Windows下用IDEA进行Spark开发
当集群搭建好了,接下来就是将自己的代码写好,扔到集群上进行跑了。
一、安装软件
1、JDK
2、Intellj IDEA
3、xshell
这三部安装过程这里不介绍,下一步下一步即可。
4、Intellj IDEA 安装scala插件
首次使用会出现安装插件提示,如果没安装,就在File->setting->plugins,输入scala.
二、所需包
各种包最好保持与集群版本一致。
1、java sdk
2、scala sdk
3、spark jar包
如果spark版本低于2.0,我们可以直接下载对应版本的assembly jar包,我的是1.6.0,有jar包,解压后,放在相应目录下。如果是2.0后,就没有jar包了,我们可以用maven,给idea安装一个maven插件。maven怎么用,网上资料很多。
三、建项目
2、在项目页File -> project structure -> Libraries, 点“+”,选Java,找到自己的sprk jar包,我的是spark-assembly-1.6.0-hadoop2.6.0.jar导入,这样就可以编写spark的scala程序了

3、开始编码
随便写一个测试例子,扔到集群上跑跑试试,注意读取文件时,如果是hdfs上的文件,则是“hdfs://……”
package main
/**
* Created by Administrator on 2016-10-28.
*/
import org.apache.spark.SparkContext
import org.apache.spark.SparkConf
import org.apache.log4j.{Level,Logger}
object SimpleTest {
Logger.getLogger("org").setLevel(Level.ERROR)
def main(args: Array[String]) {
val logFile = "file:///usr/local/spark/bin/pyspark.cmd" // 系统上的某些文件
val conf = new SparkConf().setAppName("Simple Application")
val sc = new SparkContext(conf)
sc.setLogLevel("WARN")
val logData = sc.textFile(logFile, 2).cache()
val numAs = logData.filter(line => line.contains("a")).count()
val numBs = logData.filter(line => line.contains("b")).count()
println("Lines with a: %s, Lines with b: %s".format(numAs, numBs))
sc.stop()
}
}四、打包程序
点击项目页File -> project structure ->Artifacts,可以看到项目有相应的包,如果集群上有,就去掉“-”,免得文件大,也免得出错。

去掉后:
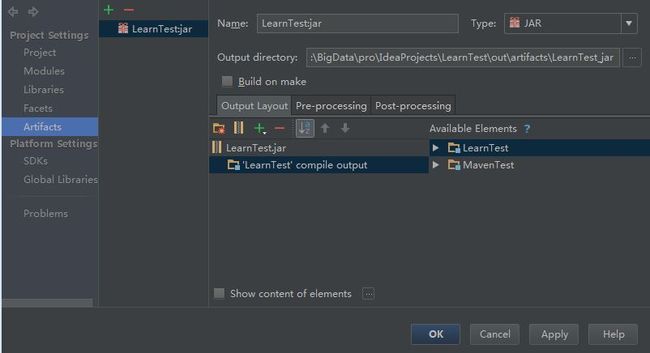
保存后,点击Build->Build artifects。这样项目目录下就会out->artifacts,进去找到jar包。
五、上传程序
程序打包好了后,就扔到集群上上跑吧。
1、通过xshell登录集群。
你需要有集群账户,申请号账号后,登录。
2、通过xshell将程序上传到集群
通过xshell传文件及其方便,到制定目录下,直接推进去,就上传好了。
六、运行程序
开始跑起来吧!
3.1、 运行程序命令介绍
如果是用python写的程序,可以用pyspark,scala写的程序可以用spark -submit或者spark -shell命令。对于他两的区别,网上说:就Spark提交程序来说,最终都是通过Spark-submit命令来实现的,不同的是spark-shell在运行时,会先进行一些初始参数的设置,然后调用Sparksubmit来运行,并且spark-shell是交互式的。
spark -submit和spark -shell在spark home目录的bin文件下,我们可以直接用绝对路径
$SPARK_HOME/bin/spark-submit yourapp
spark-shell同上但是这样比较麻烦,我们可以在环境变量里设置。
alias spark-submit=$SPARK_HOME/bin/spark-submit
spark-shell同上这样以后运行程序就可以直接打spark-submit yourapp了。
这里有必要提一下,bashrc与profile的区别
bashrc与profile的区别:
/etc/profile,/etc/bashrc 是系统全局环境变量设定
~/.profile,~/.bashrc用户家目录下的私有环境变量设定
当登入系统时候获得一个shell进程时,其读取环境设定档有三步
1)首先读入的是全局环境变量设定档/etc/profile,然后根据其内容读取额外的设定的文档,如
/etc/profile.d和/etc/inputrc
2)然后根据不同使用者帐号,去其家目录读取~/.bash_profile,如果这读取不了就读取~/.bash_login,这个也读取不了才会读取~/.profile,这三个文档设定基本上是一样的,读取有优先关系
3)然后在根据用户帐号读取~/.bashrc
~/.profile与~/.bashrc的区别:
~/.profile可以设定本用户专有的路径,环境变量,等,它只能登入的时候执行一次
~/.bashrc也是某用户专有设定文档,可以设定路径,命令别名,每次shell script的执行都会使用它一次
3.2、参数设置
我们用spark-submit –help看看怎么设置

我们主要设置一下
--exector-memory
--total-executor-cores不然资源全让你一个人用光了,其他人用啥。
比如我设置的:
3.3、运行
首先看看传进来的文件
开始跑:
spark-submit LearnTest.jar3.4、运行结果

也可以从sparkui上看结果,端口8080
