专业”的特征提取算法提取图像特征,然后做POLLING压缩,再送到大家都理解的分类器中。而这些专业特征提取算法是一群领域内的人士搞了10年乃至更长时间所积累可行的处理方法。

为了介绍“深度学习”,前面铺垫了4000多个字和十来张图了,能够读到这真心点赞。深度学习的一鸣惊人是在ImageNet 2012年的比赛,基于Alexnet的深度学习算法一下子将识别准确率从75%提升到85%,这个成绩非常彪悍,相当于一次考试中,第一名考了99分,第二名、第三名分别考了62分、61分的效果一样。于是,神经网络依赖深度学习的框架再次成为追捧的对象,神经网络开始焕发第三春(曾经两起两落,有兴趣的同学可以网上查阅相关历史);于是,到了2013年全部参赛队伍都使用了深度学习的算法框架。此后,深度学习风头逐渐盖过所有“科技网红”,成为当前第一热门技术,而且还在持续中。
我们在前面比较详细的描述了HOG和LBP图像处理的方式。它是基于“卷积”基础的进一步加工方法。在图像处理中,它是一个滑动窗口,比如3*3一个窗口,卷积为:
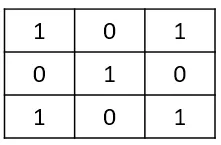
那么它的计算方法为滑动窗口内的对应像素值乘以卷积对应位置的值,然后进行累加:
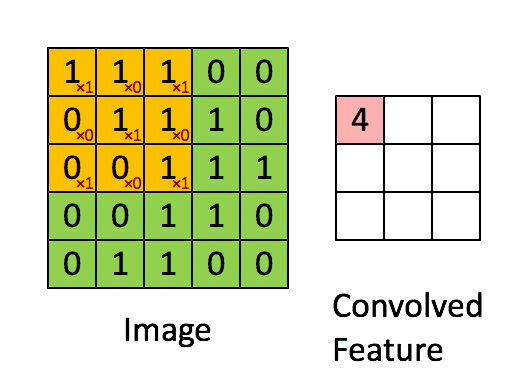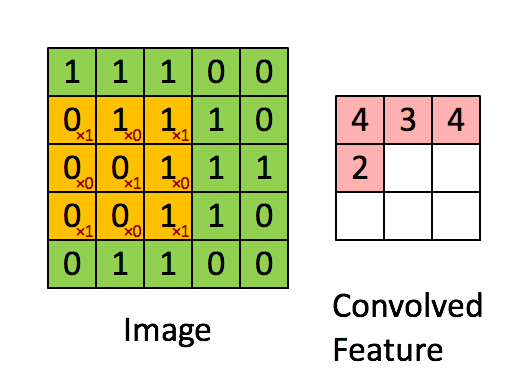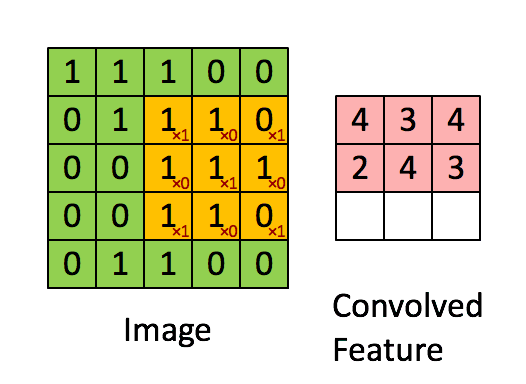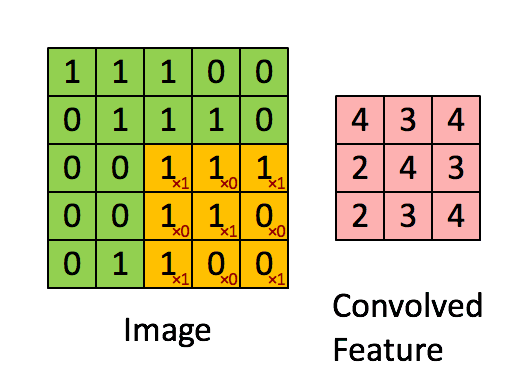
更大的示意图如下:

卷积的意义是什么呢,它是特征的提取器。以下是例子:
我们用一个曲线的卷积过滤器演示(为了理解方便,暂不考虑颜色,仅仅考虑黑白深度)
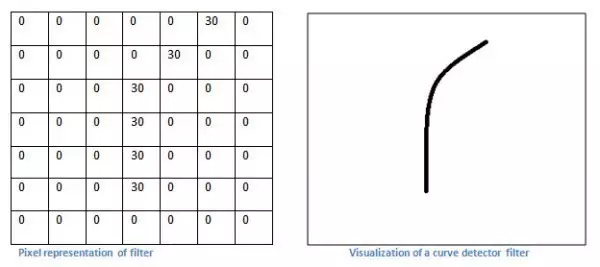
那么用这个卷积模板(也称卷积核)来处理一个图像:
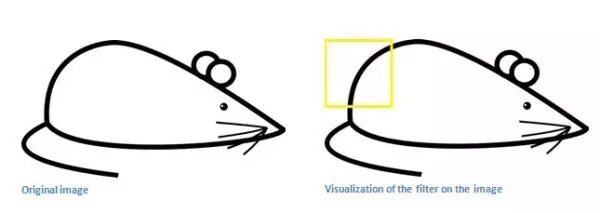
记住,我们需要做的是使用图像中的原始像素值在过滤器中进行乘积。
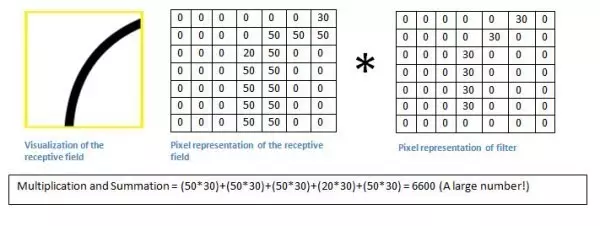
由于这个部位和过滤器比较相似,因此卷积结果的数值比较大。我们在看一个部位:
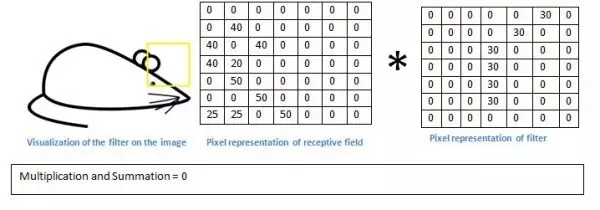
检测值竟然要低得多!这是因为在图像中没有任何部分响应曲线检测过滤器。记住,这个卷积层的输出是一个激活图。因此,在简单的情况下一个过滤器的卷积(如果该过滤器是一个曲线检测器),激活图将显示其中大部分可能是在图片中的曲线区域。在这个例子中,我们的28*28*1激活图左上方的值将是6600,这种高值意味着很可能是在输入中有某种曲线导致了过滤器的激活。因为没有任何东西在输入使过滤器激活(或更简单地说,在该地区的原始图像没有一个曲线),其在我们的激活图右上方的值将是0。记住,这仅仅只是一个过滤器。这个过滤器将检测线向外和右边的曲线,我们可以有其他的曲线向左或直接到边缘的过滤器线条。
此处声明一下:上述描述的卷积过滤器是简化的,尽管如此,主要的论据仍然是相同的。
我们容易理解,这种图像卷积计算其实是一种过滤器,我们可以设计不同过滤器来获取图像不同视角的特征值。那么我们应该设计什么样的过滤器呢?如何设计不同曲线、直线、圆形的探测过滤器?以及基于过滤器后续做什么的进一步处理?这其中有最佳实践么?答案是“有的”,最佳实践就包括了前面简介中HOG、LBP等方法,这是数十年图像专家们摸索出来的方法。根据这个最佳实践,它们在ImageNet的图像识别维持在75%左右,而且大多数学者们认为这个框架还在渐进的成长中。在2012年前,据说有个计算机图像识别的国际权威曾经嘲讽深度学习的方法是如何的不靠谱。
然而在2012年,奇点出现了,深度学习的颠覆性方法得到了验证。
我们查阅百度百科,它是这么介绍深度学习的定义:
“深度学习的概念源于人工神经网络的研究。含多隐层的多层感知器就是一种深度学习结构。深度学习通过组合低层特征形成更加抽象的高层表示属性类别或特征,以发现数据的分布式特征表示。”
“深度学习是机器学习中一种基于对数据进行表征学习的方法。观测值(例如一幅图像)可以使用多种方式来表示,如每个像素强度值的向量,或者更抽象地表示成一系列边、特定形状的区域等。而使用某些特定的表示方法更容易从实例中学习任务(例如,人脸识别或面部表情识别)。”
“深度学习的好处是用非监督式或半监督式的特征学习和分层特征提取高效算法来替代手工获取特征。”
以上表述非常学术化,基本上明白的人不用看,不明白的人也看不明白。最后一段,估计有人还是能看明白:特征提取是自动执行的,而不是采用最佳实践!深度学习是2006年正式提出的,有很多算法,也在不断演进。这里我将继续结合前面的示例,重点介绍它们的杰出代表,图像识别的颠覆者CNN(Convolutional Neural Networks),即大名鼎鼎的“卷积神经网络”。
前面提到卷积过滤器应该如何设计,传统的方法是采用专家探索出来的既定算法,而深度学习是摒弃了这种“经验式”的方法,而采用了自学习的方法。也就是说,卷积参数是在训练过程中自动获取的。
前面提到MNIST人工数字识别案例中,我们采用主成分分析或者28*28转换为14*14的降维方式,取得的最好成绩是96%。
我们演示一下如何基于深度学习的思路完成这个建模,我们模仿深度学习的雏形架构LeNet,但参数略有差异:

