感知机 MLP 梯度反向传播详细推导
5. 感知机梯度传播推导
- 单一输出感知机
- 多输出感知机
- 链式法则
- MLP 反向传播推导
- 2D 函数优化实例
单一输出感知机


x = torch.randn(1, 10)
w = torch.randn(1, 10, requires_grad=True)
o = torch.sigmoid(x@w.t())
o.shape #torch.Size([1, 1])
loss = F.mse_loss(torch.ones(1, 1), o)
loss.shape #torch.Size([]) scalar
loss.backward()
w.grad #tensor([[ 2.1023e-04, -4.6425e-04, 2.1561e-04,...]])
多输出感知机
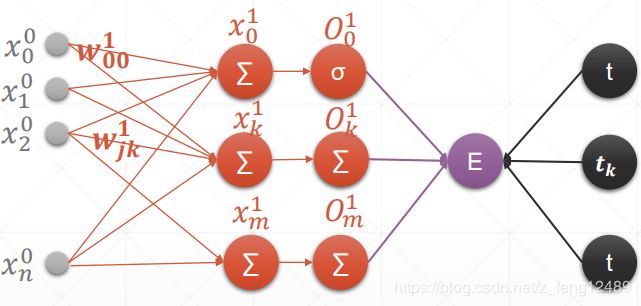

x = torch.rand(1, 10)
w = torch.rand(2, 10, requires_grad=True)
o = torch.sigmoid(x@w.t())
o.shape #torch.Size([1, 2])
loss = F.mse_loss(torch.ones(1,2), o)
loss #tensor(0.0158, grad_fn=)
loss.backward()
w.grad.shape #torch.Size([2, 10])
链式法则
求导法则
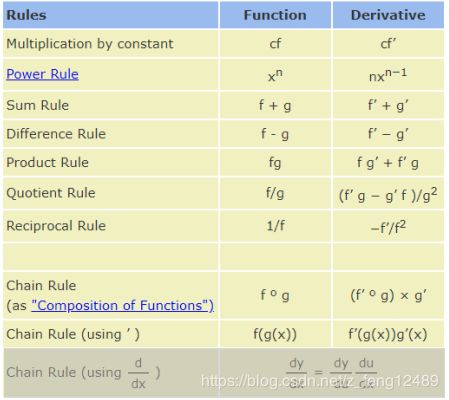
公式
∂ y ∂ x = ∂ y ∂ u ∂ u ∂ x \frac{\partial y}{\partial x} = \frac{\partial y}{\partial u}\frac{\partial u}{\partial x} ∂x∂y=∂u∂y∂x∂u
x = torch.tensor(1.)
w1 = torch.tensor(2., requires_grad=True)
b1 = torch.tensor(1.)
w2 = torch.tensor(2., requires_grad=True)
b2 = torch.tensor(1.)
y1 = x*w1 + b1
y2 = y1*w2 + b2
dy2_dy1 = torch.autograd.grad(y2, y1, retain_graph=True)[0]
dy1_dw1 = torch.autograd.grad(y1, w1, retain_graph=True)[0]
dy2_dw1 = torch.autograd.grad(y2, w1, retain_graph=True)[0]
dy2_dw1, dy2_dy1, dy1_dw1 #tensor(2.) tensor(2.) tensor(1.)
MLP 反向传播推导
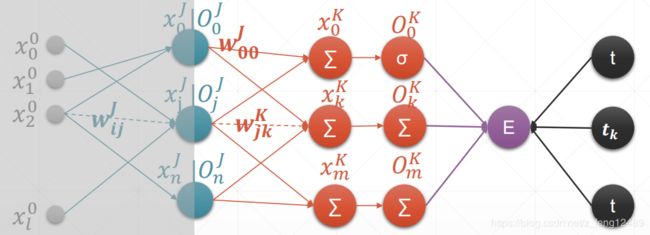

