Spark (Python版) 零基础学习笔记(四)—— Spark概览
结合了《Learning Spark: Lightning-Fast Big Data Analysis》和官方2.02版本的Spark Document总结了关于Spark概念性的一些知识。帮助大家对Spark有一个总体上的认知
一、Spark的两个核心概念:
1、RDD:弹性分布式数据集
2、 Shared variables:共享变量
二、Spark组件:
Spark集成了很多组件。Spark的内核是一个计算引擎,用于夸多个worker machines或计算集群调度,分布和监视由很与计算任务组成的应用程序。
Spark紧密集成的优点:
1. 高层组件能够受益于底层的改进。比如Spark内核优化后,它的SQL和ML库也能提升速度。
2. 花费较少。包括部署、维修、测试、支持等的费用。一旦有新的组件加入到Spark栈中,所有使用Spark的机构都能够立即使用这一新的组件。
3. Spark建立的应用能够无缝组合其他的处理模型。比如,你用Spark写一个利用ML算法,不断数据流中接收数据,对数据进行实时分类的程序。与此同时,分析师能够通过SQL对同样的数据进行实时的查询操作。此外,数据工程师和数据科学家能够通过Python Shell获取同样的书进行不同的分析。
Spark组件介绍:
1. Spark Core:包括Spark的基础功能,比如任务调度组件、内存管理、故障恢复、存储系统交互等。也是定义RDD(Spark最重要的编程概念)的API的所在地。
2. Spark SQL (structured data):处理结构化数据的Spark包,利用SQL可以或者Hive进行数据查询操作。它也支持很多数据源,包括Hive表格,Parquet和JSON。Spark SQL除了给Spark提供了一个SQL接口外,还循序开发者将SQL查询和RDD支持的可编程数据操作混合使用,从而进行更加复杂的分析。
3. Spark Streaming (real-time):是一个能够处理实时数据流的Spark组件。数据流包括生产Web服务器产生的日志文件、web服务的用户发布的状态更新的信息。Spark Streaming提供了一个操作数据流的API,它与RDD API十分接近。API的底层设计能够提供与Spark Core同等程度的容错、吞吐量和扩展支持。
4. Mlib (machine learning):提供了多种机器学习算法,包括分类、回归、聚类、协同过滤、模型评价和数据导入等等。也提供了ML的一些底层的处理,比如通用梯度下降优化算法。这些算法都能够夸集群扩展。
5. GraphX (processing):用于处理图像(比如社交网络的朋友关系图)和进行图形并行计算的库。与Spark Streaming和Spark SQL类似,GraphX也是Spark RDD API的扩展,允许我们创建一个有向图,并给每个节点和边任意设定属性。GraphX也提供了丰富的图像处理算子(例如subgraph和mapVertices)和常见的图像算法库(例如PageRank和triangle counting)。
Spark能够在很多集群管理器上运行,包括Hadoop YARN,Apache Mesos,和简单的集群管理器,包括Spark自己的Standalone Scheduler。
Core Spark概念
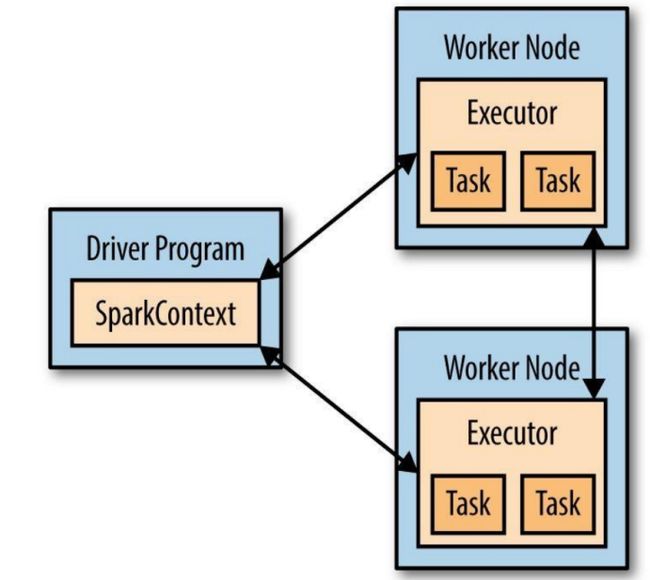
每个Spark应用都含有一个驱动程序,它将并行操作投放到集群上。该驱动程序包括Spark应用的main主函数,在集群上定义分布式数据集,并将其上实施各种操作。Spark shell本身就是一个驱动程序,因此我们能够在shell中直接实施各种操作。如下图所示。
三、初始化Spark
编写Spark程序首先要做的一件事是创建一个SparkContext对象,这个对象是告诉Spark如何访问一个集群的。在创建SparkContext之前,需要先创建一个SparkConf对象,它包含了spark应用的信息。
conf = SparkConf().setAppName(appName).setMaster(master)
sc = SparkContext(conf=conf)
其中,
appName: 应用的名字,会在集群的UI上显示
master:是一个Spark或者Mesos或者YARN集群的URL,也可以是一个指示本地地址的string。
实际应用中,当在一个集群上运行程序时,我们一般并不愿意在程序中将master写死,而是希望通过spark-submit将应用程序启动的时候传递它。但在本地测试过程中可以使用local测试Spark。
3.1. 使用Shell
在Pyspark shell中,已经存在一个专有的解释器可识别的SparkContext,叫做sc。如果再创建自己的SparkContext就无法工作。可以利用–matser命令设置Spark将要连接的集群。可用利用–py-files语句将Python的.zip,.egg或.py文件添加到runtime path,如果有多个文件,用逗号隔开。也可以通过在–packages语句和maven在shell会话中添加依赖(例如SparkPackages)。任何附加的可能存在依赖的代码库(例如SonaType)都可以用过–repositories语句添加。任何Spark Packages中存在的Python以来都必须通过pip命令手动安装。下面举几个例子,在4个核上运行bin/pyspark:
./bin/pyspark–masterlocal[4]或者将code.py加入到搜索路径(便于后边使用importcode),利用下面的语句实现: /bin/pyspark –master local[4] –py-files code.py
如需查看pyspark的所有操作,可以执行pyspark –help命令。事实上,pyspark调用了更加通用的spark -submit脚本。
