分类算法(决策树,SVM,随机森林,逻辑回归)
直接贴代码,注释也一并在代码中
参考资料:python机器学习
#########决策树输出
# -*- coding: utf-8 -*-
"""
Created on Sat May 26 15:07:33 2018
@author: hu
"""
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import load_iris
import numpy as np
from sklearn import datasets
#数据加载
iris = datasets.load_iris()
#花瓣长度和宽度,2,3、两个特征值
X = iris.data[:,[2,3]]
#类标赋值
y = iris.target
#数据分区导包
from sklearn.cross_validation import train_test_split
#划分数据训练集和测试集,测试集30%
X_train , X_test , y_train, y_test = train_test_split(X,y,test_size = 0.3, random_state=0)
#数据缩放,标准化
from sklearn.preprocessing import StandardScaler
sc=StandardScaler()
sc.fit(X_train)#计算特征样本均值和标准差
X_train_std = sc.transform(X_train)#对其样本均值和标准差做标准化处理
X_test_std = sc.transform(X_test)#对其样本均值和标准差做标准化处理
from matplotlib.colors import ListedColormap
import matplotlib.pyplot as plt
#可视化函数
def plot_decision_regions(X,y,classifier,test_idx=None ,resolution = 0.02):
#set marker generator and color map
markers = ('s','x','o','^','v')
colors = ('red','blue','lightgreen','gray','cyan')
cmap = ListedColormap(colors[len(np.unique(y))])
#plot the decision suiface
x1_min,x1_max = X[:,0].min()-1, X[:,0].max()+1
x2_min,x2_max = X[:,0].min()-1, X[:,0].max()+1
xx1,xx2 = np.meshgrid(np.arange(x1_min,x1_max,resolution),
np.arange(x2_min,x2_max,resolution))
Z= classifier.predict(np.array([xx1.ravel(),xx2.ravel()]).T)
Z = Z.reshape(xx1.shape)
plt.contourf(xx1,xx2,Z,alpha=0.4,cmap=cmap)
plt.xlim(xx1.min(),xx1.max())
plt.ylim(xx2.min(),xx2.max())
#plot all samples
X_test ,y_test = X[test_idx, :],y[test_idx]
for idx ,cl in enumerate(np.unique(y)):
plt.scatter(x=X[y== cl,0],y=X[y==cl,1],
alpha=0.8,c=cmap(idx),
marker=markers[idx])
#,lable =cl)
#highlight test samples
if test_idx:
X_test,y_test =X[test_idx,:],y[test_idx]
plt.scatter(X_test[:,0],X_test[:,1],c='',
alpha=1.0,linewidths=1,marker='o',
s=55)
#,lable ='test set'
# )
############ 可适用于大型数据
#from sklearn.linear_model import SGDClassifier
#svm=SGDClassifier(loss='hinge')
###########
from sklearn.tree import DecisionTreeClassifier
tree= DecisionTreeClassifier(criterion='entropy',max_depth=3,random_state=0)
tree.fit(X_train_std,y_train)
#SCVM模型
#svm = SVC(kernel='linear',C=1.0,random_state= 0 )
#svm.fit(X_train_std,y_train)
#plot_decision_regions(X_combined_std,y_combined,classifier=svm, test_idx=range(105,150))
#plt.xlabel('petal length [standardized]')
#plt.ylabel('petal width [standardized]')