总结:
对 于 一 个 输 出 层 的 节 点 k ∈ K k \in K k∈K:
∂ E ∂ w j k = O j δ k \frac{\partial E}{\partial w_{jk}}=O_j\delta_k ∂wjk∂E=Ojδk
这 里,
δ k = O k ( 1 − O k ) ( O k − t k ) \delta_k=O_k(1-O_k)(O_k-t_k) δk=Ok(1−Ok)(Ok−tk)
对 于 一 个 隐 藏 层 的 节 点 j ∈ J j \in J j∈J:
∂ E ∂ w i j = O i δ j \frac{\partial E}{\partial w_{ij}}=O_i\delta_j ∂wij∂E=Oiδj
这 里,
δ j = O j ( 1 − O j ) ∑ k ∈ K δ k w j k \delta_j=O_j(1-O_j)\sum_{k\in K}\delta_k w_{jk} δj=Oj(1−Oj)k∈K∑δkwjk
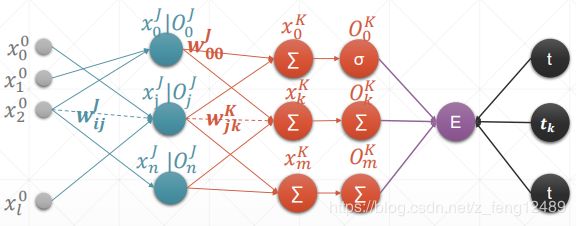
正向传播:
O J − − > O K − − > E O^J~~-->~~O^K~~-->~~E OJ −−> OK −−> E
反向传播:
δ K − − > ∂ E ∂ w K − − > δ J − − > ∂ E ∂ w J − − > δ L − − > ∂ E ∂ w L \delta^K~~-->~~\frac{\partial E}{\partial w^K}~~-->~~\delta^J~~-->~~\frac{\partial E}{\partial w^J}~~-->~~\delta^L~~-->~~\frac{\partial E}{\partial w^L} δK −−> ∂wK∂E −−> δJ −−> ∂wJ∂E −−> δL −−> ∂wL∂E
2D 函数优化实例
f ( x , y ) = ( x 2 + y − 11 ) 2 + ( x + y 2 − 7 ) 2 f(x,y)=(x^2 + y - 11)^2+(x+y^2-7)^2 f(x,y)=(x2+y−11)2+(x+y2−7)2
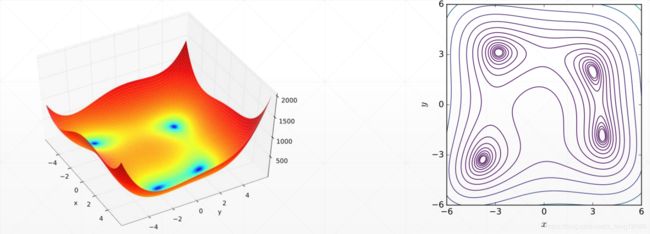
minma:
- f(3,2) = 0
- f(−2.805118,3.131312) = 0
- f(−3.779310,−3.283186) = 0
- f(3.584428,−1.848126) = 0
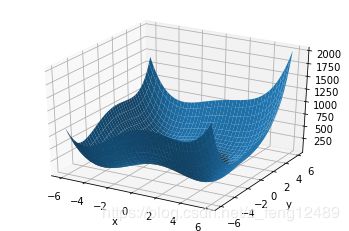
绘图
import numpy as np
import matplotlib.pyplot as plt
def himmelblau(x):
return (x[0]**2+x[1]-11)**2+(x[0]+x[1]**2-7)**2
x = np.arange(-6, 6, 0.1)
y = np.arange(-6, 6, 0.1)
print (x,y range:, x.shape, y.shape)
X, Y = np.meshgrid(x, y)
print (X,Y range:, X.shape, Y.shape)
Z = himmelblau([X,Y])
fig = plt.figure(himmelblau)
ax = fig.gca(projection=3d)
ax.plot_surface(X, Y, Z)
#ax.view_init(60, -30)
ax.set_xlabel(x)
ax.set_ylabel(y)
plt.show()
优化
import torch
x = torch.tensor([0., 0.], requires_grad=True)
optimizer = torch.optim.Adam([x], lr=1e-3) # 建立梯度更新式 x:=x-grad x
for step in range(20000):
pred = himmelblau(x) #得到预测值
optimizer.zero_grad() #清零梯度值
pred.backward() #得到 x 的梯度
optimizer.step() #更新 x 梯度
if step % 2000 == 0:
print (step : x = , f(x) = .format(step, x.tolist(), pred.item()))