在IPython中也可以启动PySpark会话,PySpark能够在IPython 1.0.0以上版本上运行。如果要使用IPython,将变量PYSPARK_DRIVER_PYTHON设置为ipython就可以了。
PYSPARKDRIVERPYTHON=ipython./bin/pyspark类似的,如果要使用Jupyter,设置为: PYSPARK_DRIVER_PYTHON=jupyter ./bin/pyspark
四、弹性分布式数据集RDDs
两种方法可以创建RDD:
(1)在现存的驱动程序中并行化集合
(2)引用一个外部存储系统中的数据集,例如共享文件系统,HDFS,HBase或者其他Hadoop输入格式的数据源
4.1. 并行化集合
并行化集合通过在已有的可迭代对象挥着集合上调用SparkContext中的parallelize实现。集合中的元素被拷贝后构成一个能够进行并行操作的分布式数据集。例如创建一个包含数字1-5的并行化集合:
data = [1, 2, 3, 4, 5]
distData = sc.parallelize(data)
并行化的一个重要参数是并行的分区数目。Spark在集群的每个分区上运行一个任务。一般来说,一个CPU一般会分2-4个分区。通常,Spark会根据集群自动设置分区的数目。但也可以进行人为设置,通过设置sc.parallelize的第二个参数实现。注意,有些地方使用分片这个术语(等同于分片)来维护反向兼容性。
4.2. 外部数据集
Spark可以从Hadoop支持的其他存储单元创建分布式数据集,包括本地文件系统,HDFS,Cassandra,HBase,Amazon S3等等。Spark支持文本文件,文件队列和其他Hadoop输入格式。
文本文件RDD能够通过SparkContext的textFile方法创建。该方法给每个文件一个URI(一个计算机的本地地址,或是hdfs://,s3n://等URI),将文件作为行的集合读入。例如:
>>> distFile = sc.textFile(“data.txt”)创建后,distFile可以通过数据集的操作进行很多活动。比如,计算文件中的总行数可以通map和reduce操作实现:distFile.map(lambda s: len(s)).reduce(lambda a, b: a+b).
Spark读取文件的注意事项:
(1)如果使用本地文件系统的路径,那么该文件也必须能够被其他工作节点获取。或者将文件拷贝到每个工作节点,或者使用安装在网络上的共享文件系统。
(2)textFile方法通过设置第二个参数能够控制文件的分区数目。默认情况下,Spark为文件的每个block(HDFS默认一个block的大小为64MB)创建一个分区,但是可以通过设定参数获得更多的分区数目。注意,分区数目不能少于block的数目。
除了文本文件,Spark的Python API也支持其他一些数据格式:
(1)SparkContext.wholeTextFiles:能够读取包含多个小的文本文件的字典,并返回每个(文件名filenames,内容content)对。这与textFile不同,textFile返回的是每个文件中每行的一个记录。
(2)RDD.saveAsPickleFile和SparkContext.pickleFile支持将RDD以一种简单的格式保存,这种格式由被pickle的python对象组成。批处理被用来进行pickle序列化,默认的大小为10。
(3)文件队列和Hadoop输入/输出格式。
注意:以上特性目前仍处于实验状态,主要针对高级用户。未来,也可能被给予Spark SQL的read/write支持所替代,因为Spark SQL的方法更为人偏爱。
Writable支持
PySpark把Java键值对组成的RDD载入文件队列时,将writables转化为Java格式,然后利用Pyrolite将Java对象进行pickle。当把键值对的一个RDD存入文件队列时,PySpark会进行一系列相反的操作。它会把Python对象unpickle成Java对象,并将它们转化为writables。下列Writables能够进行自动转换:
| Writable Type | Python Type |
|---|---|
| Text | Unicode str |
| IntWritable | int |
| FloatWritable | float |
| DoubleWritable | float |
| BooleanWritable | bool |
| BytesWritable | bytearray |
| NullWritable | None |
| MapWritable | dict |
比较意外的是,array类型并不支持。在读写时,用户需要专门指定用户的ArrayWritable子类型还需要。在写入时,用户还需要指定转换器将array转换成ArrayWritable子类型。在读取时,默认的转换器能够将ArrayWritable子类型转换成Java的Object[],然后被pickle成配Python元组(tuples)。
保存和载入文件队列
与文本文件相似,文件队列能够以特定的路径进行保存和载入操作。对于key和value类需要被特别说明,但对于标准的Writables并不需要。
>>> rdd = sc.parallelize(range(1, 4).map(lambda x: (x, "a"*x)))
>>> rdd.saveAsSequenceFile("path/to/file")
>>> sorted(sc.sequenceFile("path/to/file").collect())
[(1, 'a'), (2, 'aa'), (3, 'aaa')]保存和载入其他Hadoop输入输出格式
对于新旧版本的Hadoop Mapreduce API, Spark都支持任何Hadoop输入格式的读取和输出格式的写入。如果需要,Hadoop布局能够以Python字典的形式传递。