#plt.legend(loc='upper left')
#plt.show()
####SVM解决非线性问题
#替换rbf及gamma值越大,决策边界越紧凑,适用gamma进行模型调优
X_combined_std =np.vstack((X_train_std,X_test_std))
y_combined =np.hstack((y_train,y_test))
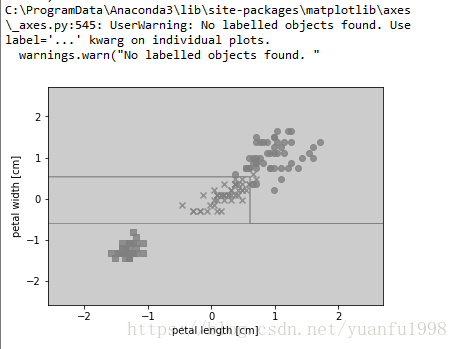
plot_decision_regions(X_combined_std,y_combined,classifier=tree, test_idx=range(105,150))
plt.xlabel('petal length [cm]')
plt.ylabel('petal width [cm]')
plt.legend(loc='upper left')
plt.show()
#可导出.dot格式,可视化处理
#转换为png文件
#GRAPHVIZ
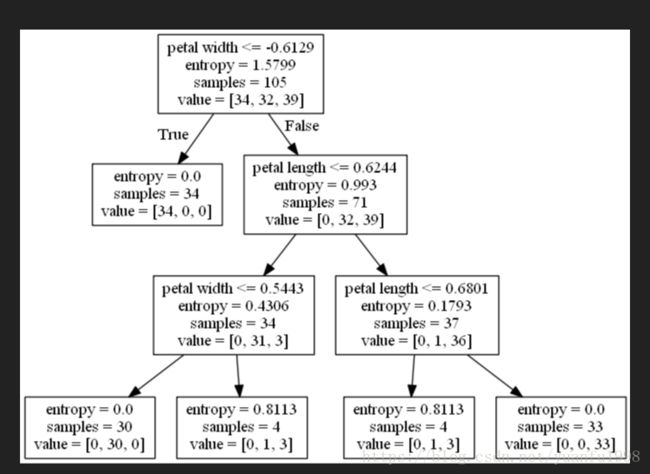
from sklearn.tree import export_graphviz
export_graphviz(tree,out_file='tree.dot',feature_names=['petal length','petal width'])
####Graphviz2.38
#>dot -Tpng tree.dot -o tree.png
#输出可视化
###SVM输出
# -*- coding: utf-8 -*-
"""
Created on Sat May 26 15:07:33 2018
@author: hu
"""
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import load_iris
import numpy as np
from sklearn import datasets
#数据加载
iris = datasets.load_iris()
#花瓣长度和宽度,2,3、两个特征值
X = iris.data[:,[2,3]]
#类标赋值
y = iris.target
#数据分区导包
from sklearn.cross_validation import train_test_split
#划分数据训练集和测试集,测试集30%
X_train , X_test , y_train, y_test = train_test_split(X,y,test_size = 0.3, random_state=0)
#数据缩放,标准化
from sklearn.preprocessing import StandardScaler
sc=StandardScaler()
sc.fit(X_train)#计算特征样本均值和标准差
X_train_std = sc.transform(X_train)#对其样本均值和标准差做标准化处理
X_test_std = sc.transform(X_test)#对其样本均值和标准差做标准化处理
from matplotlib.colors import ListedColormap
import matplotlib.pyplot as plt
#可视化函数
def plot_decision_regions(X,y,classifier,test_idx=None ,resolution = 0.02):
#set marker generator and color map
markers = ('s','x','o','^','v')
colors = ('red','blue','lightgreen','gray','cyan')
cmap = ListedColormap(colors[len(np.unique(y))])
#plot the decision suiface
x1_min,x1_max = X[:,0].min()-1, X[:,0].max()+1
x2_min,x2_max = X[:,0].min()-1, X[:,0].max()+1
xx1,xx2 = np.meshgrid(np.arange(x1_min,x1_max,resolution),
np.arange(x2_min,x2_max,resolution))
Z= classifier.predict(np.array([xx1.ravel(),xx2.ravel()]).T)
Z = Z.reshape(xx1.shape)
plt.contourf(xx1,xx2,Z,alpha=0.4,cmap=cmap)
plt.xlim(xx1.min(),xx1.max())
plt.ylim(xx2.min(),xx2.max())
#plot all samples
X_test ,y_test = X[test_idx, :],y[test_idx]
for idx ,cl in enumerate(np.unique(y)):
plt.scatter(x=X[y== cl,0],y=X[y==cl,1],
alpha=0.8,c=cmap(idx),
marker=markers[idx])
#,lable =cl)
#highlight test samples
if test_idx:
X_test,y_test =X[test_idx,:],y[test_idx]