简单解释一下这个框架(实在搞不清楚的可以跳过):
(1)首先是用6个5*5的卷积过滤器,那么一张图片会生成6个28*28规格的过滤图片(C1层);
(2)然后C1层每个图片降采用就是相邻2*2归并成1个像素个,方法是取2*2最大的像素点值(这是为了提取最显著的值)(S1层),示意图如下:
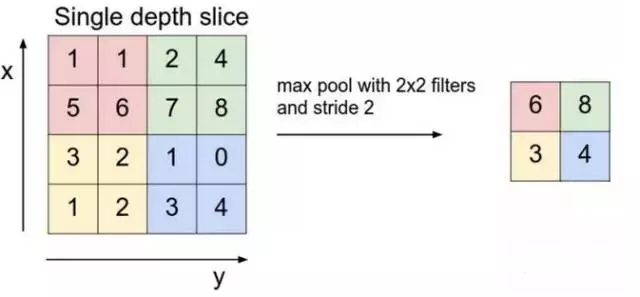
(3)然后S1层的6张图片通过16个卷积过滤器,全交叉形成16张图片(LeNet是做了筛选部分图片交叉);
(4)类似步骤(2)操作;
(5)16张7*7的图片形成784个变量输入到神经网络的分类器中,隐含节点数量为300,输出为10个节点,这是个节点的输出值,分别代表0-9的概率,分类器选择概率最大的数字为分类预测数字(术语是SOFTMAX层)。
上述步骤涉及到一些技术细节,比如采用什么激活函数、如何避免过拟合、如何能够避免传统神经网络中“梯度弥散”的问题,这是比较具体技术内容,我们就不再这里探讨了。总之,深度学习的神经网络在2006年之后,采用了一些改进方法,有效解决相关问题。
上述有关深度学习的框架介绍,如果大家读起来有些困惑,那不要紧,我们跳出这些技术处理细节,回到基础性思路层面。我们将上面的学习框架,划分出两个步骤:数据预处理和分类预测。这个看似和我们做以前数据挖掘步骤一致!但是深度学习的特点在于:数据预处理和分类预测是“一体化”的,分类器参数在进行样本训练时,同时会做预处理参数的更新(思路就是传统神经网络的参数反向传递,参数优化是基于链式法则偏导计算+基于梯度下降最优化的最优化方法,如果熟悉数据挖掘分析师知道传统BP神经网络基本原理的话,这些技术细节应该是了解一些的,不过是否了解这些技术细节,不影响我们的总体概念理解)。我画了一个帮助理解的示意图:
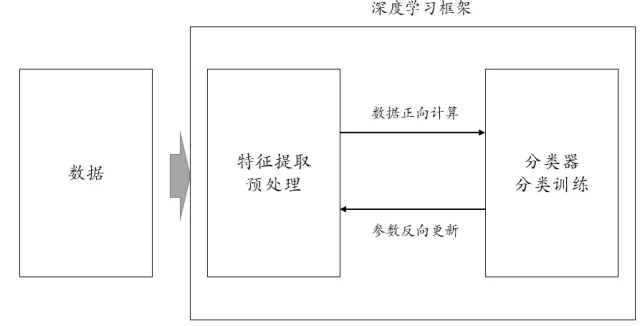 (编者按:有人会认为我们上面这个框架描述有点问题,因为特征提取和分类器不应该认为割裂,它们是一体化的,就好像手与胳膊是一体化一样,但我们觉得这么表达还是有利于初学者理解深度学习。)
(编者按:有人会认为我们上面这个框架描述有点问题,因为特征提取和分类器不应该认为割裂,它们是一体化的,就好像手与胳膊是一体化一样,但我们觉得这么表达还是有利于初学者理解深度学习。)
那么,传统的图像识别以及我们各个行业数据挖掘的框架是什么样的呢,估计大家自行能够画出来,对应上面的框架是这样的:
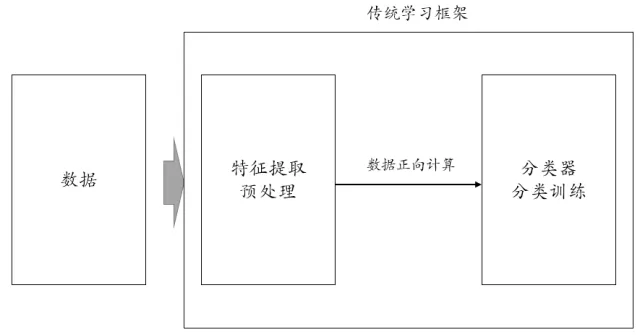
传统学习框架,特征提取预处理是分类器的前置流程,分类器的训练过程不能自动影响特征提取的相关参数。如果要影响的话,怎么做呢?就是靠我们这些数据挖掘工程师手工做参数调整,比如衍生出一个新变量什么、换一个代表性的卷积过滤什么的。
至此,相信大家尤其是具有数据挖掘基本知识的同学们,应该理解什么是深度学习的基本概念框架了吧!
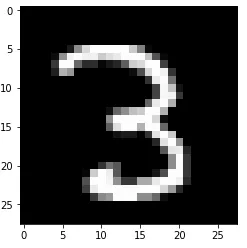
基于上述深度学习框架,MNIST的识别效果是98%-99.5%,显著高于我们自行用传统建模方法最好96%的成绩。我来演示一下,通过这些卷积的自学习训练,究竟把图片转换成什么样子了?比如输入图片为3,原始图如下:
我们做个对比,用“未充分训练的卷积参数得出的各层图片”和“经过充分训练后卷积得出的各层图片”做比较,给大家感知一下:
未充分训练图片C1层:

充分训练图片C1层:

未充分训练图片S1层:

充分训练图片S1层:

未充分训练图片C1层:

充分训练图片C1层:
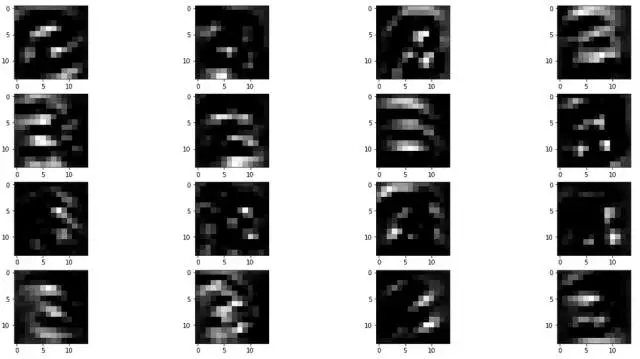
未充分训练图片S2层:

充分训练图片S2层:

我们尝试做个点评,没啥严格的根据,感知一下:
(1)我们发现充分训练的C1层(第一预处理层)处理形成的图片明显要光滑一些;
(2)我们发现充分训练的S2层(最后预处理层)处理形成的图片的亮点像素的比例要均匀一些,几乎都是集中在中间区域。
我们再举一下前面提到猫狗识别中,一只狗图像在非充分训练和充分训练的卷积层处理后的图像差异。
原始图片是这样的:

未充分训练的卷积层的处理结果:

充分训练的卷积层的处理结果:
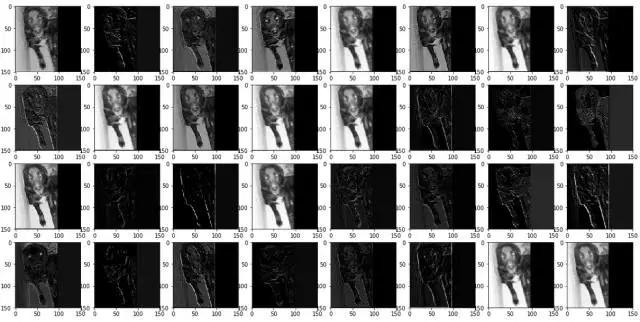
总体可以看出充分训练的卷积层处理后的各个图像,感觉特征要多一些。

好了,深度学习的代表模型CNN的思路框架基本介绍结束。我们再简单讨论下深度学习的一些特性:
(1)虽然深度学习号称“特征提取自动化“,但是还是有一些参数是需要建模人员指定的,比如网络结构、卷积的大小,POOLLING设计等等。事实上,深度学习的建模训练,更加需要一些人为技巧,同时这些技巧往往而且缺乏扎实的理论依据,这也是一些专家诟病深度学习的原因之一;
(2)深度学习框架为什么是神经网络模式,而不是其它,比如决策树。这是因为,神经网络中的卷积参数学习和普通分类参数学习,能够自然的进行一体化集成学习,彼此不排斥。而如果想要“卷积网络”参数计算和“决策树”集成在一起学习,就好像不同动物的器官,有排斥性,不能进行嫁接。不过,国内周志华教授提出一种基于决策树的深度学习,效果如何有待时间检验。
(3)深度学习的成功,一方面是算法突破,但另外更重要的原因是计算机处理能力的提升(多核CPU、GPU的引入)、以及大数据环境提供的海量建模样本。
(4)深度学习擅长于领域图像、语音这种特征空间大的计算场景,像针对性营销、客户细分这种传统数据挖掘场景,如何使用深度学习,来自动提取更有价值的特征参数,需要更多的探索,不在此处讨论了。