plt.scatter(X_test[:,0],X_test[:,1],c='',
alpha=1.0,linewidths=1,marker='o',
s=55)
#,lable ='test set'
# )
############ 可适用于大型数据
#from sklearn.linear_model import SGDClassifier
#svm=SGDClassifier(loss='hinge')
###########
from sklearn.svm import SVC
#SCVM模型
svm = SVC(kernel='linear',C=1.0,random_state= 0 )
svm.fit(X_train_std,y_train)
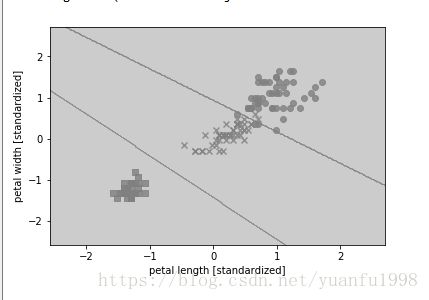
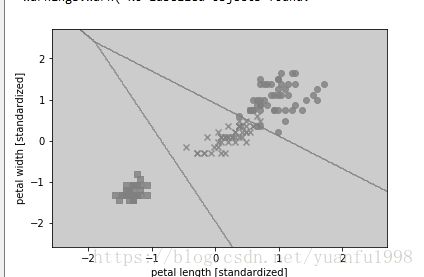
plot_decision_regions(X_combined_std,y_combined,classifier=svm, test_idx=range(105,150))
plt.xlabel('petal length [standardized]')
plt.ylabel('petal width [standardized]')
plt.legend(loc='upper left')
plt.show()
####SVM解决非线性问题
#替换rbf及gamma值越大,决策边界越紧凑,适用gamma进行模型调优
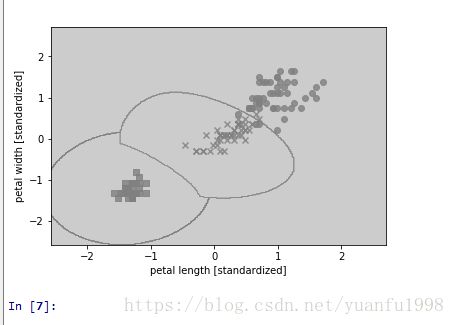
svm = SVC(kernel='rbf',C=1.0,random_state= 0,gamma= 1 )
svm.fit(X_train_std,y_train)
plot_decision_regions(X_combined_std,y_combined,classifier=svm, test_idx=range(105,150))
plt.xlabel('petal length [standardized]')
plt.ylabel('petal width [standardized]')
plt.legend(loc='upper left')
plt.show()
#随机森林输出
# -*- coding: utf-8 -*-
"""
Created on Sat May 26 16:34:12 2018
@author: hu
"""
# -*- coding: utf-8 -*-
"""
Created on Sat May 26 15:07:33 2018
@author: hu
"""
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import load_iris
import numpy as np
from sklearn import datasets
#数据加载
iris = datasets.load_iris()
#花瓣长度和宽度,2,3、两个特征值
X = iris.data[:,[2,3]]
#类标赋值
y = iris.target
#数据分区导包
from sklearn.cross_validation import train_test_split
#划分数据训练集和测试集,测试集30%
X_train , X_test , y_train, y_test = train_test_split(X,y,test_size = 0.3, random_state=0)
#数据缩放,标准化
from sklearn.preprocessing import StandardScaler
sc=StandardScaler()
sc.fit(X_train)#计算特征样本均值和标准差
X_train_std = sc.transform(X_train)#对其样本均值和标准差做标准化处理
X_test_std = sc.transform(X_test)#对其样本均值和标准差做标准化处理
from matplotlib.colors import ListedColormap
import matplotlib.pyplot as plt
#可视化函数
def plot_decision_regions(X,y,classifier,test_idx=None ,resolution = 0.02):
#set marker generator and color map
markers = ('s','x','o','^','v')
colors = ('red','blue','lightgreen','gray','cyan')
cmap = ListedColormap(colors[len(np.unique(y))])
#plot the decision suiface
x1_min,x1_max = X[:,0].min()-1, X[:,0].max()+1
x2_min,x2_max = X[:,0].min()-1, X[:,0].max()+1
xx1,xx2 = np.meshgrid(np.arange(x1_min,x1_max,resolution),
np.arange(x2_min,x2_max,resolution))
Z= classifier.predict(np.array([xx1.ravel(),xx2.ravel()]).T)
Z = Z.reshape(xx1.shape)
plt.contourf(xx1,xx2,Z,alpha=0.4,cmap=cmap)
plt.xlim(xx1.min(),xx1.max())
plt.ylim(xx2.min(),xx2.max())
#plot all samples
X_test ,y_test = X[test_idx, :],y[test_idx]
for idx ,cl in enumerate(np.unique(y)):
plt.scatter(x=X[y== cl,0],y=X[y==cl,1],
alpha=0.8,c=cmap(idx),
marker=markers[idx])
#,lable =cl)
#highlight test samples
if test_idx:
X_test,y_test =X[test_idx,:],y[test_idx]
plt.scatter(X_test[:,0],X_test[:,1],c='',
alpha=1.0,linewidths=1,marker='o',
s=55)
#,lable ='test set'
# )
############ 可适用于大型数据
#from sklearn.linear_model import SGDClassifier
#svm=SGDClassifier(loss='hinge')
###########
from sklearn.ensemble import RandomForestClassifier
forest= RandomForestClassifier(criterion='entropy',n_estimators=10,random_state=1,n_jobs = 2)
forest.fit(X_train_std,y_train)
#SCVM模型
#svm = SVC(kernel='linear',C=1.0,random_state= 0 )
#svm.fit(X_train_std,y_train)
#plot_decision_regions(X_combined_std,y_combined,classifier=svm, test_idx=range(105,150))
#plt.xlabel('petal length [standardized]')
#plt.ylabel('petal width [standardized]')
#plt.legend(loc='upper left')
#plt.show()
####SVM解决非线性问题
#替换rbf及gamma值越大,决策边界越紧凑,适用gamma进行模型调优
X_combined_std =np.vstack((X_train_std,X_test_std))
y_combined =np.hstack((y_train,y_test))
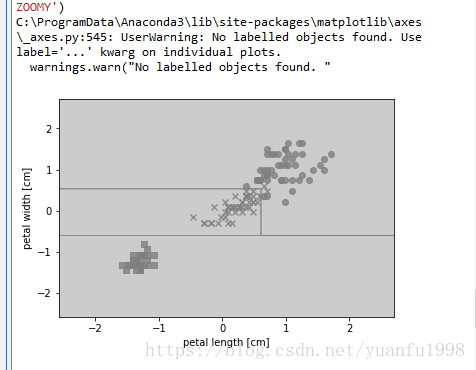
plot_decision_regions(X_combined_std,y_combined,classifier=tree, test_idx=range(105,150))
plt.xlabel('petal length [cm]')
plt.ylabel('petal width [cm]')
plt.legend(loc='upper left')
plt.show()
#可导出.dot格式,可视化处理
#转换为png文件
#GRAPHVIZ
#from sklearn.tree import export_graphviz
#export_graphviz(tree,out_file='tree.dot',feature_names=['petal length','petal width'])
####逻辑回归输出
# -*- coding: utf-8 -*-
"""
Created on Fri May 25 10:35:50 2018
@author: hu
"""
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import load_iris
import numpy as np
from sklearn import datasets
#数据加载
iris = datasets.load_iris()
#花瓣长度和宽度,2,3、两个特征值
X = iris.data[:,[2,3]]
#类标赋值
y = iris.target
#数据分区导包
from sklearn.cross_validation import train_test_split
#划分数据训练集和测试集,测试集30%
X_train , X_test , y_train, y_test = train_test_split(X,y,test_size = 0.3, random_state=0)
#数据缩放,标准化
from sklearn.preprocessing import StandardScaler
sc=StandardScaler()
sc.fit(X_train)#计算特征样本均值和标准差
X_train_std = sc.transform(X_train)#对其样本均值和标准差做标准化处理
X_test_std = sc.transform(X_test)#对其样本均值和标准差做标准化处理
#定义逻辑回归模型
lr = LogisticRegression(C=1000.0,random_state=0)
#在强正则化参数C<0.1时罚项使得所有权重都趋向0
#可视化
#显示来自数据集的样本
#不知道为嘛存在lable就会报错,CSDN查询,
#注释此处
#lable =cl
#lable ='test set'
from matplotlib.colors import ListedColormap
import matplotlib.pyplot as plt
#可视化函数
def plot_decision_regions(X,y,classifier,test_idx=None ,resolution = 0.02):
#set marker generator and color map
markers = ('s','x','o','^','v')
colors = ('red','blue','lightgreen','gray','cyan')
cmap = ListedColormap(colors[len(np.unique(y))])
#plot the decision suiface
x1_min,x1_max = X[:,0].min()-1, X[:,0].max()+1
x2_min,x2_max = X[:,0].min()-1, X[:,0].max()+1
xx1,xx2 = np.meshgrid(np.arange(x1_min,x1_max,resolution),
np.arange(x2_min,x2_max,resolution))
Z= classifier.predict(np.array([xx1.ravel(),xx2.ravel()]).T)
Z = Z.reshape(xx1.shape)
plt.contourf(xx1,xx2,Z,alpha=0.4,cmap=cmap)
plt.xlim(xx1.min(),xx1.max())
plt.ylim(xx2.min(),xx2.max())
#plot all samples
X_test ,y_test = X[test_idx, :],y[test_idx]
for idx ,cl in enumerate(np.unique(y)):
plt.scatter(x=X[y== cl,0],y=X[y==cl,1],
alpha=0.8,c=cmap(idx),
marker=markers[idx])
#,lable =cl)
#highlight test samples
if test_idx:
X_test,y_test =X[test_idx,:],y[test_idx]
plt.scatter(X_test[:,0],X_test[:,1],c='',
alpha=1.0,linewidths=1,marker='o',
s=55)
#,lable ='test set'
# )
#训练模型及可视化
lr.fit(X_train_std,y_train)
X_combined_std =np.vstack((X_train_std,X_test_std))
y_combined =np.hstack((y_train,y_test))
plot_decision_regions(X_combined_std,y_combined,classifier=lr, test_idx=range(105,150))
plt.xlabel('petal length [standardized]')
plt.ylabel('petal width [standardized]')
plt.legend(loc='upper left')
plt.show()
#后边为个人修改的代码
#---------------------------------------------------------------------------#
#模型训练集,分类错误的个数
y_pred = lr.predict(X_train_std)
print('模型分类错误个数:%d'%(y_train!=y_pred).sum())
#输出所有属于各自类别的概率
k = []
for x in range(0,45):
k.append(x)
print (k)
#预测测试集样本属于各自类别的概率
a=lr.predict_proba(X_test_std[k,:])
print(a)
#结果输出到mysql库
from sqlalchemy import create_engine
import tushare as ts
import pandas as pd
a = pd.DataFrame(a)
engine = create_engine('mysql+pymysql://root:root@localhost/jiqixuexi?charset=utf8')
#输出结果存入数据库
a.to_sql('luojihuigui',engine)
####正则化解决过拟合问题
####对于分类中的线性模型
####对于过拟合和欠拟合,最好使用更加复杂的非线性决策边界来阐明
####减小C值可以增加正则化强度,调整C值防止过拟合
#个人看法,分类算法
#查看KNN算法,个人感觉该算法缺点多
#逻辑斯蒂通过正则化避免过拟合,用于线性,很多时候在业务上用于处理客户流失,购买概率
#SVM可用于处理非线性
#决策树,则需通过特征选择及降维避免过拟合,具有极强的解释性
#随机森林不易产生过拟合,无需担心超参值的选择,但解释性没有决策树的强解释性,随机森林可做特征工程,输出变量重要性
#随机森林和决策树不需要特征缩放,在数据归一化和标准化的选择上,大部分机器学习算法标准化更为实用